
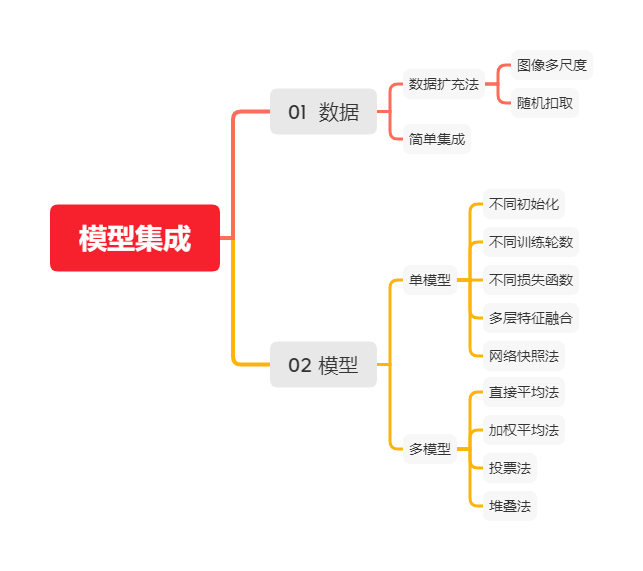
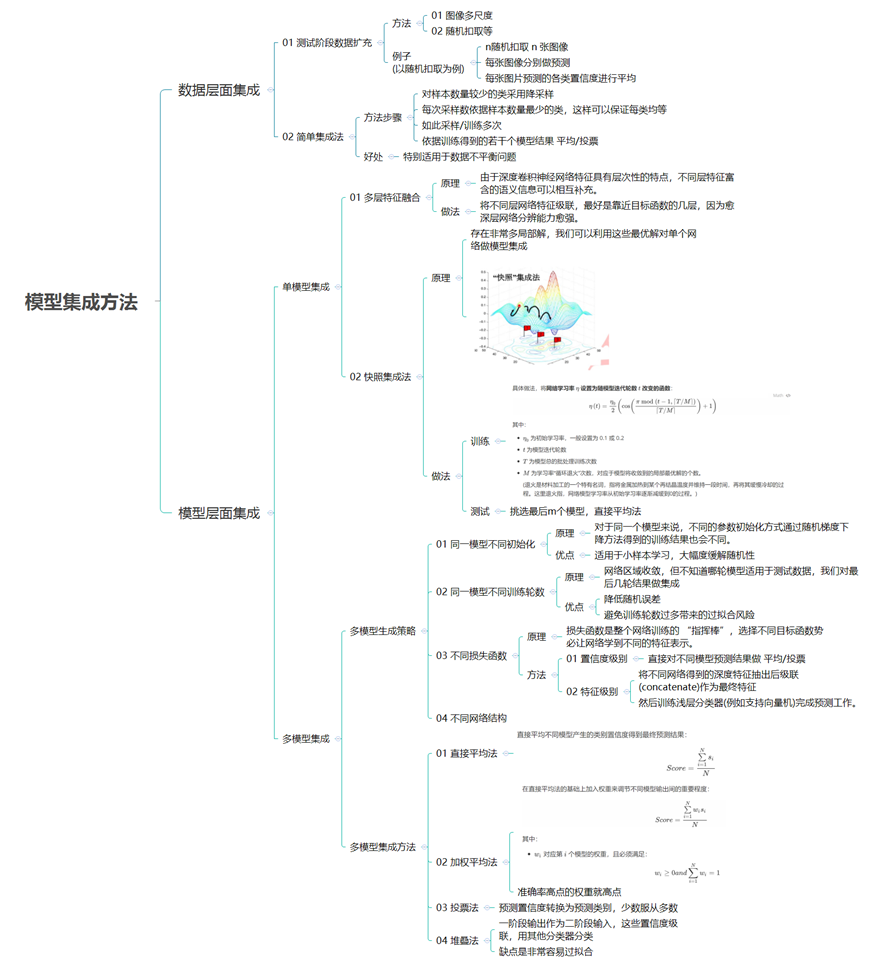
常见深度学习模型集成方法
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自|计算机视觉工坊

(1)数据扩充法
图像多尺度(multi-scale):将图像resize到不同尺寸,分别输入网络,对结果进行平均或者加权。 随机扣取(random crop):对测试图片随机扣取n张图像,在测试阶段用训练好的深度网络模型对n张扣取出来的图分别做预测,之后将预测的各类置信度平均作为测试图像最终的测试结果。
(2)简单集成法
对于样本较多的类采取降采样(undersampling),每次采样数依据样本数量最少的类别而定,这样每类取到的样本数可保持均等; 采样结束后,针对每次采样得到的子数据集训练模型,如此采样、训练重复进行多次。 最后依据训练得到若干个模型的结果取平均/投票。
2.1 单模型集成
(1)同一模型不同初始化
初始:首先对同一模型进行不同初始化; 集成:将得到的网络模型结果进行集成;
(2)同一模型不同训练轮数
(3)不同损失函数
置信度融合:直接对不同模型预测结果做平均/投票; 特征融合:将不同网络得到的深度特征抽出后级联(concatenate)作为最终特征,然后训练浅层分类器(如支持向量机)完成预测工作;
(4)多层特征融合法
(5)网络快照法
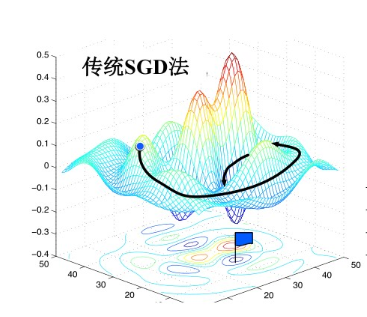
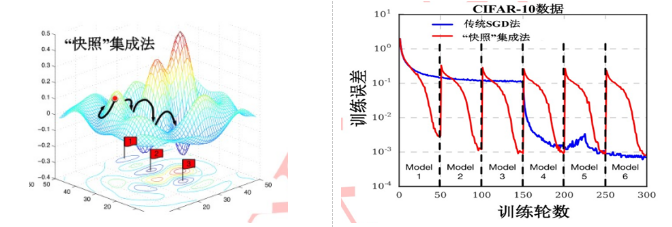
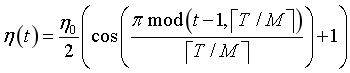
为初始学习率,一般设置为 0.1 或 0.2;
t为模型迭代轮数; T为模型总的批处理训练次数; M为“循环退火”次数,对应于模型将收敛到的局部最优解的个数;
2.2 多模型集成
(1)直接平均法
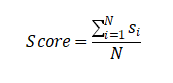
(2)加权平均法
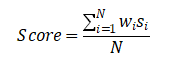
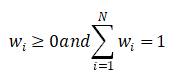
(3)投票法
某个类别获得一半以上模型投票,则将样本标记为该类别; 没有任何类别获得一半以上投票,则拒绝预测;
(4)堆叠法
原始模型训练、预测:样本x作为模型的输入,Si为第i个模型的类别置信度输出; 预测结果作为二阶段输入:讲这些输出置信度进行级联,作为新的特征,基于这些特征训练一个新的分类器进行训练;
好消息,小白学视觉团队的知识星球开通啦,为了感谢大家的支持与厚爱,团队决定将价值149元的知识星球现时免费加入。各位小伙伴们要抓住机会哦!

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论