
Go实现各类限流算法

前 言
在开发高并发系统时,我们可能会遇到接口访问频次过高,为了保证系统的高可用和稳定性,这时候就需要做流量限制,你可能是用的
Nginx这种来控制请求,也可能是用了一些流行的类库实现。限流是高并发系统的一大杀器,在设计限流算法之前我们先来了解一下它们是什么。
限 流
限流的目的是通过对并发访问请求进行限速,或者对一个时间窗口内的请求进行限速来保护系统,一旦达到限制速率则可以拒绝服务、排队或等待、降级等处理。通过对并发(或者一定时间窗口内)请求进行限速来保护系统,一旦达到限制速率则拒绝服务(定向到错误页或告知资源没有了)、排队等待(比如秒杀、评论、下单)、降级(返回兜底数据或默认数据)。
如 图:

如图上的漫画,在某个时间段流量上来了,服务的接口访问频率可能会非常快,如果我们没有对接口访问频次做限制可能会导致服务器无法承受过高的压力挂掉,这时候也可能会产生数据丢失,所以就要对其进行限流处理。
限流算法就可以帮助我们去控制每个接口或程序的函数被调用频率,它有点儿像保险丝,防止系统因为超过访问频率或并发量而引起瘫痪。我们可能在调用某些第三方的接口的时候会看到类似这样的响应头:
X-RateLimit-Limit: 60 //每秒60次请求
X-RateLimit-Remaining: 22 //当前还剩下多少次
X-RateLimit-Reset: 1612184024 //限制重置时间
上面的 HTTP Response 是通过响应头告诉调用方服务端的限流频次是怎样的,保证后端的接口访问上限。为了解决限流问题出现了很多的算法,它们都有不同的用途,通常的策略就是拒绝超出的请求,或者让超出的请求排队等待。
一般来说,限流的常用处理手段有:
计数器 滑动窗口 漏桶 令牌桶
计数器
计数器是一种最简单限流算法,其原理就是:
在一段时间间隔内,对请求进行计数,与阀值进行比较判断是否需要限流,一旦到了时间临界点,将计数器清零。这个就像你去坐车一样,车厢规定了多少个位置,满了就不让上车了,不然就是超载了,被交警叔叔抓到了就要罚款的,如果我们的系统那就不是罚款的事情了,可能直接崩掉了。
可以在程序中设置一个变量 count,当过来一个请求我就将这个数+1,同时记录请求时间。当下一个请求来的时候判断 count的计数值是否超过设定的频次,以及当前请求的时间和第一次请求时间是否在1分钟内。如果在 1分钟内并且超过设定的频次则证明请求过多,后面的请求就拒绝掉。如果该请求与第一个请求的间隔时间大于计数周期,且 count值还在限流范围内,就重置count。
代码实现:
package main
import (
"log"
"sync"
"time"
)
type Counter struct {
rate int //计数周期内最多允许的请求数
begin time.Time //计数开始时间
cycle time.Duration //计数周期
count int //计数周期内累计收到的请求数
lock sync.Mutex
}
func (l *Counter) Allow() bool {
l.lock.Lock()
defer l.lock.Unlock()
if l.count == l.rate-1 {
now := time.Now()
if now.Sub(l.begin) >= l.cycle {
//速度允许范围内, 重置计数器
l.Reset(now)
return true
} else {
return false
}
} else {
//没有达到速率限制,计数加1
l.count++
return true
}
}
func (l *Counter) Set(r int, cycle time.Duration) {
l.rate = r
l.begin = time.Now()
l.cycle = cycle
l.count = 0
}
func (l *Counter) Reset(t time.Time) {
l.begin = t
l.count = 0
}
func main() {
var wg sync.WaitGroup
var lr Counter
lr.Set(3, time.Second) // 1s内最多请求3次
for i := 0; i < 10; i++ {
wg.Add(1)
log.Println("创建请求:", i)
go func(i int) {
if lr.Allow() {
log.Println("响应请求:", i)
}
wg.Done()
}(i)
time.Sleep(200 * time.Millisecond)
}
wg.Wait()
}
OutPut:
2021/02/01 21:16:12 创建请求: 0
2021/02/01 21:16:12 响应请求: 0
2021/02/01 21:16:12 创建请求: 1
2021/02/01 21:16:12 响应请求: 1
2021/02/01 21:16:12 创建请求: 2
2021/02/01 21:16:13 创建请求: 3
2021/02/01 21:16:13 创建请求: 4
2021/02/01 21:16:13 创建请求: 5
2021/02/01 21:16:13 响应请求: 5
2021/02/01 21:16:13 创建请求: 6
2021/02/01 21:16:13 响应请求: 6
2021/02/01 21:16:13 创建请求: 7
2021/02/01 21:16:13 响应请求: 7
2021/02/01 21:16:14 创建请求: 8
2021/02/01 21:16:14 创建请求: 9
可以看到我们设置的是每200ms创建一个请求,明显高于1秒最多3个请求的限制,运行起来之后发现编号为 2、3、4、8、9 的请求被丢弃,说明限流成功。
那么问题来了,如果有个需求对于某个接口 /query 每分钟最多允许访问 200 次,假设有个用户在第 59 秒的最后几毫秒瞬间发送 200 个请求,当 59 秒结束后 Counter 清零了,他在下一秒的时候又发送 200 个请求。那么在 1 秒钟内这个用户发送了 2 倍的请求,这个是符合我们的设计逻辑的,这也是计数器方法的设计缺陷,系统可能会承受恶意用户的大量请求,甚至击穿系统。
如下图:
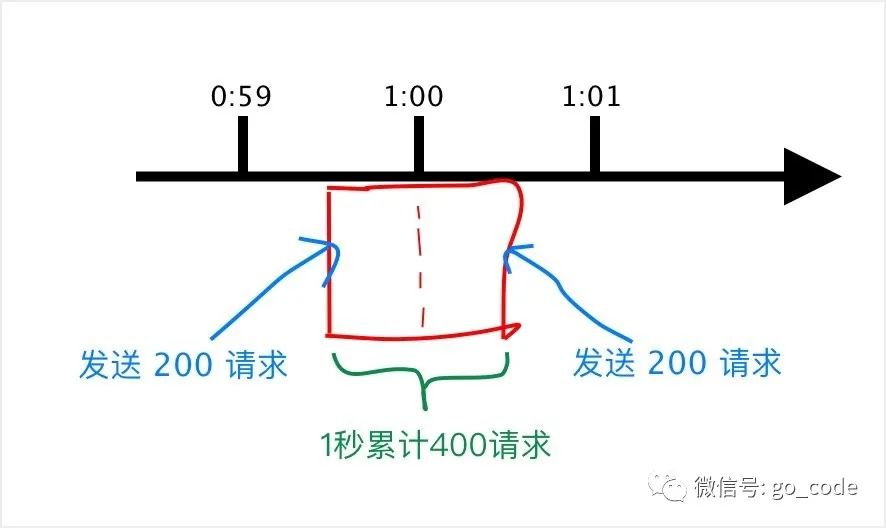
这种方法虽然简单,但也有个大问题就是没有很好的处理单位时间的边界。
滑动窗口
滑动窗口是针对计数器存在的临界点缺陷,所谓 滑动窗口(Sliding window) 是一种流量控制技术,这个词出现在 TCP 协议中。滑动窗口把固定时间片进行划分,并且随着时间的流逝,进行移动,固定数量的可以移动的格子,进行计数并判断阀值。
如 图:
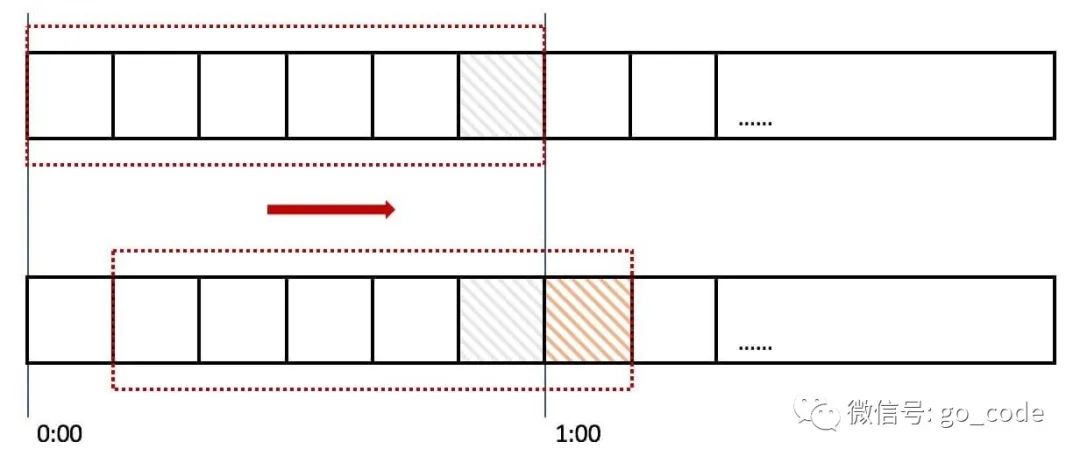
上图中我们用红色的虚线代表一个时间窗口(一分钟),每个时间窗口有 6 个格子,每个格子是 10 秒钟。每过 10 秒钟时间窗口向右移动一格,可以看红色箭头的方向。我们为每个格子都设置一个独立的计数器 Counter,假如一个请求在 0:45 访问了那么我们将第五个格子的计数器 +1(也是就是 0:40~0:50),在判断限流的时候需要把所有格子的计数加起来和设定的频次进行比较即可。
那么滑动窗口如何解决我们上面遇到的问题呢?来看下面的图:

当用户在0:59 秒钟发送了 200个请求就会被第六个格子的计数器记录 +200,当下一秒的时候时间窗口向右移动了一个,此时计数器已经记录了该用户发送的 200 个请求,所以再发送的话就会触发限流,则拒绝新的请求。
其实计数器就是滑动窗口啊,只不过只有一个格子而已,所以想让限流做的更精确只需要划分更多的格子就可以了,为了更精确我们也不知道到底该设置多少个格子,格子的数量影响着滑动窗口算法的精度,依然有时间片的概念,无法根本解决临界点问题。
相关算法实现 github.com/RussellLuo/slidingwindow
漏 桶
漏桶算法(Leaky Bucket),原理就是一个固定容量的漏桶,按照固定速率流出水滴。用过水龙头都知道,打开龙头开关水就会流下滴到水桶里,而漏桶指的是水桶下面有个漏洞可以出水。如果水龙头开的特别大那么水流速就会过大,这样就可能导致水桶的水满了然后溢出。
如 图:

一个固定容量的桶,有水流进来,也有水流出去。对于流进来的水来说,我们无法预计一共有多少水会流进来,也无法预计水流的速度。但是对于流出去的水来说,这个桶可以固定水流出的速率(处理速度),从而达到 流量整形 和 流量控制 的效果。
代码实现:
type LeakyBucket struct {
rate float64 //固定每秒出水速率
capacity float64 //桶的容量
water float64 //桶中当前水量
lastLeakMs int64 //桶上次漏水时间戳 ms
lock sync.Mutex
}
func (l *LeakyBucket) Allow() bool {
l.lock.Lock()
defer l.lock.Unlock()
now := time.Now().UnixNano() / 1e6
eclipse := float64((now - l.lastLeakMs)) * l.rate / 1000 //先执行漏水
l.water = l.water - eclipse //计算剩余水量
l.water = math.Max(0, l.water) //桶干了
l.lastLeakMs = now
if (l.water + 1) < l.capacity {
// 尝试加水,并且水还未满
l.water++
return true
} else {
// 水满,拒绝加水
return false
}
}
func (l *LeakyBucket) Set(r, c float64) {
l.rate = r
l.capacity = c
l.water = 0
l.lastLeakMs = time.Now().UnixNano() / 1e6
}
漏桶算法有以下特点:
漏桶具有固定容量,出水速率是固定常量(流出请求) 如果桶是空的,则不需流出水滴 可以以任意速率流入水滴到漏桶(流入请求) 如果流入水滴超出了桶的容量,则流入的水滴溢出(新请求被拒绝)
漏桶限制的是常量流出速率(即流出速率是一个固定常量值),所以最大的速率就是出水的速率,不能出现突发流量。
令牌桶算法
令牌桶算法(Token Bucket)是网络流量整形(Traffic Shaping)和速率限制(Rate Limiting)中最常使用的一种算法。典型情况下,令牌桶算法用来控制发送到网络上的数据的数目,并允许突发数据的发送。

我们有一个固定的桶,桶里存放着令牌(token)。一开始桶是空的,系统按固定的时间(rate)往桶里添加令牌,直到桶里的令牌数满,多余的请求会被丢弃。当请求来的时候,从桶里移除一个令牌,如果桶是空的则拒绝请求或者阻塞。
实现代码:
type TokenBucket struct {
rate int64 //固定的token放入速率, r/s
capacity int64 //桶的容量
tokens int64 //桶中当前token数量
lastTokenSec int64 //桶上次放token的时间戳 s
lock sync.Mutex
}
func (l *TokenBucket) Allow() bool {
l.lock.Lock()
defer l.lock.Unlock()
now := time.Now().Unix()
l.tokens = l.tokens + (now-l.lastTokenSec)*l.rate // 先添加令牌
if l.tokens > l.capacity {
l.tokens = l.capacity
}
l.lastTokenSec = now
if l.tokens > 0 {
// 还有令牌,领取令牌
l.tokens--
return true
} else {
// 没有令牌,则拒绝
return false
}
}
func (l *TokenBucket) Set(r, c int64) {
l.rate = r
l.capacity = c
l.tokens = 0
l.lastTokenSec = time.Now().Unix()
}
令牌桶有以下特点:
令牌按固定的速率被放入令牌桶中 桶中最多存放 B个令牌,当桶满时,新添加的令牌被丢弃或拒绝如果桶中的令牌不足 N个,则不会删除令牌,且请求将被限流(丢弃或阻塞等待)
令牌桶限制的是平均流入速率(允许突发请求,只要有令牌就可以处理,支持一次拿3个令牌,4个令牌...),并允许一定程度突发流量。
小 结
目前常用的是令牌桶这种,本文介绍了几种常见的限流算法实现,文章撰写不易,点个关注不迷路。