
2021科大讯飞-X光安检图像识别赛Top1方案!
大家好,我们是来自浙江啄云智能科技有限公司的GOAT算法团队,团队多年来专注于X光安检领域算法研究。今天给大家分享的是我们团队在2021科大讯飞--X光安检图像识别挑战赛中所做的一些工作,在讯飞2021年的赛事中,这个比赛可以说是竞争最激烈了,前后历时三个多月,我们团队进行了大量实验,最终拿到了复赛第一、决赛第一的成绩。
下面我将从赛题背景、赛题内容分析、解决方案和总结这四个方面进行介绍,欢迎大家在评论区进行交流。
一、赛题背景
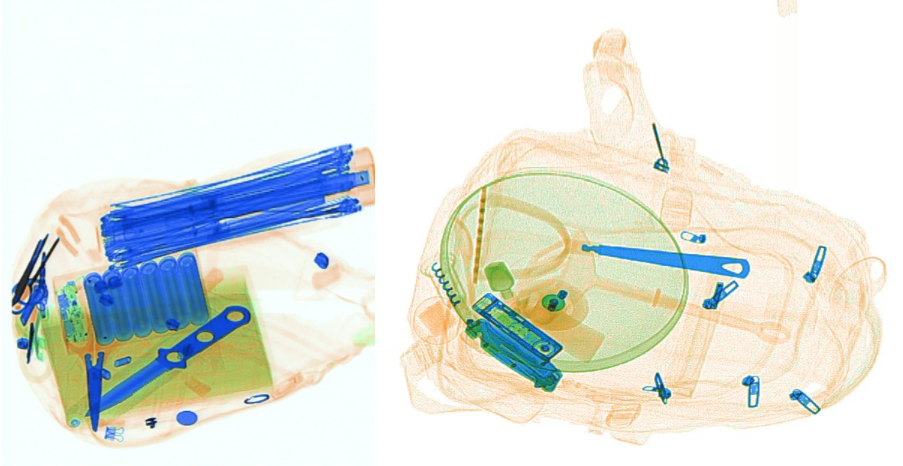
X光安检机是目前我国使用最广泛的安检技术手段,广泛应用于城市轨交、铁路、机场、重点场馆、物流寄递等场景。使用人工智能技术,辅助一线安检员进行X光安检判图,可以有效降低因为人员疲劳或注意力不集中带来的漏报等问题。但在实际场景中,因物品的多样性、成像角度、遮挡等问题,为算法的开发带来了一定的挑战。
赛题链接:
http://challenge.xfyun.cn/topic/info?type=Xray-2021
二、赛题内容及分析
1. 赛题内容
赛题数据组成
初赛:
1)带标注的训练数据,即待识别物品在包裹中的X光图像及其标注文件;
2)不带标注的测试数据;
复赛:
1)无标注训练数据即包裹X光图像(其中有的包裹包含待识别物品);
2)部分待识别物品X光图像(无背景);
目标类别:
刀、剪刀、尖锐工具、甩棍、小玻璃瓶、电棍、塑料饮料瓶、带喷嘴塑料瓶、电子设备、电池、公章、伞, 共12类。
模型评价指标
wAP50,即各个类别的AP50按照权重进行加权的结果。
其中各类别权重为:
刀1、剪刀1、尖锐工具1、甩棍1、小玻璃瓶1、电棍1、塑料饮料瓶0.7、带喷嘴塑料瓶0.7、电子设备0.7、电池0.7、公章0.7、伞0.7。
模型大小
600M以内
2. 赛题分析
赛题数据中,提供了大量的无标注数据,利用好这些无标注数据进行半监督学习是关键。 数据可视化发现数据背景较复杂且差异较大,设计合适的数据增强方法是关键。 模型评价指标为AP50,因此更关注于模型的分类效果。 在模型大小范围内,允许进行一定的模型融合。
三、方案介绍
基本方案从数据增强、模型训练、半监督学习、模型融合三个角度进行介绍。
数据增强
1. 数据均衡
首先对数据进行分析,如图所示,经统计发现,数据存在严重的不平衡问题,需要进行数据平衡操作。
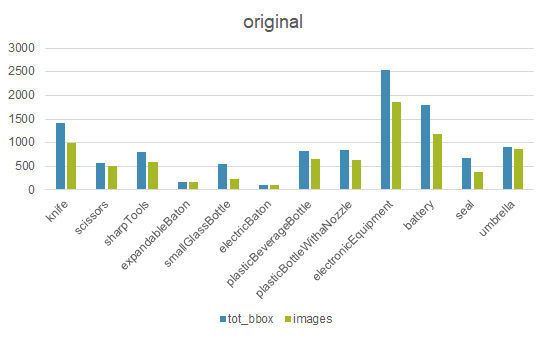
数据平衡策略
统计每个类别bbox数量,做归一化得到n
类别采样次数= max(1,oversample_thr/n)
图片实际的采样次数等于图片中最大的类别采样次数
均衡化之后的数据分布:
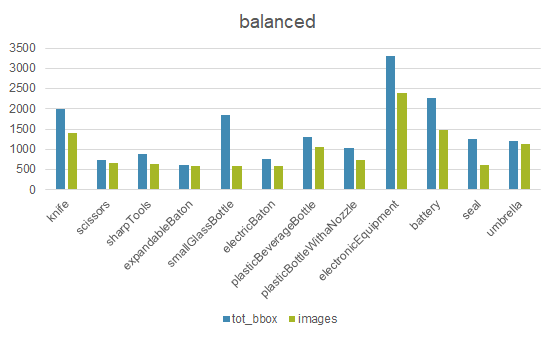
可以看到,经过数据均衡化操作之后,极端分布的类别样本得到了缓和,各个类别分别相对均衡。
2. 基本数据增强
随机反转RandomFlip、随机90°旋转RandomRotate。
几何层面的数据增强一般都能提升模型性能,比较稳定。X光图像对于色彩比较敏感,因此常见的color层面的数据增强经测试基本没什么效果。
3. MixUpObject
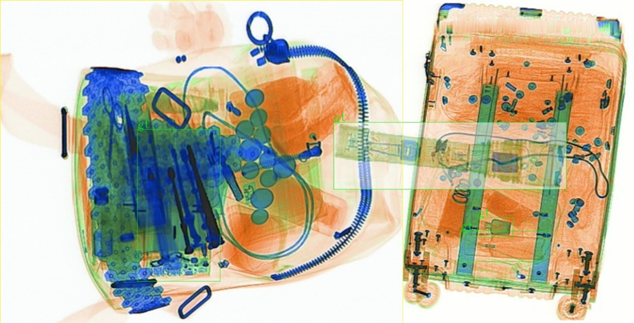
初赛阶段:可供训练的数据只有带标签的训练数据,为了提升模型对前景的识别能力,在训练期间,从训练集中随机选取一张图片的目标bbox,通过mixup的方式粘贴到正在训练的样本上。
复赛阶段:官方提供了一些目标的patch,因此训练时可以直接将目标patch给mixup到正在训练的样本上。
mixup效果如图所示(看起来贴的一般,但训起来好啊 ):
):
4. FixScaleResize
结合X光安检图像的成像特点,由于设备限制,其光源到物品的目标的距离是在一定范围内的,因此同一类别的目标的尺寸差异不会特别大。这一点和自然场景下的目标有较大不同,自然场景下的目标是有近大远小的情况的,也就是同一目标在不同距离的成像上,尺度可能会有非常大的差异。
因此,在进行多尺度训练时,首先需要统计数据集中同一类别目标的面积差异分布,然后据此设计出大致的缩放范围,再进行消融实验找到最佳的缩放尺度。
基本步骤:
首先,以图片原始大小为基准,设置缩放比例范围为(1.5, 3.5)进行图片和目标的缩放;
然后,设置最大缩放面积,对于缩放后超出最大面积的图片,使用最大面积进行截断处理。
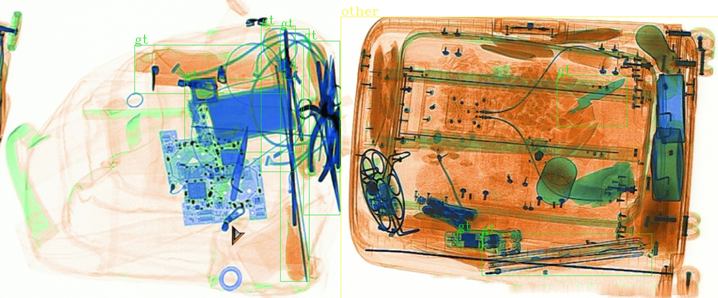
5. StackImage
在比赛后期,由于提供了大量的无标签数据,因此自然想到为无标签数据生成伪标签来进行半监督学习,为此我们开发了StackImage数据增强方法,其目的在于:
a. 增强样本多样性
b. 学习无标签数据上的前景和背景信息
c. 通过拼接强监督信息和弱监督信息,达到弱化伪标签中噪音数据的目的。
基本步骤:
a. 同时取一张带标签的图片和一张无标签的图片,无标注图片使用半监督标注信息
b. 将两张图像以水平或垂直的方式进行stack,方向按照面积最小的原则
c. 无法完全对齐的地方用255填充
可视化效果:
模型选择和训练
1. 模型选择
检测框架:mmdetection
检测模型:
虽然目前swin-transformer很火,但是由于对其不是非常熟悉,另外transformer系列模型训练一般都需要较长时间和较大的GPU显存,因此选用二阶段经典网络faster-rcnn作为基线模型。
这里没有使用去年冠军方案使用的cascade-rcnn作为检测模型基线,主要是考虑到以下几点:
a. cascade-rcnn主要是对与gt的iou大于0.5的bbox的进一步优化坐标,对AP50的提升贡献较小。
b. cascade-rcnn模型较大,不利于后期模型融合策略的使用。
c. cascade-rcnn模型占用显存较大,且需要更长的训练时间。
backbone选择:
res2net101,不解释了,又强又快。
模型选择小技巧:根据经验,coco检测模型预训练相比于imagenet分类预训练有更好的效果,因此优先选择mmdetection中有coco检测预训练权重的模型。
2. Tricks
基本调参,根据对赛题的分析和对赛题的理解,对模型内相关参数尽量调整,比如学习率、rcnn正负样本采样数量、学习率衰减策略等。
模型组件--FPN,增强对小目标的识别能力,一般mmdetection实现的fasterrcnn有自带。
模型组件--DCN,DCN一般都会有比较好的效果,但是也会增加较长训练时间,可以考虑在比赛的后期再加上
模型组件--GC,有类似于空间注意力机制的作用。
训练策略--Class Loss Weight,由于AP50的指标更看重模型的分类性能,因此可以适当调大分类损失的权重,经过实验由1调整至1.25效果较好。
预训练权重--CocoPretrain,相比较于仅使用ImageNet的分类模型预训练,使用COCO的检测模型预训练能稳定涨点。
模型压缩--FP16,本次比赛有模型大小限制,因此在模型训练之后将其权重由FP32转变为FP16,其大小能降低一半。
半监督学习
本次比赛提供了大量的无标签数据,如表所示,可以看到有四批数据共15000张无标签数据,仅4000张有标签数据,因此如何使用半监督学习的方式利用好这15000张半监督数据样本,也是本次比赛的关键。
| 数据 | 数量 | 说明 | 划分 |
|---|---|---|---|
| train1 | 4000 | 初赛A榜训练 | with_label |
| test1_A | 3000 | 初赛A榜测试 | without_label |
| test1_B | 4000 | 初赛B榜测试 | without_label |
| domain5 | 4000 | 官方提供未标注数据 | without_label |
| domain6 | 4000 | 官方提供未标注数据 | without_label |
| patch | 422 | 只包含单个物体的图片 | patch |
基本流程有以下步骤:
a. 首先使用有标签数据,训练出一个较好的模型,然后在无标签数据上推理,得到伪标签,并使用阈值进行过滤掉分数低的目标框。
b. 然后重新训练模型,将有标签的样本和伪标签的样本使用StackImage的方式进行拼接,然后送入到模型进行训练。
c. 训练后的模型,在测试集上效果变的更好了,再使用这个模型重新生成无标注数据的伪标签并进行阈值过滤,然后再重复上述训练过程。
d. 直至模型在测试集上的分数不再上升为止。
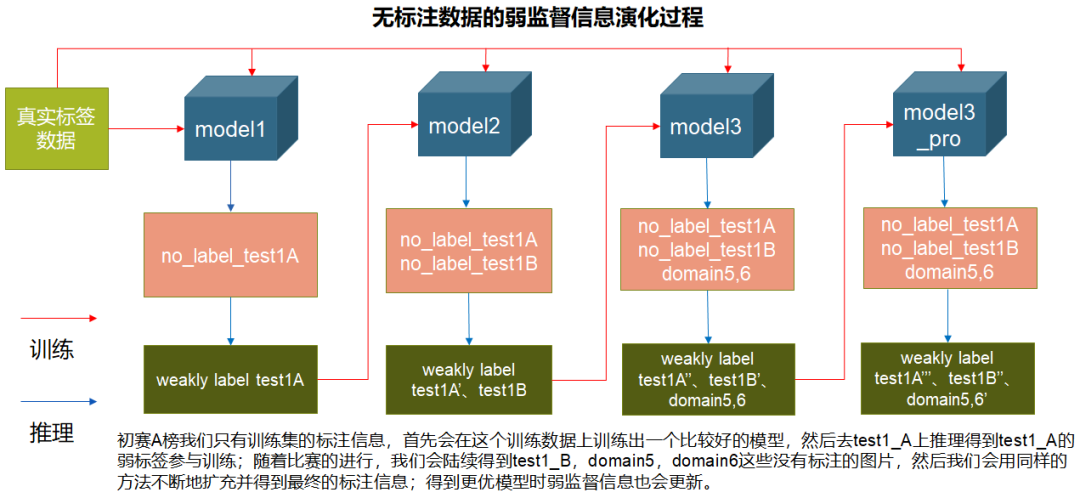
由于这些无标签数据的获取顺序是,初赛A榜时有test1_A,初赛B榜时有test1_B,复赛时有domain5, domain6,因此整个半监督学习的过程如下图所示:
模型融合
1. 模型内部融合
模型内部融合我们采取的策略是结合图像尺度和数据增强,其实也就是TTA。
在尺度方面,在训练时设置的(1.5, 3.5)范围内选择多个尺度进行消融实验,最终确定使用2.0, 2.5, 3.0的缩放比例,然后分别进行模型推理。
在数据增强方面,在不同的尺度下,进行verticalFlip、Rotate90、Horizontal Flip数据增强,然后进行模型推理。
最终将得到的多尺度多数据增强的推理结果进行融合。
2. 模型之间的融合
比赛最后发现,仅使用res2net101-fasterrcnn单模型TTA就已经能够稳坐第一的位置,但是为了能有更好的成绩,我们选择在比赛限制内,融合更多的模型。
由于比赛限制模型大小600M,因此在这个范围内,经过了FP16的压缩,可以进行以下三个模型的融合:
a. res2net101-fasterrcnn
b. resnext101_32x4d-fasterrcnn
c. resnext101_64x4d-fasterrcnn
使用这个三个模型,分别完成上述的模型训练过程,然后各自进行模型内部融合,将各自的融合结果进行模型之间的融合。
3. 模型融合方法
模型融合采用WBF融合策略,如下图所示。
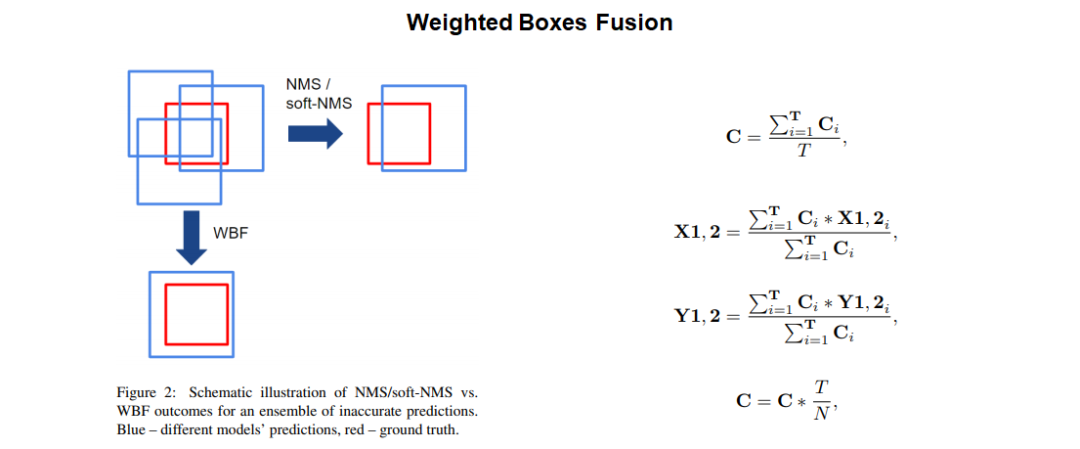
注意:针对不同的任务,WBF的过程需要一定程度的调参实验,可得到较好的效果。
四、总结和思考
总结
模型选择
基线模型:Faster-RCNN
BackBone:Res2Net101、Resnext101_32×4d、Resnext101_64×4d
检测框架:MMDetection
主要技术
数据增强:数据平衡、StackImage、 MixupObject、FixScale
Tricks:半监督学习、DCN、 Global Context、COCO预训练、TTA、 WBF、ClsLossWeight
思考
充分理解赛题和评价指标,充分理解经典模型的原理及其适用场景,以便更好地进行模型选型。 关注新技术,决赛时发现大部分选手都使用了swin-transformer,说明应该还是很强的。 充分理解数据,决赛时才知道domain5、domain6是来自两个不同X光机器的图片,如果更细致去分析其中的特点进行相关工作,可能会有更好的效果。 充分理解评价指标,可以看到计算AP50时,不同类别的权重是不一样的,这一点暂时没想好更好的办法利用这一点得到更好的结果。
以上就是我们的分享,希望有兴趣的同学一起交流,啄云智能算法团队常年招收优秀算法工程师(邮箱:renshi@peckerai.com),谢谢大家。
宋志龙
啄云智能算法工程师

王威
啄云智能算法工程师