
业界盘点|Query理解在搜索中的落地技巧
卷友们好,我是rumor。
前阵子我们总结了NLP文本相关性在搜广推的应用,今天我们继续来刷Query理解的落地技巧。
Query理解是搜索引擎中的必备模块,它的主要功能是对Query进行深入理解,保证召回的数量和最终排序精度。系统中的整个理解模块通常被称为QU(Query Understanding)或QP(Query Parser),主要由以下几部分构成:
基础解析:包括预处理、分词、词性识别、实体识别、词权重等多个基础任务 Query改写:包括纠错、扩展、同义替换功能,可以进行扩召回 意图识别:判断Query的具体类目,便于召回和最终排序
下图是腾讯搜索的例子,在实际应用中每家的实现顺序都各有不同,有些子模块也可以是并行的,最终的输出多个处理后的Query进行召回,比如原始Query解析后的倒排索引召回、改写后Query的倒排索引召回、以及向量化召回。
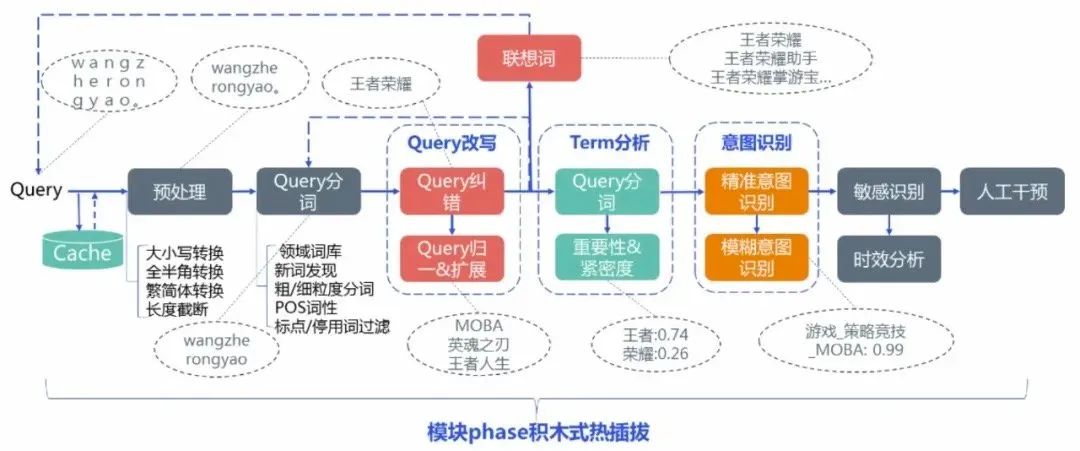
接下来,我们就看看业界的搜索都是怎么对这些模块进行优化的。
基础解析
基础解析包含很多功能,比如腾讯搜索分享的预处理、分词、词性识别,以及去停用词、实体识别和链接、词权重等。
词法分析任务已经有很多开源工具了,本来这个模块对速度的要求就比较高,基本都是采用词表或者很浅的模型来解决。在实际选择工具时,更重要的是考虑工具的效率和可控性,包括:
分词及NER在业务数据的精度、速度 粒度控制:比如“2021日本奥运会直播”可以切成“2021/日本/奥运会/直播”,也可以切成“2021日本奥运会/直播”,用phrase级别召回会比细粒度更准确,但phrase结果不够时还是需要细粒度的结果补充 自定义词典、模型迭代的支持:之前我早年用词向量做检索式问答的时候,遇到的困境就是虽然词表配好了,但如果同时配了“奥运”和“奥运会”,有时候还会切成“奥运/会”,这就需要对模型增量训练,现有工具很多是不支持的 新词发现:因为涉及建立倒排索引,Query和Doc需要用同一套分词。但互联网总是会出现各种新型词汇,这就需要分词模块能够发现新词,或者用更重的模型挖掘新词后加到词典里
除了词法分析之外,还有个比较重要的模块是词权重。比如“女士牙膏”这个Query,“牙膏”明显比“女士”要重要,即使无法召回女士牙膏类的内容,召回牙膏内容也是可以的。
权重可以用分数或分类表达,在计算最终相似度结果时把term weight信息加入召回排序模型中,比如腾讯搜索就给term分成了四类:
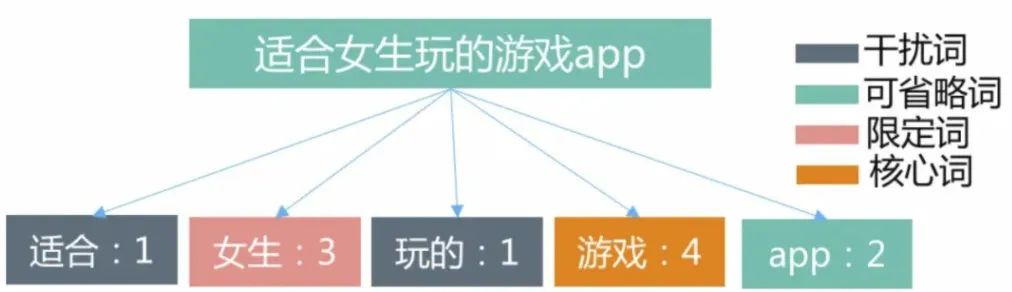
对于Term weighting可以有以下方法:
基于统计+词表:比如根据doc统计出词的tfidf,直接存成词典就行了。但这种方法无法解决OOV,知乎搜索的解决方法是对ngram进行统计,不过ngram仍然无法捕获长距离依赖、不能根据上下文动态调整权重 基于Embedding:针对上下文动态调整的问题,知乎搜索的迭代方案是用term的向量减去query整个的pooling向量来算term权重,diff越小词越重要;腾讯搜索则是用移除term之后的query和原始query的embedding做差值,diff越大词越重要 基于统计模型:用速度更快的统计分类/回归模型同样可以解决上述问题,腾讯搜索采用了term 词性、长度信息、term 数目、位置信息、句法依存 tag、是否数字、是否英文、是否停用词、是否专名实体、是否重要行业词、embedding 模长、删词差异度、前后词互信息、左右邻熵、独立检索占比 ( term 单独作为 query 的 qv / 所有包含 term 的 query 的 qv 和)、iqf、文档 idf、统计概率等特征,来预测term权重。训练语料可以通过query和被点击doc的共现词来制作 基于深度学习模型:腾讯搜索还提出了一种利用其他模型副产物的方式得到term权重,可以解决长距离依赖问题,就是把带有attention机制的意图模型、文本向量化模型的attention矩阵拿出来作为weight。但这种方法个人认为不太可控,毕竟深度模型太过黑盒,有可能换模型之后波动较大
Query改写
Query改写是个很重要的模块,因为用户的输入变化太大了,有短的有长的,还有带错别字的,如果改写成更加规范的query可以很大地提升搜索质量。
改写模块又可以分为纠错、扩展、同义替换等多个功能,这个模块会提前把高频Query都挖掘好,存储成pair对的形式,线上命中后直接替换就可以了,所以能上比较fancy的模型。
纠错
基于Query本身是否有在字典中的词,腾讯搜索把错误分词了Non-word和Real-word两类:

对于不同类错误有不同的解决方案,比如英文、数字、拼音的拼写错误,可以利用编辑距离挖掘出改写的pair;比如拼音汉字混合、漏字、颠倒等可以通过人工pattern生成一批pair。不过更通用的方法还是批量挖掘或生成。
挖掘可以对用户session、点击同一个doc的不同query的行为日志进行统计,计算ngram语言模型的转移概率;也可以直接利用业务语料上预训练的BERT,mask一部分之后得到改写的词。
当有了第一批pair语料后,就可以用seq2seq的方式来做了。这方面可以做的很fancy,有不少论文。
扩展
用户的表述不一定总是精确的,有时候会输入很短的query,或者很模糊的词,改几次才知道自己要什么。扩展则起到了「推荐」的作用,可以对搜索结果进行扩召回、在搜索时进行提示以及推荐相关搜索给用户。目的主要是丰富短query的表达,更好捕捉用户意图。
Query扩展pair的挖掘方式和纠错差不多,可以建模为pair对判别或者seq2seq生成任务。丁香园分别写过两篇扩展模型的总结,这里就不再赘述:
除了用模型发现之外,也可以利用知识图谱技术,将一些候选少的query扩展到上位词,或者某种条件下的相关词,比如把“能泡澡的酒店”改写成“带浴缸的酒店”,普通的相关性扩展不一定能学到这些知识。
同义替换
同义替换的挖掘主要解决query和doc表述不一致的问题。比如“迪士尼”和“迪斯尼”、“理发”和“剪发”,或者英文和中文等,保证能召回到用户想找的item。
同义词的判定标准会更严格一些,除了在行为日志挖掘,也可以在doc中挖到很多同义pair。但这个模块面临的困境是不同垂搜下的标准不一致,比如我们在挖掘教育领域下的同义词时,“游泳”和“游泳培训”就是同义的。对于这个问题一方面可以针对不同领域训练不同模型,但每个领域一个模型不太优雅,所以也可以在语料上做文章,比如加一个统一的后缀,教育领域都变成XX培训,旅游领域都变成XX的地方。
意图识别
意图识别模块通常是一个分类任务,目的是识别用户要查询的类目,再输出给召回和排序模块,保证最后结果的类目相关性。
除了明确的名词外,很多query都是模糊的,可能有多个类别满足情况,所以意图模块主要是输出一个类目的概率分布,进行多路召回,让排序层进行汇总。
构建意图分类模型之前,首先是对类目的梳理,因为大厂们的业务越来越复杂,类目也随之越来越多,通常会采用层级式的类目体系,模块先判断大类目,再去判断更细化的类目。
在构建模型时,由于这个模块对速度的要求大于精度,所以一般会有很浅的模型,比如统计方法或者浅层神经网络。在微信和第四范式的分享中都提到说Fasttext的效果就很好了。在浅层模型下要想提升效果,可以增加更多的输入信息,比如微信就提供了很多用户画像的feature:
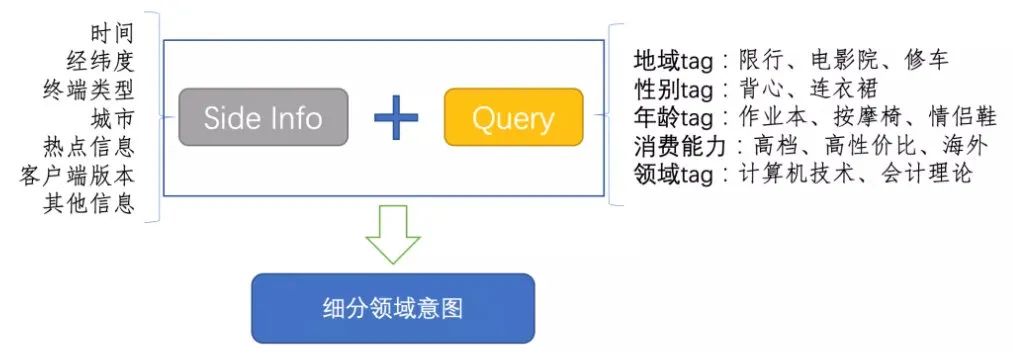
实际上,由于类目层级和数目的增加,光靠一两个模型是很难同时满足速度和精度的,在这个模块少不了词表和pattern的帮助,比如:
查询词语:澳洲[addr]cemony[brand]水乳[product]面霜[sub_product]
查询pattern: [brand]+[product];[addr]+[product]+[sub_product]
总结
虽然NLP只有几个基础任务,但在最终落地时却是很复杂的,一个几十毫秒的Query理解模块包含着这么多逻辑,需要几人甚至十几人的团队来维护,不仅要上高效率的模型,还需要增加各种策略来解决业务问题。
论文刷多了,看一看业界分享也能增加不少脑洞,maybe效果就差在某个feature上面。


「预订用户画像」