
[AI 开发] 基于 DeepStream 的视频结构化解决方案
视频结构化的定义
利用深度学习技术实时分析视频中有价值的内容,并输出结构化数据。相比数据库中每条结构化数据记录,视频、图片、音频等属于非结构化数据,计算机程序不能直接识别非结构化数据,因此需要先将这些数据转换成有结构格式,用于后续计算机程序分析。视频结构化最常见的流程为:目标检测、目标分类(属性识别)、目标跟踪、目标行为分析。最后的目标行为分析严格来讲不属于视频结构化的范畴,可以算作前面每个环节结果的应用。由于现实生产过程中,一个完整的应用系统总会存在“目标行为分析”这个过程(否则光得到基础数据不能加以利用),所以本篇文章将其包含进来。
目标检测
对单张图片中感兴趣的目标进行识别、定位,注意两点,一个是检测的对象是静态图片,二是不但需要识别目标的类别,还需要给出目标在原图片中的坐标值,通常以(left, top, width, height)的形式给出。注意目标检测仅仅给出目标大概位置坐标(一个矩形区域),它跟图像分割不同,后者定位更加具体,能够给出图片中单个目标的轮廓边界。
目标分类(属性识别)
通常目标被检测出来之后,会进行二次(多次)推理,识别出目标更加具体的属性,比如小轿车的颜色、车牌子奥迪还是奔驰等等。对于人来讲,可以二次推理出人的性别、年龄、穿着、发型等等外貌属性。这个环节主要对检测出来的目标进行更加具体的属性识别。
目标跟踪
前面两个环节操作的对象是静态单张图片,而视频有时序性,前后两帧中的目标有关联关系。目标跟踪就是为了将视频第N帧中的目标和第N+1帧中的同一目标关联起来,通常做法是给它们赋予同一个ID。经过目标跟踪环节后,理论情况下,一个目标从进入视频检测范围到离开,算法赋予该目标的ID固定不变。但是现实生产过程中,由于各种原因,比如目标被遮挡、目标漏检(第N帧检测到,第N+1帧没检测到)、跟踪算法自身准确性等等原因,系统并不能锁定视频中同一个目标的ID。目标ID不能锁定,会造成目标行为分析不准的问题,后面会提到。
目标行为分析
视频中目标被跟踪到,赋予唯一ID之后,我们可以记录目标在视频检测范内的运动轨迹(二维坐标点集合),通过分析目标轨迹点数据,我们可以做很多应用。比如目标是否跨域指定区域、目标运动方向、目标运动速度、目标是否逗留(逗留时长)、目标是否密集等等。该应用多存在于安防、交通视频分析领域。
目标检测算法
常见基于深度学习神经网络的目标检测算法有3种,SSD、YOLO以及Faster-RCNN,具体请搜索网络,介绍文章非常多了。三者各有优劣,遵循一个原则:速度快的准确性不好,很多目标检测不准,很多小目标检测不到、容易漏检等;准确性好的速度不快,可能达不到实时检测的要求,或者需要更高的硬件条件。鱼和熊掌不可兼得,牺牲速度可以换来准确性。这三种常见目标检测算法,综合性比较好的是YOLO(现在已经是YOLO V3版本),准确性、小目标检测、检测速度上都可以接受。SSD速度快,我在RTX 2080 的GPU上,能够检测32路1080P高清实时流,但是YOLO V3勉强可以跑到16路。Faster-RCNN准确性更好,但是速度太慢,如果你有很好的GPU硬件支持,或者单台服务器要求检测视频路数比较少,可以采用Faster-RCNN。下图第一张是SSD算法效果,第二张是YOLO V3的算法效果,两者模型都是采用同样的数据集训练而成,可以很明显看到,后者比前者效果好很多(忽略图中速度值)。
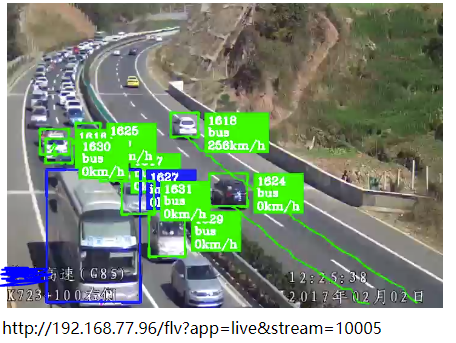
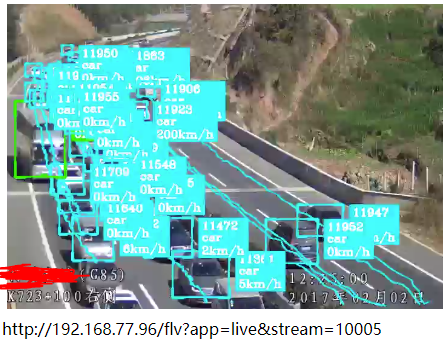
需要注意的是,不管是何种算法,它们的检测效果受数据集质量影响非常大,数据集数量不够、标注质量不高,都会严重影响最终检测结果。做深度学习应用型系统,数据集的重要性非常明显。
视频结构化处理流程框架
前面说到过,视频结构化包含多个环节,各个环节相连而成,形成一个Pipeline的结构。在实际生产过程中,我们还需要有视频流接入的环节,它负责接收视频流数据,由于网络接收到的视频数据是编码过后的格式,我们还需要解码的环节,将原始视频数据解码成一张张RGB格式的图片(这之前可能还需要颜色空间转换,将YUV格式转换成RGB),之后将单帧图片送给推理模型进行推理,返回推理结果。
很明显,视频结构化是一个数据流式的处理过程,如果对GStreamer框架比较熟悉的人可能或想到,GStreamer非常适合做这件事情。这里是GStreamer的官网:https://gstreamer.freedesktop.org/,跟FFmpeg类似,它主要用于音视频多媒体程序开发,但是两个侧重点不同,GStreamer中将多媒体处理流程中的每个环节都封装成单个的插件,每个插件负责不同的任务,比如有接收视频流的、有负责编解码的、有颜色空间转换的等等,这些常用插件都已经有现成非常成熟的,不需要自己开发。插件和插件之间通过某个协议进行连接,最终形成一个完整的Pipeline。目前来看,使用FFmpeg的人明显多余GStreamer。在我们这个应用场景中,GStreamer非常适合我们,Nvidia官方推出的智能视频分析SDK DeepStream也是基于GStreamer开发而成,Nvidia为我们准备好了现成的插件,有负责推理的,有负责目标跟踪的,还有负责图片叠加和显示的。我们在使用DeepStream的同时,也可以使用GStreamer中已有的其他插件,他们可以无缝集成,非常方便。
这里必须要提一下,GStreamer是C语言开发的,而我们知道C语言并非面向对象,如果要用到面向对象的特性必须采取其他措施,GStreamer就是使用了GObject那一套东西,GObject又是什么呢?它是一套在C中使用面向对象编程的规范。如果已经非常熟悉主流面向对象语言的人,再去接收GObject这种编程风格,会要疯掉,反人类(我这样觉得)。下图是采用DeepStream SDK开发视频结构化的Pipeline,简单示意,并非真实生产中的结构:
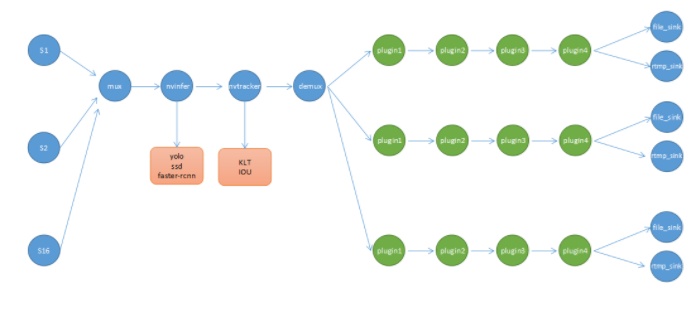
使用DeepStream 做视频结构化应用的好处
如果你用的推理硬件是Nvidia出的,比如Tesla系列显卡、Geforce系列显卡等等,那么使用DeepStream SDK的好处有:
(1)内置推理加速插件nvinfer,注意普通深度学习模型(caffe、tensorflow等)在没有经过tensorRT加速之前,速度是上不来的。而DeepStream内置的nvinfer推理插件不断支持各种目标检测算法(SSD、YOLO、Faster-RCNN)以及各种深度学习框架模型(自由切换),内部还自带tensorRT INT8/FP16加速功能,不需要你做额外操作;
(2)内置目标跟踪插件nvtracker,目前DeepStream 3.0提供两种跟踪算法,一种基于IOU的,这种算法简单,但是快;另外一种KLT算法,准确但是相对来讲慢一些,而且由于这个算法是跑在CPU上,基于KLT的跟踪算法对CPU占用相对大一些;
(3)内置其他比较有用的插件,比如用于视频叠加(目标方框叠加到视频中)的nvosd、硬件加速解码插件nvdec_h264,专门采用GPU加速的解码插件,还有其他颜色转换的插件。
(4)提供跟视频处理有关的各种元数据类型以及API,方便你扩展自己的元数据类型,元数据在GStreamer中是一个很重要的概念。
使用DeepStream SDK的前提是要先掌握GStreamer的基本用法,否则就是抓瞎,前者其实就是后者的一堆插件集合,方便供你构建视频推理Pipeline。当然,你还需要一些CUDA编程的基础知识。
下面提供一个基于YOLO V3 16路1080P高清视频实时目标检测、跟踪、叠加、目标行为判断、结构化数据上报 应用系统截图(截取其中4路图像),由于某些原因,不再做过多的技术细节介绍了。
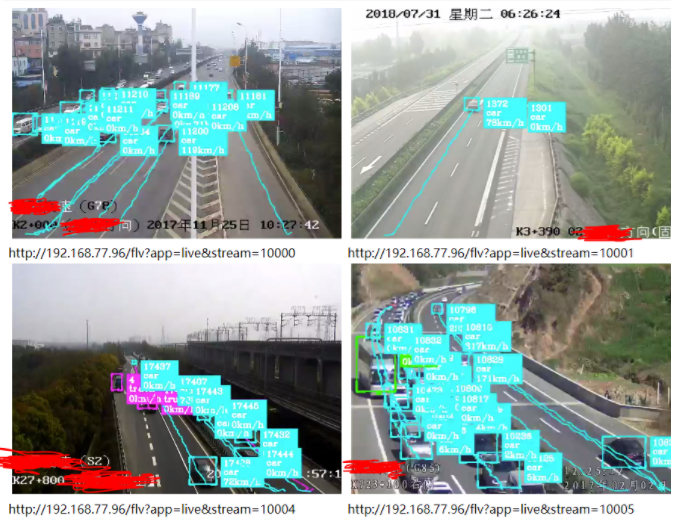
作者:周见智
出处:http://www.cnblogs.com/xiaozhi_5638/
原文链接:https://www.cnblogs.com/xiaozhi_5638/p/10831459.html
本文转自博客园网,版权归原作者所有。