
盘点一个Python中字符串替换的问题
回复“资源”即可获赠Python学习资料
大家好,我是皮皮。
一、前言
前几天在Python白银交流群【凡人不烦人】问了一道Python字符串替换的题目,如下图所示。
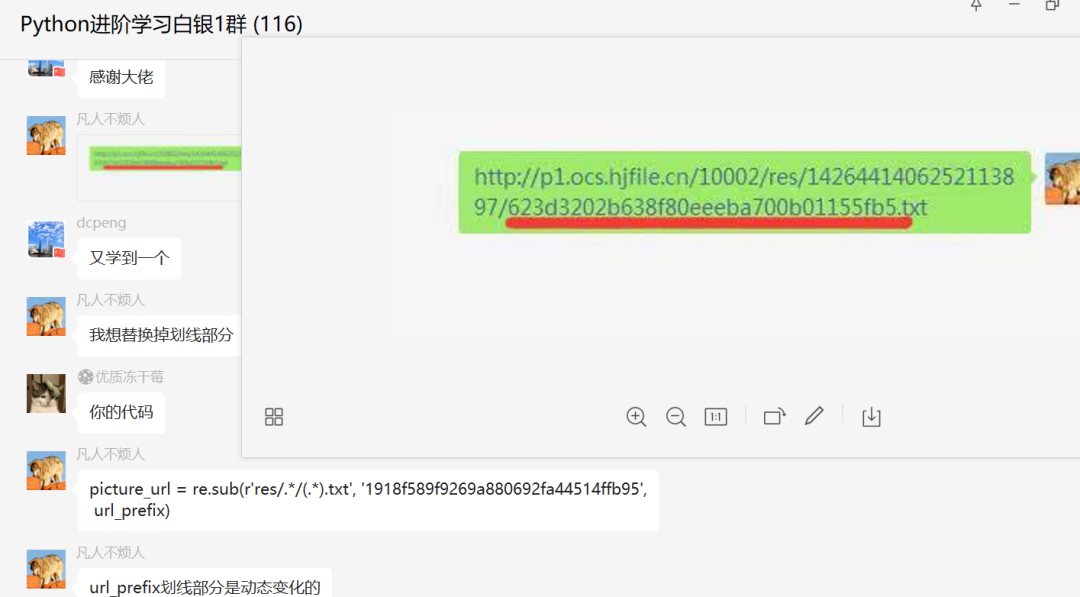
其实这个地方倒是可以用字符串替换或者正则表达式替换的方法来解决,方法还是很多的。
二、实现过程
方法一
这里【dcpeng】给出了一个方法,如下所示:
new_url = url_prefix.split('1426441406252113897')[0] + '1426441406252113897/' + '1918f589f9269a880692fa44514ffb95.txt'
print(new_url)
结果如下图所示: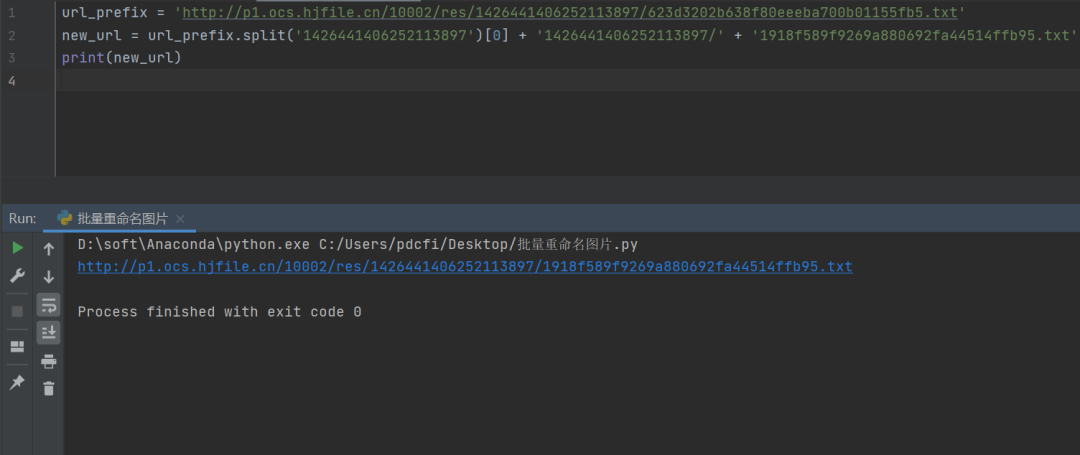
方法二
后来【dcpeng】又给了一个方法,如下所示:
import re
url_prefix = 'http://p1.ocs.hjfile.cn/10002/res/1426441406252113897/623d3202b638f80eeeba700b01155fb5.txt'
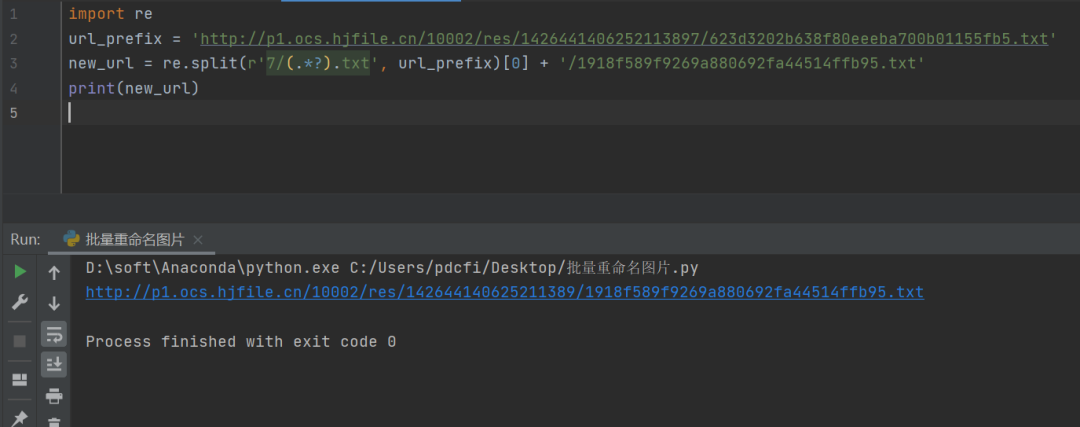
new_url = re.split(r'7/(.*?).txt', url_prefix)[0] + '/1918f589f9269a880692fa44514ffb95.txt'
print(new_url)
结果如下图所示:
方法三
前面两个方法都是需要进行字符串拼接的,有没有什么办法不拼接呢?答案是有的,一起来看看【dcpeng】给的一个代码,如下所示:
import re
url_prefix = 'http://p1.ocs.hjfile.cn/10002/res/1426441406252113897/623d3202b638f80eeeba700b01155fb5.txt'
result = re.findall(r'7/(.*?).txt', url_prefix)
print(result)
final_result = url_prefix.replace(result[0], '1918f589f9269a880692fa44514ffb95')
print(final_result)
结果如下图所示: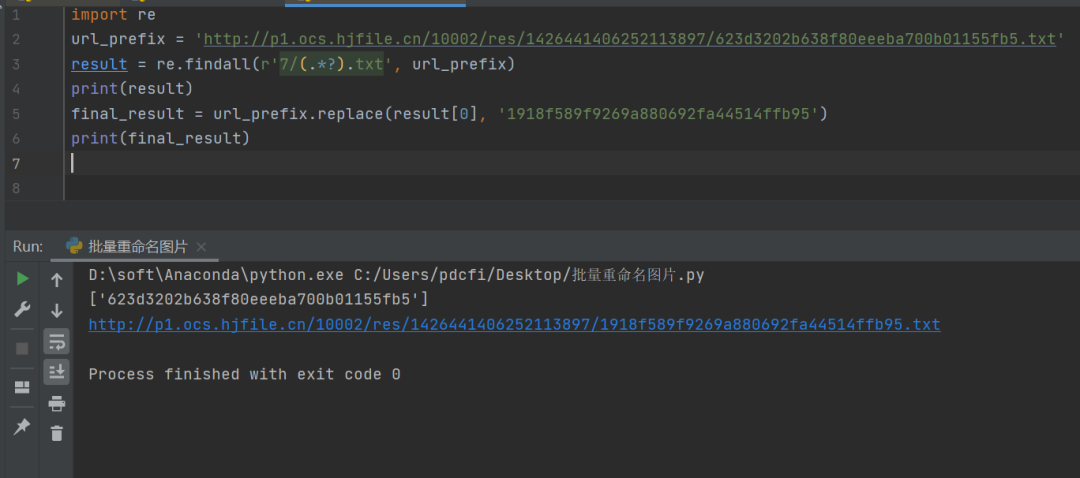 虽然这个确实可以解决该问题,但是这里会有一个小问题,就是健壮性不强,假如那个位置更改了,变成了不是
虽然这个确实可以解决该问题,但是这里会有一个小问题,就是健壮性不强,假如那个位置更改了,变成了不是7,就获取不到对应的数据了。
方法四
后来【瑜亮老师】用一个rsplit,然后字符串拼接就搞定了。代码如下所示:
url_prefix = 'http://p1.ocs.hjfile.cn/10002/res/1426441406252113897/623d3202b638f80eeeba700b01155fb5.txt'
tp = url_prefix.rsplit('/', 1)
new = '1918f589f9269a880692fa44514ffb95'
result = f'{tp[0]}/{new}.txt'
print(result)
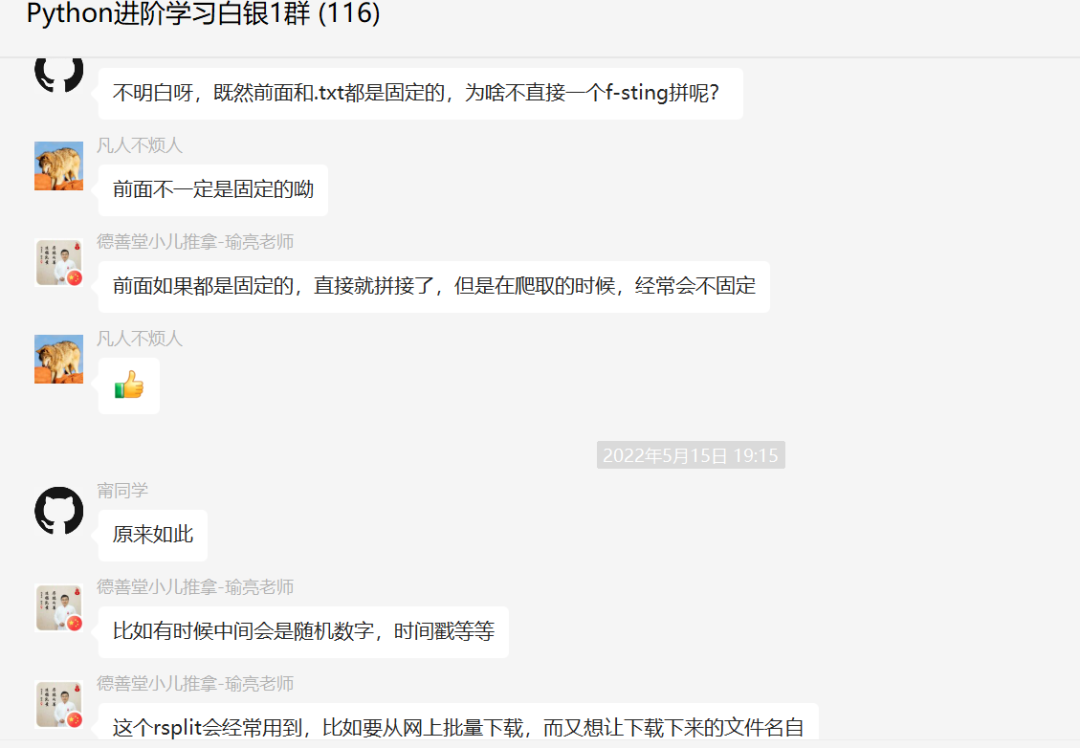
结果如下图所示: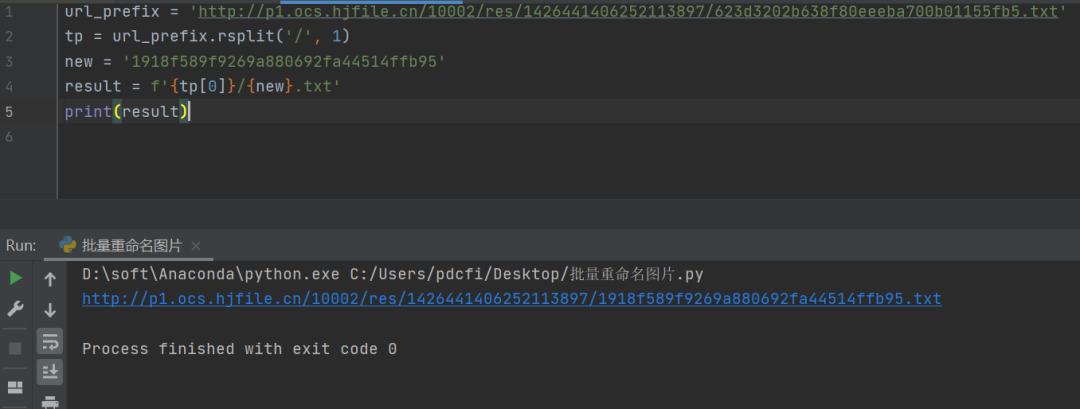 这里【瑜亮老师】多做了一些拓展,如下所示:
这里【瑜亮老师】多做了一些拓展,如下所示:
方法五
后来【月神】给了一个正则表达式的re.sub()方法,代码如下所示:
import re
picture_url = 'http://p1.ocs.hjfile.cn/10002/res/1426441406252113897/623d3202b638f80eeeba700b01155fb5.txt'
new = '1918f589f9269a880692fa44514ffb95'
print(picture_url)
re.sub('(res/.*?)/.*?(\.txt)', fr'\g<1>/{new}\g<2>', picture_url)
结果如下图所示: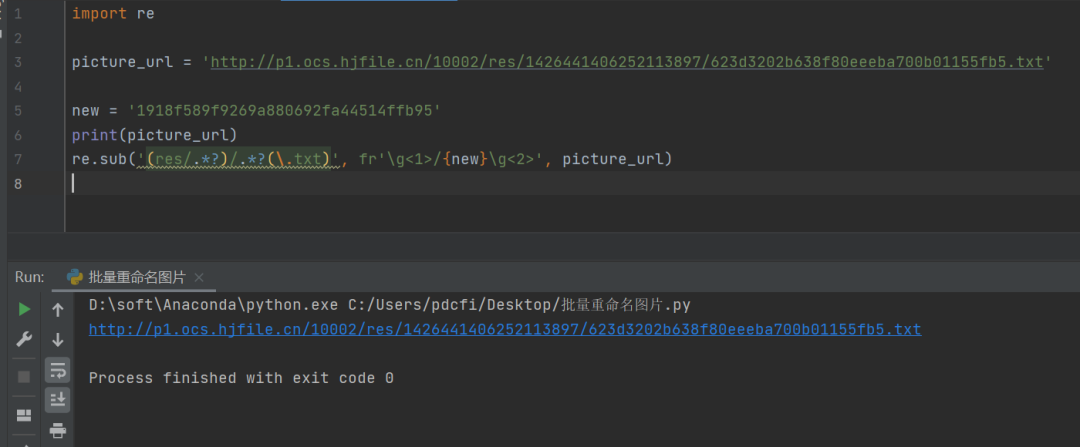 不得不承认,这个正则表达式还是写的挺复杂的,有点难懂。
不得不承认,这个正则表达式还是写的挺复杂的,有点难懂。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一道Python中字符串替换的问题,文中针对该问题给出了具体的解析和代码演示,一共5个方法,帮助粉丝顺利解决了问题。
最后感谢粉丝【凡人不烦人】提问,感谢【月神】、【瑜亮老师】、【dcpeng】给出的代码和具体解析,感谢【猫药师Kelly】、【冫马讠成】、【甯同学】、【哈佛在等我呢~】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行