cephfs扩容方案汇总
cephfs扩容方案
需求描述
建立完善的cephfs的扩容方案,满足cephfs用户数据存储空间在各种场景下的扩容需求。目前扩容只涉及到用户的数据存储,元数据部分因为空间使用率较低所以不需要考虑扩容。
现有cephfs用户存储模型
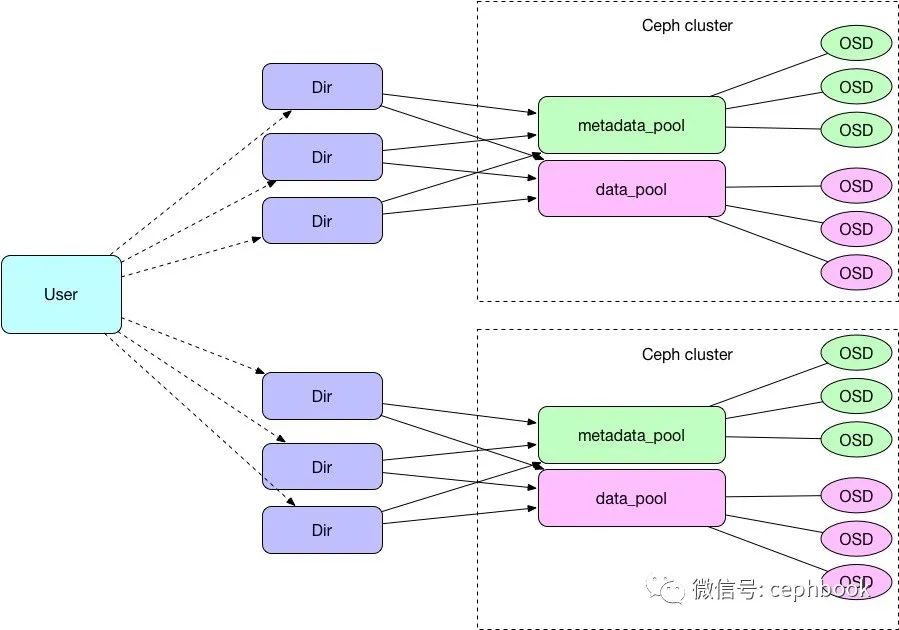
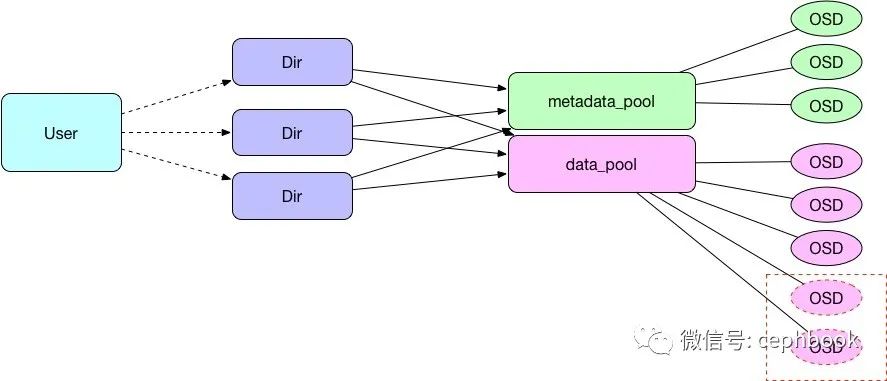
目前单个用户会对应一个ceph集群里面的多个Dir目录,每个Dir目录底层会关联到两个pool,其中metadata_pool用来存储元数据,data_pool用来存储数据。
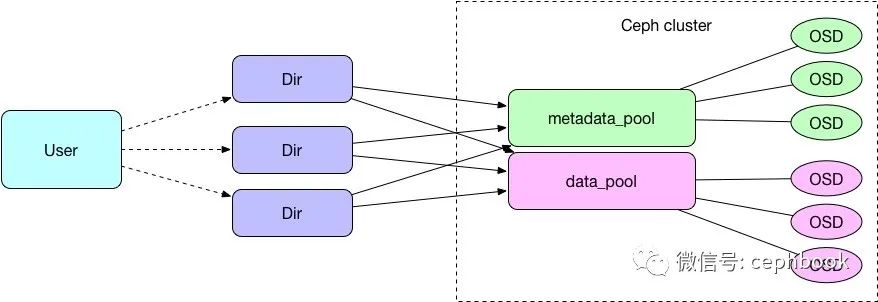
单集群扩容方案
通过filelayout进行扩容
基本原理
每个文件都有filelayout的xattr属性,其中包含一个关键的pool字段,用来指定存储文件底层用到哪个pool,因此利用该特性可以实现基于目录基本的扩容。
参考 https://docs.ceph.com/docs/master/cephfs/file-layouts/#adding-a-data-pool-to-the-mds
操作流程
root@host1:/mnt/cephfs1# ceph df
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 952 TiB 861 TiB 89 TiB 91 TiB 9.52
TOTAL 952 TiB 861 TiB 89 TiB 91 TiB 9.52
POOLS:
POOL ID STORED OBJECTS USED %USED MAX AVAIL
rbdtest-site1-ssd-img 1 8.7 TiB 2.34M 26 TiB 24.58 27 TiB
rbdtest-site1-sas-img 2 8.8 TiB 2.31M 26 TiB 3.63 233 TiB
cephfs_metadata 3 85 GiB 116.05k 86 GiB 0.10 27 TiB
cephfs_data 4 12 TiB 198.68M 36 TiB 30.65 27 TiB
cephfs_pool1 5 121 GiB 31.04k 364 GiB 0.44 27 TiB
sym_cephfs_data 6 656 KiB 13 3.6 MiB 0 233 TiB
sym_cephfs_metadata 7 0 B 0 0 B 0 233 TiB
kubernetes 20 152 B 6 192 KiB 0 233 TiB
root@host1:/mnt/cephfs1# setfattr -n ceph.dir.layout.pool -v cephfs_pool1 /mnt/cephfs1/extest1/
root@host1:/mnt/cephfs1# getfattr -n ceph.dir.layout /mnt/cephfs1/extest1
getfattr: Removing leading '/' from absolute path names
# file: mnt/cephfs1/extest1
ceph.dir.layout="stripe_unit=4194304 stripe_count=1 object_size=4194304 pool=cephfs_pool1"
root@host1:/mnt/cephfs1/extest1# touch file2
root@host1:/mnt/cephfs1/extest1# getfattr -n ceph.file.layout /mnt/cephfs1/extest1/file2
getfattr: Removing leading '/' from absolute path names
# file: mnt/cephfs1/extest1/file2
ceph.file.layout="stripe_unit=4194304 stripe_count=1 object_size=4194304 pool=cephfs_pool1"
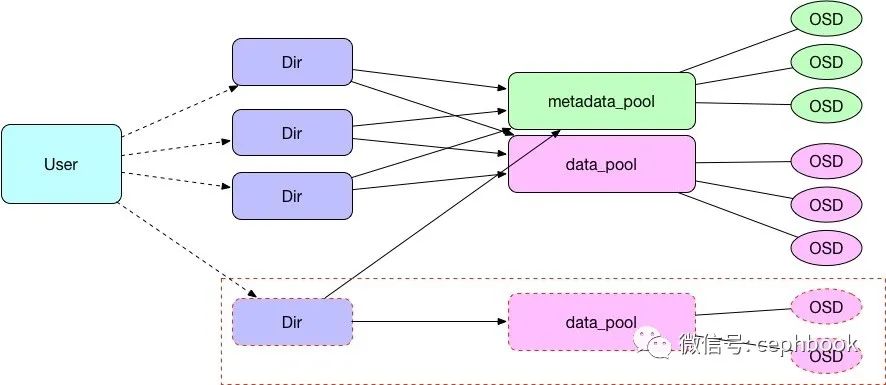
方案1. 同级目录扩容
如果业务侧能够按新增主目录方式进行扩容,则可以通过新增一个用户主目录,将新目录指向新的data_pool来实现扩容。
优点:新扩容的pool不会对现有存储服务造成影响。
缺点:业务需要能够适配这种新增子目录的扩容方式。
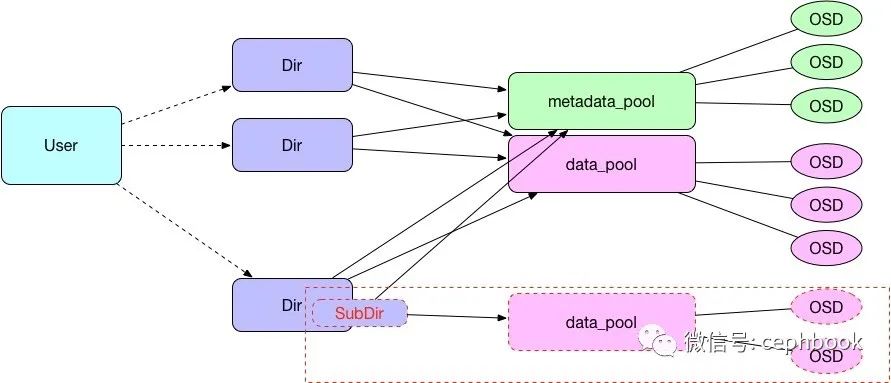
方案2. 子目录扩容
如果业务侧只能在原有主目录中进行操作,则可以通过在原有主目录下新增一个用户子目录,将新生成的子目录指向新的data_pool来实现扩容。
优点:新扩容的pool不会对现有存储服务造成影响。
缺点:业务需要能够适配这种新增子目录的扩容方式。
通过新增OSD进行扩容
基本原理
基于原生底层分布式存储的基本特性,可以在原有的pool里面新增OSD进行扩容,但是新增OSD会导致旧有数据重新平衡,造成性能波动,影响服务质量。
方案3. 原有data_pool扩容
通过在原有data_pool中新增OSD来实现扩容。
优点:业务和k8s层面不需要做任何变动,完全对上层透明。
缺点:旧集群在新增OSD的时候会发生性能抖动,同时为了兼顾扩容速率和减少业务影响,相对扩容周期会比较长。受限与机房机柜和网络设备环境,有物理层面的上限。
方案4. 新增ceph集群
受限于单集群规模存储集群的规模有限(受限机柜、网络等),单机房多集群、多机房多集群都会可能存在,因此这一块的存储扩容方案也会纳入设计范围。
优点:适配现有的单集群部署方案(1个集群跨3个机柜),相对来讲容易做故障域隔离(鸡蛋不放一个篮子里).扩容新集群不会对现有存储服务造成影响。
缺点:需要业务能够适配这种跨集群模型(跨集群的目录数据不能互通),单个docker里面最好不要同时挂载两个以上集群的目录。k8s的存储资源调度复杂度上升,需要支持多集群。