
Flink CDC 系列 - 实时抽取 Oracle 数据,排雷和调优实践
浪尖聊大数据
共 7639字,需浏览 16分钟
·
2022-01-04 13:33
Flink CDC
https://ververica.github.io/flink-cdc-connectors/release-2.1/content/connectors/oracle-cdc.html
Debezium
https://debezium.io/documentation/reference/1.5/connectors/oracle.html
一、无法连接数据库
create table TEST (A string)WITH ('connector'='oracle-cdc','hostname'='10.230.179.125','port'='1521','username'='myname','password'='***','database-name'='MY_SERVICE_NAME','schema-name'='MY_SCHEMA','table-name'='TEST' );
[ERROR] Could not execute SQL statement. Reason:oracle.net.ns.NetException: Listener refused the connection with the following error:ORA-12505, TNS:listener does not currently know of SID given in connect descriptor
public static Connection openConnection(Properties properties) throws SQLException {DriverManager.registerDriver(new oracle.jdbc.OracleDriver());String hostname = properties.getProperty("database.hostname");String port = properties.getProperty("database.port");String dbname = properties.getProperty("database.dbname");String userName = properties.getProperty("database.user");String userpwd = properties.getProperty("database.password");return DriverManager.getConnection("jdbc:oracle:thin:@" + hostname + ":" + port + ":" + dbname, userName, userpwd);}
在 Flink CDC 的 create table 语句中,将 database-name 由 Service Name 替换成其中一个 SID。该方式能解决连接问题,但无法适应主流的 Oracle 集群部署的真实场景; 对该源码进行修改。具体可在新建工程中,重写 com.ververica.cdc.connectors.oracle.OracleValidator 方法,修改为 Service Name 的连接方式 (即 port 和 dbname 中间使用 “ / ” 分隔开),即: "jdbc:oracle:thin:@" + hostname + ":" + port + "/" + dbname, userName, userpwd);
该问题已提交至 Flink CDC Issue 701: https://github.com/ververica/flink-cdc-connectors/issues/701
二、无法找到 Oracle 表
[ERROR] Could not execute SQL statement. Reason:io.debezium.DebeziumException: Supplemental logging not configured for table MY_SERVICE_NAME.MY_SCHEMA.test. Use command: ALTER TABLE MY_SCHEMA.test ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS
private TableId toLowerCaseIfNeeded(TableId tableId) {return tableIdCaseInsensitive ? tableId.toLowercase() : tableId;}
见 https://docs.oracle.com/cd/E11882_01/server.112/e41084/sql_elements008.htm “Nonquoted identifiers are not case sensitive. Oracle interprets them as uppercase”
如需使用 Oracle “大小写不敏感” 的特性,可直接修改源码,将上述 toLowercase 修改为 toUppercase (这也是笔者选择的方法); 如果不愿意修改源码,且无需使用 Oracle “大小写不敏感” 的特性,可以在 create 语句中加上 'debezium.database.tablename.case.insensitive'='false',如下示例:
create table TEST (A string)WITH ('connector'='oracle-cdc','hostname'='10.230.179.125','port'='1521','username'='myname','password'='***','database-name'='MY_SERVICE_NAME','schema-name'='MY_SCHEMA','table-name'='TEST','debezium.database.tablename.case.insensitive'='false' );
该问题已提交至 Flink CDC Issue 702: https://github.com/ververica/flink-cdc-connectors/issues/702
三、数据延迟较大
'debezium.log.mining.strategy'='online_catalog','debezium.log.mining.continuous.mine'='true'
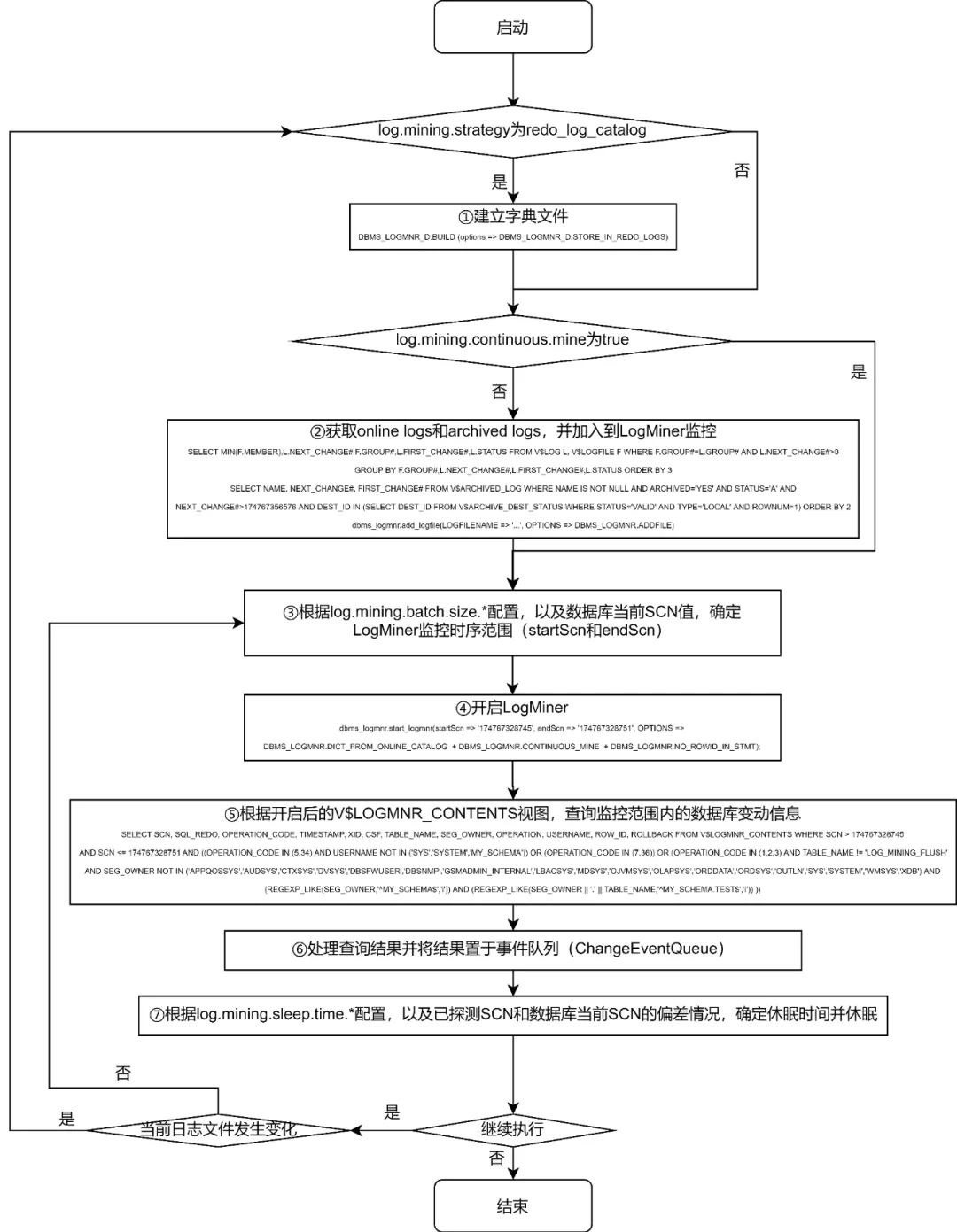
ORA-00308: cannot open archive log '/path/to/archive/log/...'ORA-27037: unable to obtain file status
四、调节参数继续降低数据延迟
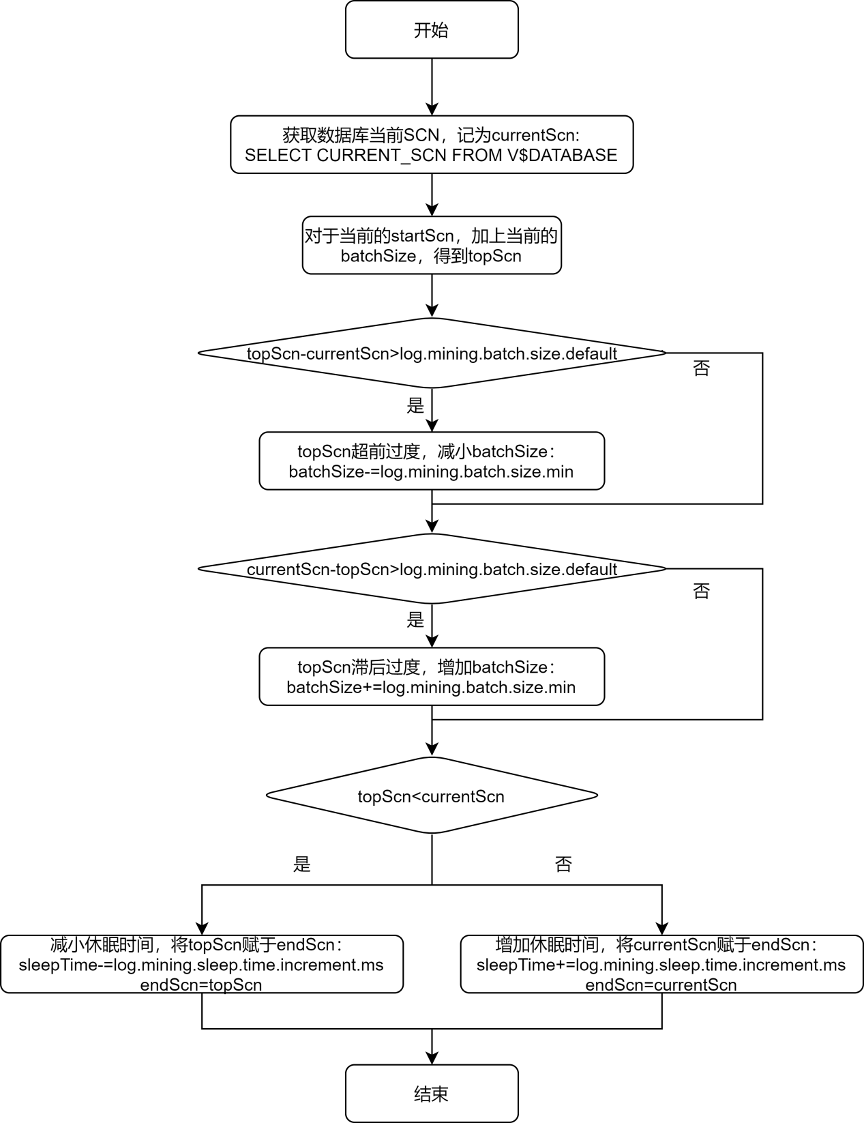
从上述的流程图中可以看出,debezium 给出 log.mining.batch.size.* 和 log.mining.sleep.time.* 两组参数,就是为了让每一次 logMiner 运行的步长能够尽可能和数据库自身 SCN 增加的步长一致。由此可见:
log.mining.batch.size.* 和 log.mining.sleep.time.* 参数的设定,和数据库整体的表现有关,和单个表的数据变化情况无关; log.mining.batch.size.default 不仅仅是监控时序范围的起始值,还是监控时序范围变化的阈值。所以如果要实现更灵活的监控时序范围调整,可考虑适当减小该参数; 由于每一次确定监控时序范围时,都会根据 topScn 和 currentScn 的大小来调整 sleepTime,所以为了实现休眠时间更灵活的调整,可考虑适当增大 log.mining.sleep.time.increment.ms; log.mining.batch.size.max 不能过小,否则会有监控时序范围永远无法追上数据库当前 SCN 的风险。为此,debezium 在 io.debezium.connector.oracle.OracleStreamingChangeEventSourceMetrics 中存在以下逻辑:
if (currentBatchSize == batchSizeMax) {LOGGER.info("LogMiner is now using the maximum batch size {}. This could be indicative of large SCN gaps", currentBatchSize);}
五、Debezium Oracle Connector
的隐藏参数
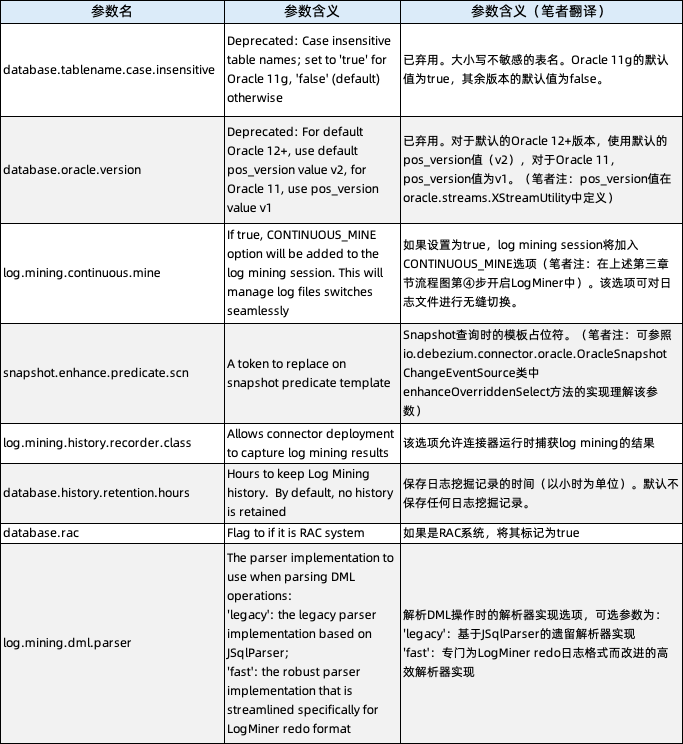
所以我们在分析 Flink CDC 行为时,通过自定义实现 io.debezium.connector.oracle.logminer.HistoryRecorder 接口的类,可在不修改源码的情况下,实现对 Flink CDC 行为的个性化监控。
Flink-CDC 项目地址:
https://github.com/ververica/flink-cdc-connectors
评论