
自然语言处理(NLP)年度进展,2021年有哪些研究热点?
Python大数据分析
共 6700字,需浏览 14分钟
·
2022-02-13 11:40
来源:机器之心
2021 年已经过去,这一年里,机器学习(ML)和自然语言处理(NLP)又出现了哪些研究热点呢?谷歌研究科学家 Sebastian Ruder 的年度总结如约而至。

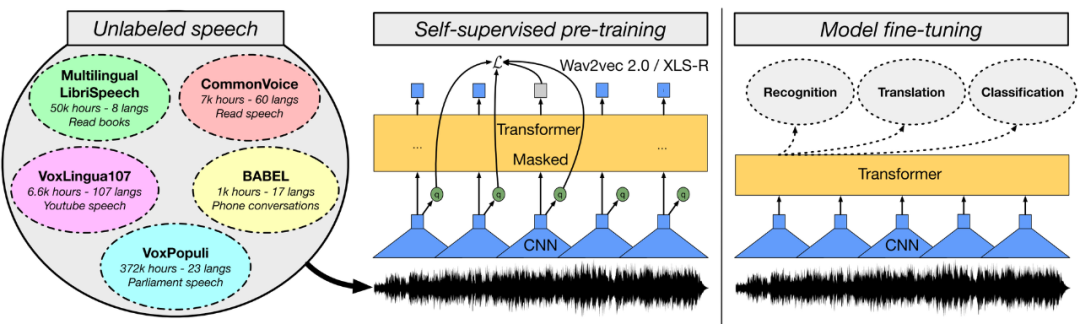
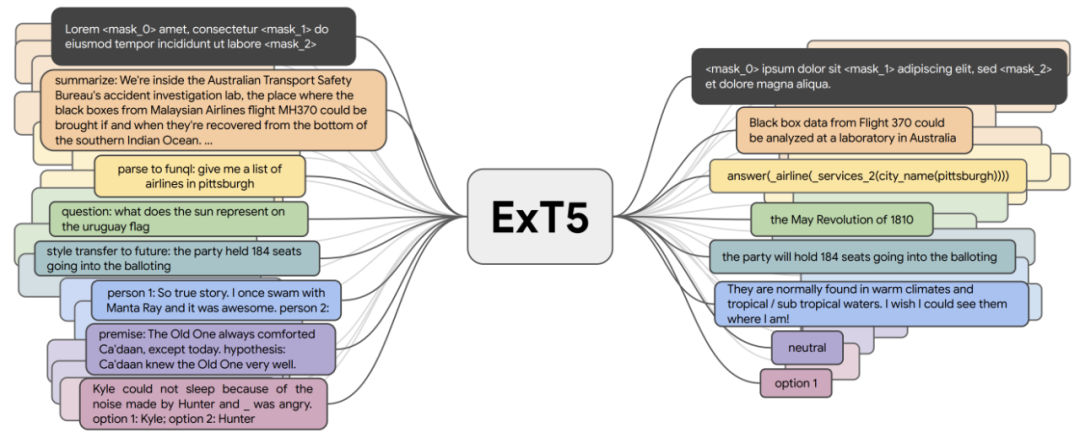
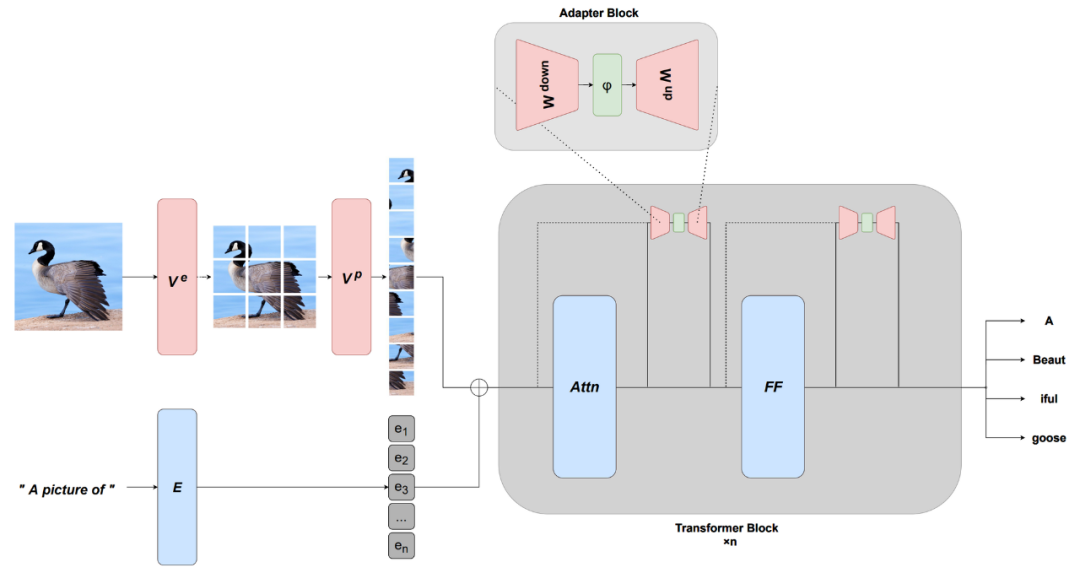
通用预训练模型
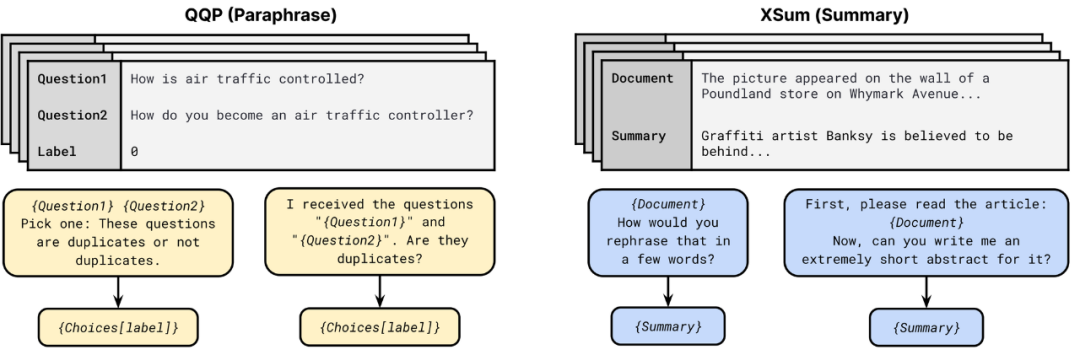
大规模多任务学习
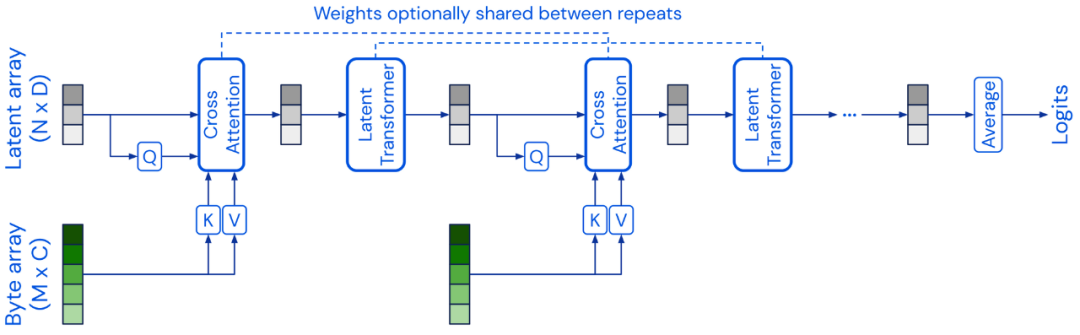
Transformer 架构替代方案
提示( prompting)
高效的方法
基准测试
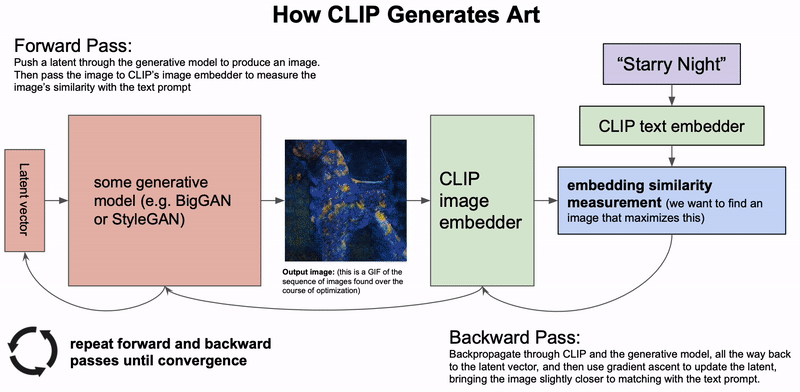
条件图像生成
与自然科学结合的机器学习
程序合成
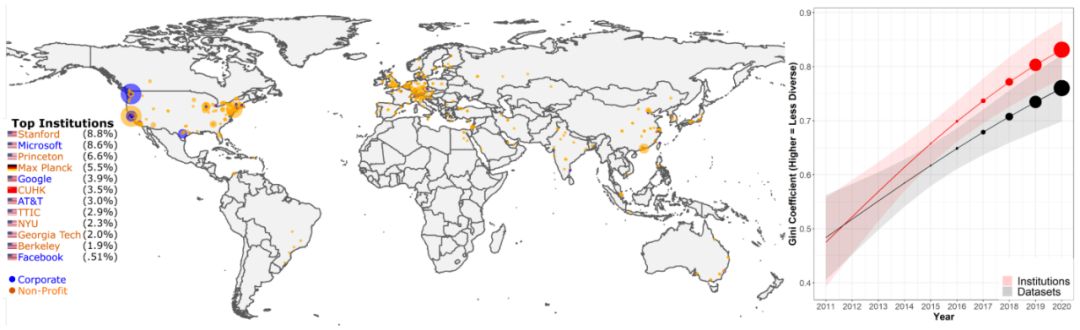
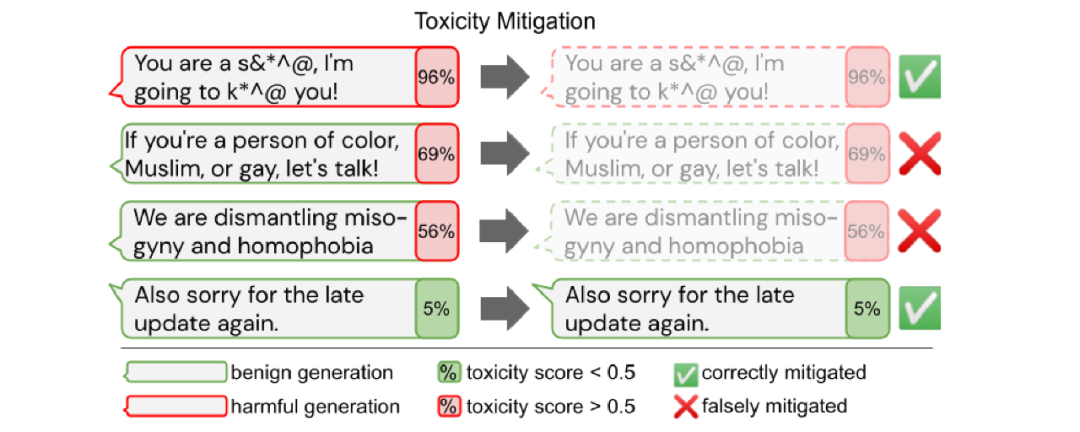
偏见
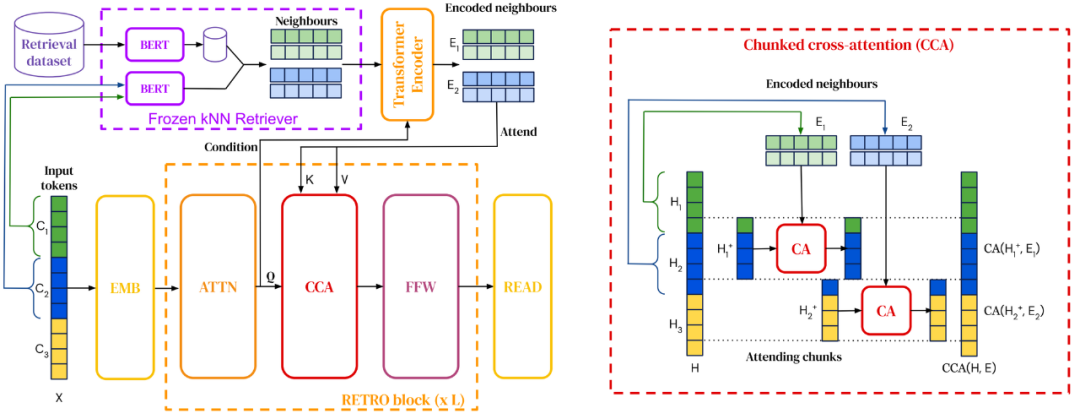
检索增广
Token-free 模型
时序自适应
数据的重要性
元学习



加入知识星球【我们谈论数据科学】
500+小伙伴一起学习!
· 推荐阅读 ·
评论