
本周优秀开源项目分享,pytorch 人脸识别、场景文字检测Python 包 等8大项目
共 4284字,需浏览 9分钟
·
2020-08-20 20:43
cnstd 基于 MXNet 的场景文字检测(Scene Text Detection)Python 包
cnstd 是 Python 3 下的场景文字检测(Scene Text Detection,简称STD)工具包,自带了多个训练好的检测模型,安装后即可直接使用。
当前的文字检测模型使用的是 PSENet,目前支持两种 backbone 模型:mobilenetv3 和 resnet50_v1b。
它们都是在 ICPR 和 ICDAR15 的 11000 张训练集图片上训练得到的。
如需要识别文本框中的文字,可以结合 OCR 工具包 cnocr 一起使用。

已有模型:
当前的文字检测模型使用的是PSENet,目前包含两个已训练好的模型,分别对应两种backbone模型:mobilenetv3 和 resnet50_v1b。它们都是在ICPR和ICDAR15训练数据上训练得到的。

项目地址:
https://github.com/breezedeus/cnstd
text_scalpel 文本复述任务,用于NLP语料的数据增强
文本复述任务是指把一句/段文本A改写成文本B,要求文本B采用与文本A略有差异的表述方式来表达与之意思相近的文本。
改进谷歌的LaserTagger模型,使用LCQMC等中文语料训练文本复述模型,即修改一段文本并保持原有语义。
复述的结果可用于数据增强,文本泛化,从而增加特定场景的语料规模,提高模型泛化能力。
谷歌在文献《Encode, Tag, Realize: High-Precision Text Editing》中采用序列标注的框架进行文本编辑,在文本拆分和自动摘要任务上取得了最佳效果。
在同样采用BERT作为编码器的条件下,本方法相比于Seq2Seq的方法具有更高的可靠度,更快的训练和推理效率,且在语料规模较小的情况下优势更明显。
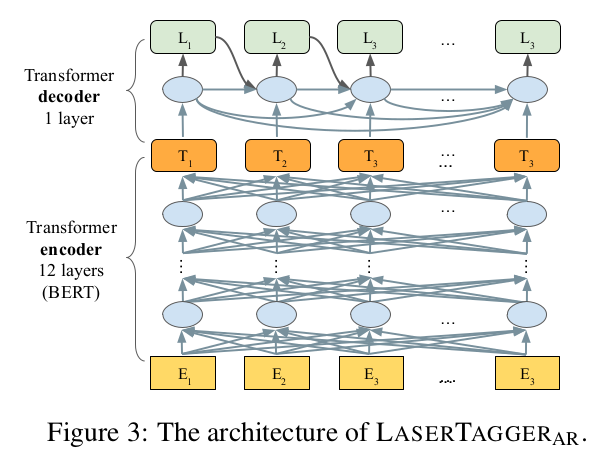
谷歌公开了本文献对应的代码,但是原有任务与当前任务有一定的差异性,需要修改部分代码,主要修改如下:
A.分词方式:原代码针对英文,以空格为间隔分成若干词。现在针对中文,分成若干字。
B.推理效率:原代码每次只对一个文本进行复述,改成每次对batch_size个文本进行复述,推理效率提高6倍。
项目地址:
https://github.com/Mleader2/text_scalpel
pretrained_models_and_embeddings 预训练模型与嵌入
这个项目是从BAAI和JDAI的联合实验室发布一些开源自然语言模型。与其他开源中文NLP模型不同,我们主要关注对话系统的一些基本模型,尤其是在电子商务领域。
我们的语料库非常庞大,目前我们正在使用42 GB的客户服务对话数据(CSDD)进行培训,其中包含约12亿个句子。
我们提供了预训练的BERT和单词嵌入。下图显示了我们使用的数据。

BERT模型:
在进行预训练时,我们使用预处理器进行数据预处理,包括一些泛化处理。
我们使用的初始化检查点是<12层,隐藏768、12头,110M参数>,中文,并且bert_config.json和vocab.txt与Google的原始设置相同。
我们在当前的预培训中不使用中文全字掩蔽(WWM),而是使用中文字符级别的Google原始WWM。
词嵌入:
在进行预训练时,我们使用我们的工具进行预处理和分词。
我们基于Skip-Gram训练向量。
项目地址:
https://github.com/jd-aig/nlp_baai/tree/master/pretrained_models_and_embeddings
TNN:由腾讯优图实验室打造,移动端高性能、轻量级推理框架,同时拥有跨平台、高性能、模型压缩、代码裁剪等众多突出优势。
TNN框架在原有Rapidnet、ncnn框架的基础上进一步加强了移动端设备的支持以及性能优化,同时也借鉴了业界主流开源框架高性能和良好拓展性的优点。
目前TNN已经在手Q、微视、P图等应用中落地,欢迎大家参与协同共建,促进TNN推理框架进一步完善。
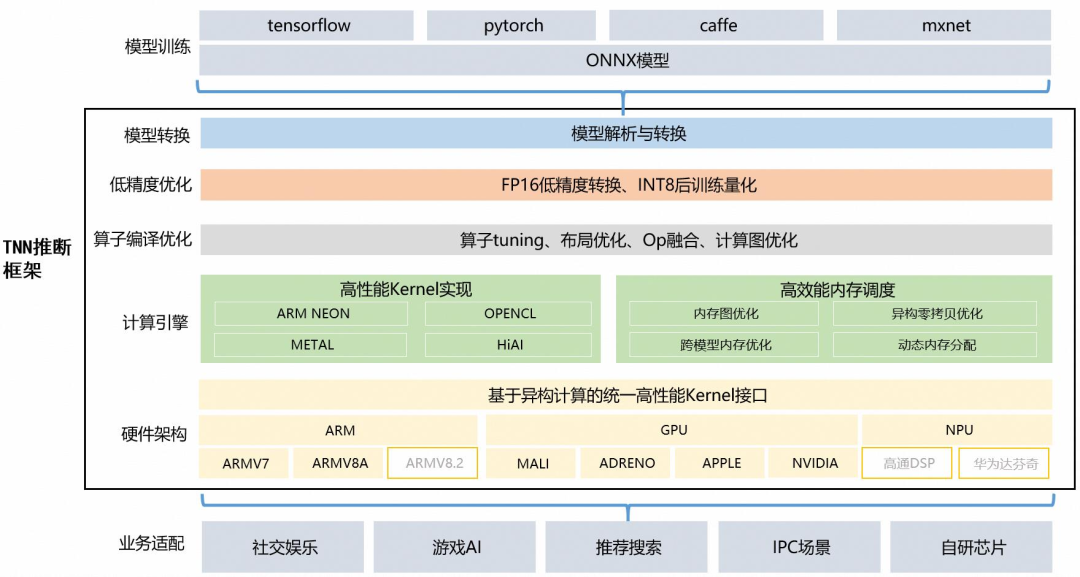
技术方案:
计算优化:
针对不同架构在硬件指令发射、吞吐、延迟、缓存带宽、缓存延迟、寄存器数量等特点,深度优化底层算子,极致利用硬件算力
主流硬件平台(CPU: ARMv7, ARMv8, GPU: Mali, Adreno, Apple) 深度调优
CNN 核心卷积运算通过 Winograd,Tile-GEMM, Direct Conv 等多种算法实现,保证不同参数、计算尺度下高效计算
Op 融合:离线分析网络计算图,多个小 Op(计算量小、功能较简单)融合运算,减少反复内存读取、kernel 启动等开销
低精度优化:
支持 INT8, FP16 低精度计算,减少模型大小、内存消耗,同时利用硬件低精度计算指令加速计算
支持 INT8 Winograd 算法,(输入6bit), 在精度满足要求的情况下,进一步降低模型计算复杂度
支持单模型多种精度混合计算,加速计算同时保证模型精度
内存优化:
高效”内存池”实现:通过 DAG 网络计算图分析,实现无计算依赖的节点间复用内存,降低 90% 内存资源消耗
跨模型内存复用:支持外部实时指定用于网络内存,实现“多个模型,单份内存”
主流模型实测性能:
v0.1 2020.05.29
项目地址:
https://github.com/Tencent/TNN
cavaface.pytorch 人脸识别项目(PyTorch)
此项目为使用pytorch的人脸识别提供了高性能的分布式并行训练框架,包括各种主干(例如ResNet,IR,IR-SE,ResNeXt,AttentionNet-IR-SE,ResNeSt,HRNet等),各种损失(例如,Softmax,Focal,SphereFace,CosFace,AmSoftmax,ArcFace,ArcNegFace,CurricularFace,Li-Arcface,QAMFace等),各种数据扩充(例如,RandomErasing,Mixup,RandAugment,Cutout,CutMix等)和袋装改善性能的技巧(例如FP16培训(顶点),标签平滑,LR预热等)
系统需求:
torch == 1.4.0
torchvision == 0.5.0
tensorboardX == 1.7
bcolz == 1.2.1
Python 3
Apex == 0.1
骨干网络:

损失函数:

并行训练:
数据并行
模型并行
项目地址:
https://github.com/cavalleria/cavaface.pytorch
ShelfNet-Human-Pose-Estimation 使用ShelfNet和PyTorch进行快速准确的人体姿势估计

这个项目目的是找出ShelfNet是否是一种有效的CNN架构,可用于语义分割以外的计算机视觉任务,尤其是用于人体姿势估计任务。
答案是肯定的,MS COCO Keypoints数据集具有74.6 mAP和127 FPS,与HRNet相比,FPS提升了3.5倍,具有类似的准确性。
ShelfNet架构是由J. Zhuang,J。Yang,L。Gu和N. Dvornek通过arXiv上的一篇论文介绍的。本文仅在语义分割任务上评估网络。
作者的贡献是在PASCAL VOC上创建了一种具有与最新技术(发布此存储库时为PSPNet和EncNet)相似的性能的快速架构,并在Cityscapes上获得了更好的性能。
因此,ShelfNet目前是具有资源限制的最适合实际应用程序的体系结构之一。
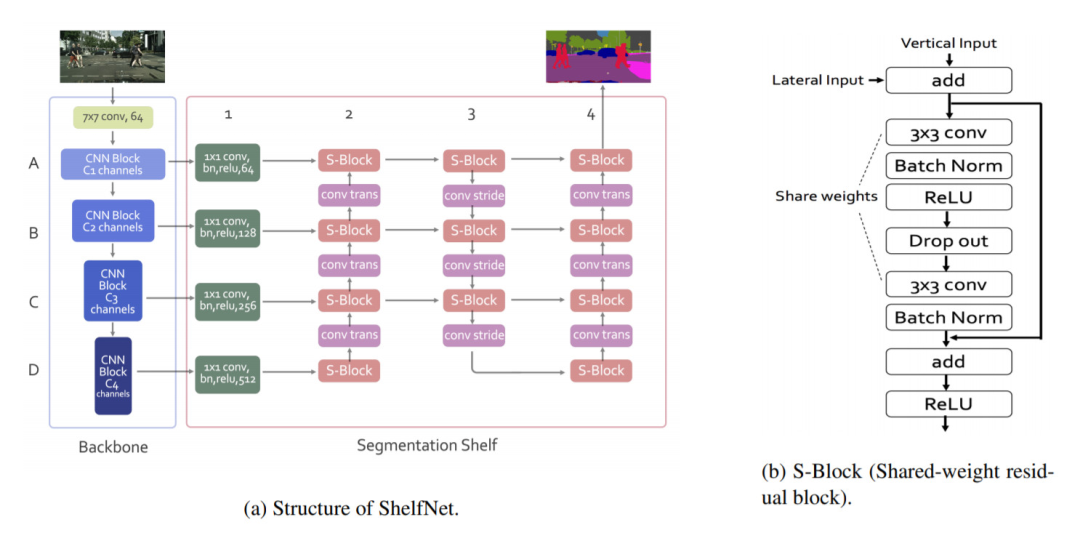
如上所述,ShelfNet使用ResNet主干结合2个编码器/解码器分支。第一个编码器将信道复杂度降低了4倍,以加快推理速度。S块是具有权重的残差块,可显着减少参数数量。
网络使用跨步卷积进行下采样,并使用转置卷积进行上采样。该结构可以看作是FCN的集合,其中信息流经许多不同的路径,从而提高了准确性。
项目地址:
https://github.com/fmahoudeau/ShelfNet-Human-Pose-Estimation
nncf_pytorch 神经网络压缩框架
该项目包含基于PyTorch的框架和用于神经网络压缩的样本。
该框架以Python软件包的形式组织,可以在独立模式下构建和使用。框架架构是统一的,可以轻松添加不同的压缩方法。
这些样本演示了在公共模型和数据集上三个不同用例中压缩算法的用法:图像分类,对象检测和语义分割。在本文档末尾的表格中,可以找到使用NNCF驱动的样本可获得的压缩结果。
关键特征:
在模型微调过程中应用的各种压缩算法的支持,以实现最佳压缩参数和精度
量化、二值化、稀疏性、过滤修剪
自动,可配置的模型图转换以获得压缩模型。源模型由自定义类包装,并且在图形中插入了其他特定于压缩的图层
压缩方法的通用接口
GPU加速层可加快压缩模型的微调
分布式训练支持
每个受支持的压缩算法的配置文件示例
杰出的第三方存储库(mmdetection,havingface-transformers)的Git补丁,展示了将NNCF集成到定制培训管道中的过程
将压缩模型导出到ONNX检查点,以供OpenVIN工具包使用
系统需求:
Ubuntu16.04 或更高版本 (64-bit)
Python 3.6或更高版本
NVidia CUDA Toolkit 10.2 或更高版本
PyTorch 1.5 或更高版本
项目地址:
https://github.com/openvinotoolkit/nncf_pytorch
9.9元秒杀【SVM与XGBoost】第三期特训课,8月24号开课。
SVM部分 全面升级,由七月在线AI lab陈博士亲授,9节课 带你快速掌握SVM与XGBoost理论推导。
并且免费提供2020最新面试题,还有机会获得职业规划老师1V1简历优化、1V1职业规划。
在售价119.9元,限时9.9元秒,扫码抢占名额!(机器学习集训营预习课之一)
参与方式:
扫描上方海报二维码
回复“5”
戳↓↓“阅读原文”查看课程详情!(机器学习集训营预习课)