
【万级并发】电商库存扣减如何设计?不超卖!
随着中国消费认知的不断升级,网购走近千家万户,越来越被人们所接受。淘宝、唯品会、考拉、京东、拼多多等逐渐成为我们生活的重要组成部分。

除了常规的购物下单外,这些电商平台还经常搞一些双十一活动,秒杀、大促、限时购,各种营销玩法,层出不穷。今天就来跟大家聊一聊电商技术里的库存扣减

当有很多人同时在买一件商品时(假设库存充足),每个人几乎同时下单成功,给人一种并行的感觉。但真实情况,库存只是一个数值,无论是存在mysql数据库还是redis缓存,减值时都要控制顺序,只能串行来扣减,当然为了保证安全性,会设计一些锁控制操作。
🌴 库存扣减关键技术点
同一个SKU,库存数量是共享 剩余库存要大于等于本次扣减的数量,否则会出现 超卖现象,引发资损对同一个数量多用户并发扣减时,要注意并发安全,保证数据的一致性 类似于秒杀这样高QPS的扣减场景,要保证性能与高可用 对于购物车下单场景,多个商品库存批量扣减,要保证事务 如果有 交易退款,保证库存扣减可以返还返还的数据总量不能大于扣减的总量 返还要保证幂等 可以分多次返还
🌴 数据库扣减方案
主要是依赖数据库特性来保证扣减的一致性,逻辑简单,开发部署成本很低。
依赖的数据库特性:
依赖数据库的乐观锁(比如:版本号或者库存数量)保证数据并发扣减的强一致性 借助事务特性,针对购物车下单批量扣减时,部分扣减失败,数据回滚
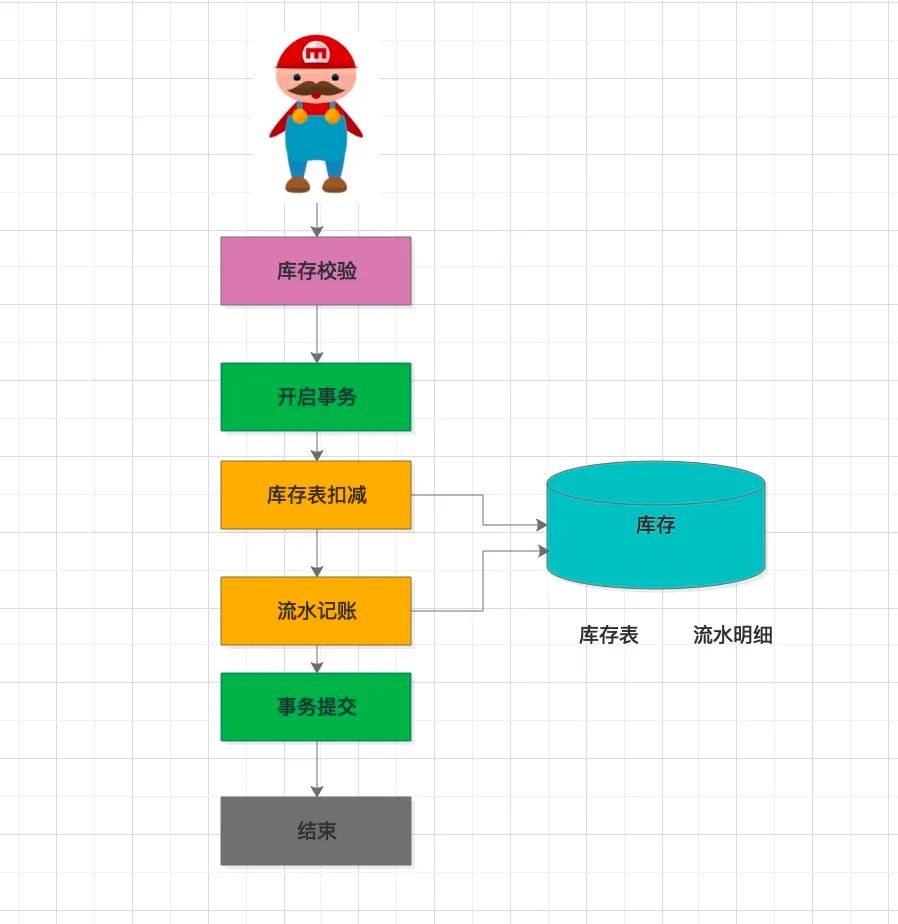
最上面会查询当前的剩余库存(可能不准确,但没关系,这里只是第一步粗略校验),前置校验,如果已经没有库存,前置拦截生效,减少对数据库的写操作。毕竟读操作不涉及加锁,并发性能高。数据库包含两张表:库存表、流水表。
1、库存表
| 字段 | 说明 |
|---|---|
| sku_id | 商品规格id |
| leaved_amount | 剩余可购买数量 |
当用户进行取消订单、申请退货退款,需要把数量加回来 如果商家补过库存,需要在此基础上额外加上增量库存
2、 流水表
| 字段 | 说明 |
|---|---|
| id | 主键id |
| sku_id | 商品规格id |
| order_detail_id | 订单明细id |
| quantity_trade | 本次购买扣减的数量 |
用于查看明细、对账、盘货、排查问题等 在扣减后,某些场景下需要返还也依赖流水
单条商品的扣减SQL大致如下:
update inventory
set leaved_amount = leaved_amount - #{count}
where sku_id='123' and leaved_amount >= #{count}
此 SQL 采用数据库自带行锁机制,在 where 条件里判断此次购买的数量小于等于剩余的数量。在扣减服务的代码里,判断此 SQL 的返回值,如果值为 1 ,表示扣减成功。否则,返回 0 ,表示库存不足,需要回滚。
扣减成功后,需要记录扣减流水,并与订单明细记录做关联。
当用户归还数量时,需要带回此编号,用来标识此次返还属于历史上的具体哪次扣减。
进行幂等性控制。当用户调用扣减接口出现超时时,因为用户不知道是否成功,用此编号进行重试或反查。在重试时,使用此编号进行标识防重。
🌴 【数据库扣减方案】第一次升级
举个极端的例子:最新款iPhone秒杀,库存只有5件,活动期间峰值QPS预估在10W,活动结束后,上面的流水表最终只会插入5条记录,但是查询的QPS却接近 10W QPS,读的压力非常大。
所以,数据库扣减方案第一次升级主要是针对库存前置校验模块的优化,作为前置拦截器,承载的流量很大,如果将流量全部压到主库上,很容易把数据压垮。我们考虑把数据库架构升级。
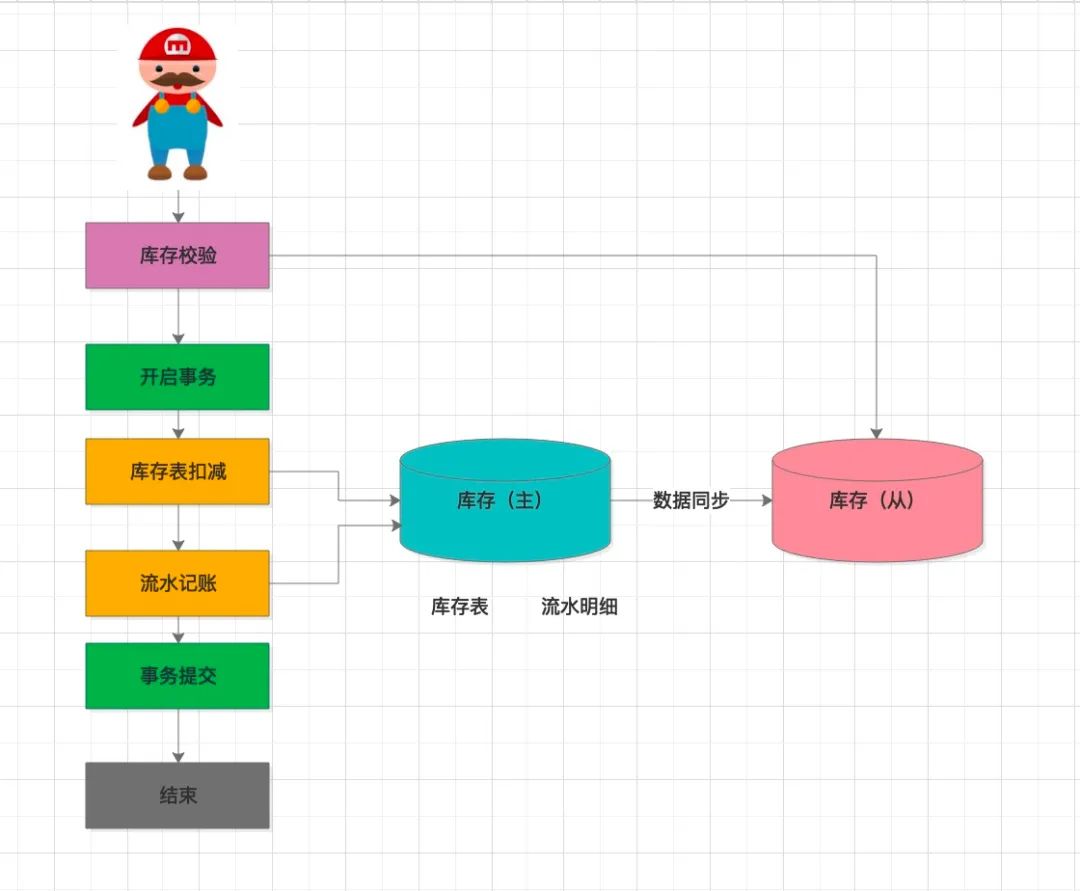
采用了读写分离方式,新增加了一套从库,借助mysql自带的数据同步能力。库存校验时读取从数据库。
当然,数据同步有一定的时间延迟,从库的数据新鲜度有一定的滞后性,所以这个库存校验结果并不一定准确,但却能拦截大部分的无效流量。最终能不能成功购买,由主库的乐观扣减SQL来控制,并不会影响最终扣减的准确性。大大减轻主库的查询压力。
🌴 【数据库扣减方案】第二次升级
引入了从库,确实能分摊主库很大一部分压力,但是面对秒杀这种万级QPS流量,mysql的千级TPS根本支撑不了,需要进一步升级读取的性能。
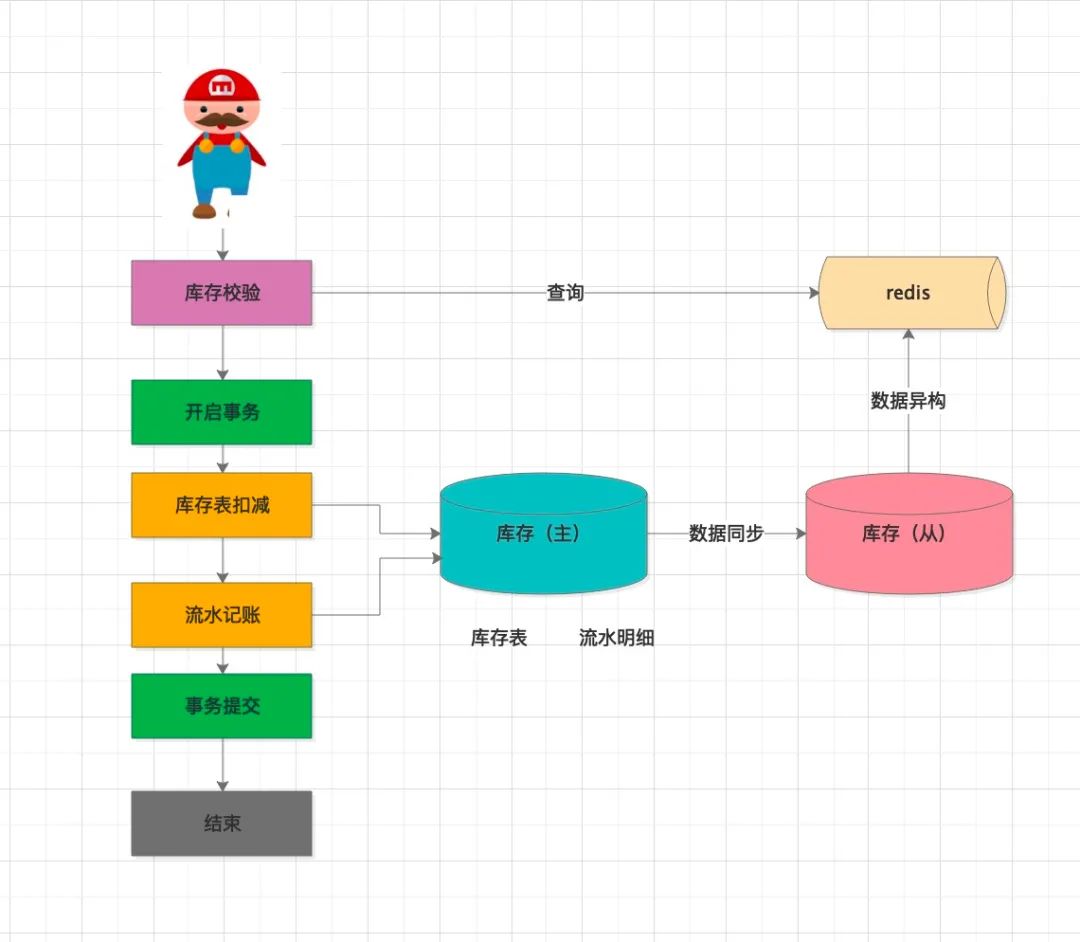
此时引入缓存中间件(如Redis),将mysql的数据定时同步到缓存中 库存校验模块,从redis中查询剩余的库存数据。由于缓存基于内存操作,性能比数据库高出几个数量级,单台redis实例可以达到10W QPS的读性能
该方案升级后,基本上解决了在前置库存校验环节及获取库存数量接口的性能问题,提高了系统整体性能,提供较好的用户体验。
补充说明:
如果并发量还是很高的话,可以考虑引入缓存集群,将不同的秒杀商品sku尽量均匀分布在多个redis节点中,从而分摊掉整体的峰值QPS压力。(参考缓存热点的解决方案)
数据库方案的优点:
借助数据库的 ACID特性,业务上不会出现超卖、少买现象实现简单,如果项目工期紧张,或者开发资源不足情况下非常适用
数据库方案的不足:
如果参与秒杀的SKU非常多,最后的写操作都是基于 库存主库,性能压力会比较大。
🌴 纯缓存扣减方案
Redis采用单线程的事件模型,具有原子性的特性。当有多个客户端给Redis发送命令时,Redis会按照接收到的顺序串行化执行。对于还未被调度的命令,则放在队列里排队等待。
库存扣减为了保证数据并发安全,要求原子性,而Redis正好满足扣减类的特殊性要求,是个不错的技术选型。
下面,我们简单来看看基于Redis如何来设计库存扣减?
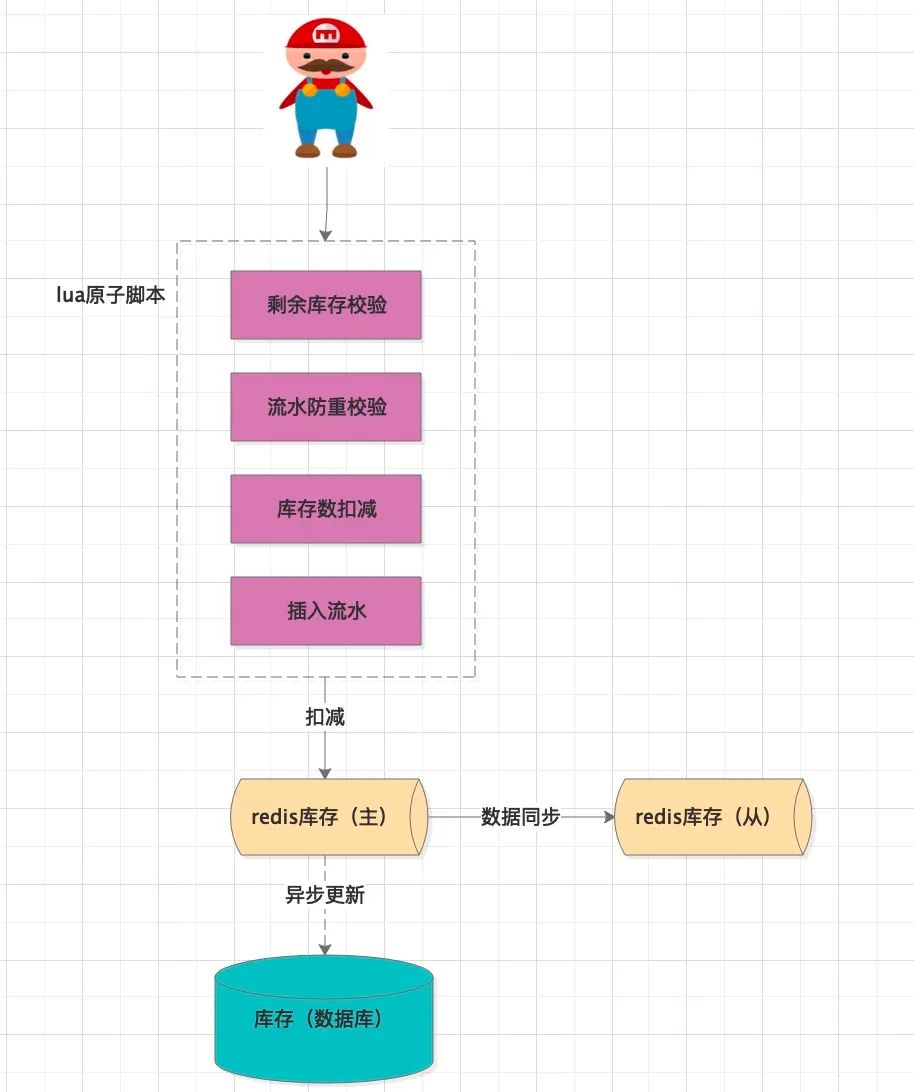
首先,设计Redis的数据模型:
剩余库存(k-v结构):
key:sku_leaved_amount_{sku_id}
value:剩余的库存数值
流水(hash结构):
key:inventory_flow_{sku_id}
hash—key:订单明细id(不同业务场景的全局性id,用来做幂等控制)
hash—value:本次购买的数量
对于购物车下单,多个sku批量扣减,我们需要按单个sku循环发起Redis调用。但是多个Redis命令无法保证原子性。我们可以采用lua脚本形式,将这些命令打包到一个脚本中,作为一个命令发送给Redis执行,从而保证了原子性。
lua 是一个类似 JavaScript、Shell 等的解释性语言,它可以完成 Redis 已有命令不支持的功能。用户在编写完 lua 脚本之后,将此脚本上传至 Redis 服务端,服务端会返回一个标识码代表此脚本。在实际执行具体请求时,将数据和此标识码发送至 Redis 即可。Redis 会和执行普通命令一样,采用单线程执行此 lua 脚本和对应数据。
Lua 脚本执行流程:
批量扣减是对单个扣减的循环调用,所以这里介绍的流程只讲单次扣减的处理步骤。
首先根据 订单明细id查询扣减流水,是否已经操作过,做幂等性校验然后查询sku的剩余库存,并根据 下单购买数做校验,只要有一个sku 数量不足,则返回失败修改所有sku的缓存中的剩余库存数 缓存中插入扣减流水记录
当Redis扣减成功后,应用程序再将此次扣减异步化保存到数据库中,持久化存储,毕竟Redis只是临时性存储,有宕机风险,会丢失数据。
缓存方案利弊分析:
Redis缓存方案,借助了缓存的高性能,承载更高的并发。但是没有数据库的ACID特性,极端情况下,可能出现少卖情况为了避免 少卖情况发生,纯缓存方案需要做大量的对账、异常处理的设计,系统复杂度增加很多。纯缓存方案适合一些高并发、大流量场景,但对数据准确度要求不是特别苛刻的业务场景。
风险:
上述Lua脚本把多条命令打包在一起,虽然保证了原子性,但不具备事务回滚特性。比如,库存扣减成功了,此时Redis宕机,扣减流水并没有插入成功,应用程序认为本次Redis调用是失败的,前台给用户反馈错误提示,但是已经扣减的数量不会回滚。当Redis故障修复后,再次启动,此时恢复的数据已经存在不一致了。需要结合Redis和数据库做数据核对check,并结合扣减服务的日志,做数据的增量修复。
🌴 基于分库分表的扣减方案
上面提到的数据库方式是基于单库单表玩法,虽然借助ACID特性能保证数据的一致性,但是单台mysql的并发能力有限,如何提升性能?
除了纯缓存化方案外,我们还可以考虑将库存表进行水平拆分,分摊洪峰压力。
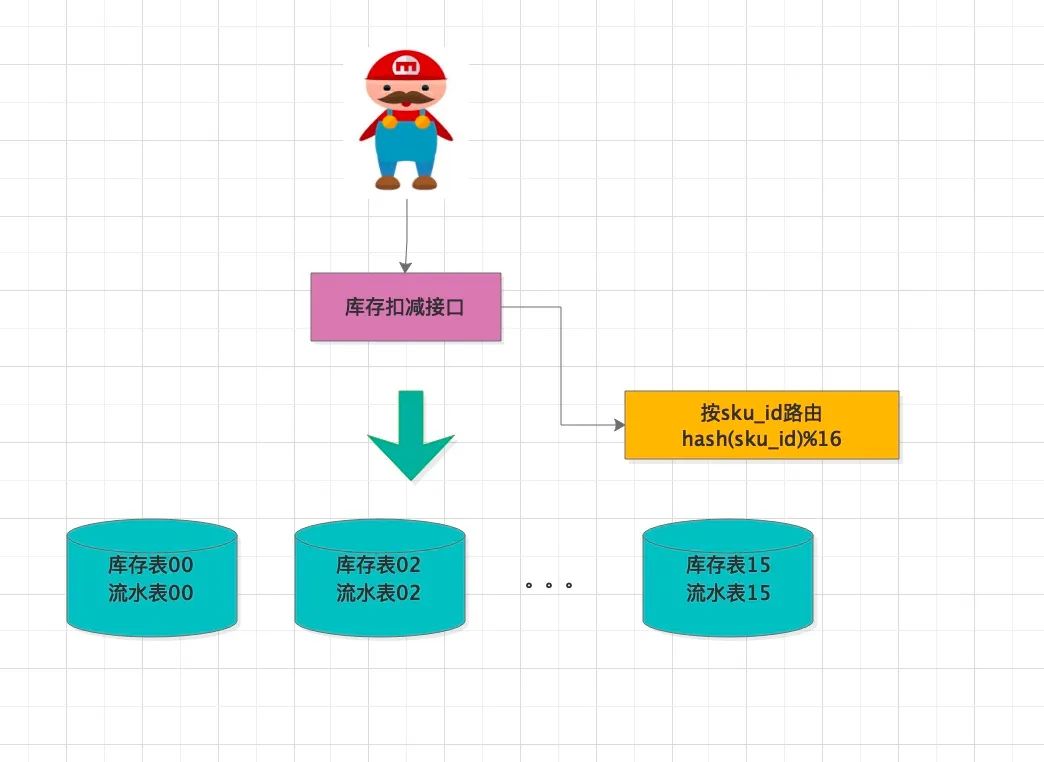
假如库存表的QPS要求是1.6万,经过拆分成16张表后,如果数据分布均匀,每个物理表预计处理 1000 QPS,完全处于mysql单实例的承载范围之内。
另外拆分后,单表的数据量也会相应减少很多,假如分表前有一个亿数据,分表后每张表不到1千万,索引查询性能也会快很多。
注意:
同一次扣减业务,库存扣减和插入流水要放在同一个分库中,通过事务保证一致性,满足同时成功或同时失败。如果数据分布和业务请求足够均匀,理论上经过分库分表设计后,整个系统的吞吐量将会是线性的增长,主要取决于分表实例的数量。
🌴 其他扣减方案
还有其他的一些解决方案,这里只是提供一些思路,方案细节就不展开了
1、如果某个sku_id的库存扣减过热,单台实例支撑不了(mysql官方测评:一般单行更新的QPS在500以内),可以考虑将一个sku的大库存拆分成N份,放在不同的库中(也就是说所有子库的库存数总和才是一件sku的真实库存),由于前台的访问流量非常大,按照均分原则,每个子库分到的流量应该差不多。上层路由时只需要在sku_id后面拼接一个范围内的随机数,即可找到对应的子库,有效减轻系统压力。
2、单条sku库存记录更新过热,也可以采用批量提交方式,将多次扣减累计计数,集中成一次扣减,从而实现了将串行处理变成了批处理,也可以大大减轻数据库压力。
3、引入RocketMQ消息队列,经过前置校验后,如果有剩余库存,则把创建订单的操作封装成消息发送给MQ,订单系统从RocketMQ中以特定的频率消费,创建订单,该方案有一定的延迟性。
欢迎关注微信公众号:互联网全栈架构,收取更多有价值的信息。