
(附论文)MicroNet:比MobileNetv3更小更快的网络
点击左上方蓝字关注我们

链接 | https://zhuanlan.zhihu.com/p/337107958
MicroNet: Improving Image Recognition with Extremely Low FLOPs(2020)
论文地址:https://arxiv.org/pdf/2108.05894.pdf
Summary
1.Motivation
本文设计了计算量(FLOPs)超级无敌少的图像识别网络MicroNet,同时还具有较好的性能表现。主要的遵循以下两个设计原则:
降低网络节点(神经元)之间的连通性而不降低网络的宽度
使用更复杂的非线性激活函数来弥补通性网络深度的减少所带来的精度损失
2.Methods
本文设计的MicroNet主要是在MobileNet系列上进行改进和对比,提出了两项改进方法:
Micro-Factorized convolution 将MobileNet中的point-wise卷积以及depth-wise卷积分解为低秩矩阵,从而使得通道数目和输入输出的连通性得到一个良好的平衡。
Dynamic Shift-Max 使用一种新的激活函数,通过最大化输入特征图与其循环通道偏移之间的多重动态融合,来增强非线性特征。之所以称之为动态是因为,融合过程的参数依赖于输入特征图。
3.Performance
作者使用Micro-Factorized convolution和Dynamic Shift-Max建立了MicroNets家族,最终实现了低FLOPs的STOA表现。MicroNet-M1在ImageNet分类任务上仅仅用12 MFLOPs的计算量,就实现了61.1%的top1准确度,比MobileNetV3要强11.3% .

Keywords
Design Principles
Micro-FactorizedConvolution
Dynamic Shift-Max
Micro-Net Architecture
Introduction
1.Design Principles
要想实现低FLOPs,主要是要限制网络宽度(通道数)和网络深度(网络层数)。如果把一个卷积层抽象为一个图,那么该层输入和输出中间的连接边,可以用卷积核的参数量来衡量。因此作者定义了卷积层连通性(connectivity)的概念,即每个输出节点所连接的边数。如果我们把一个卷积层的计算量设为固定值,那么更多的网络通道数就意味着更低的连通性(比如深度可分离卷积,具有较多的通道数但是有很弱的连通性)。作者认为平衡好通道数目和连通性之间的关系,避免减少通道数,可以有效地提升网络的容量。除此之外,当网络的深度(层数)大大减少时,其非线性性质会受到限制,从而导致明显的性能下降。因此,作者提出以下两个设计原则:
通过降低节点连接性来避免网络宽度的减小
作者是通过分解points-wise卷积以及depth-wise卷积来实现如上原则。
增强每一层的非线性性质来弥补网络深度减少所带来的损失
作者是通过设计了一个全新的激活函数来实现如上原则,称为Dynamic Shift-Max
2. Micro-Factorized Convolution
作者将pointwise卷积和depthwise卷积分解为更为合适的尺度,用来平衡通道数目和输入输出连通性。
Micro-Factorized Point-wise Convolution
将point-wise卷积进行分解,原文给出的公式较为复杂,我这里直接对图进行讲解。假设输出和输出通道数都为C。对于常规的点卷积,其实就是一个C*C的实矩阵W(C维到C维的线性变换)。
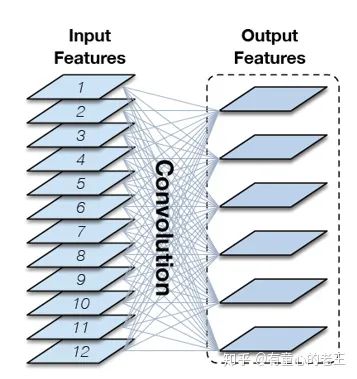
但是这样的点卷积是一种稠密的全连接,在这就带来巨大的计算负担。为了进一步减少计算量,提升网络的稀疏性(降低连通性),作者将原始的稠密矩阵W分解为3个更加稀疏的矩阵。
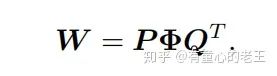
如上图所示,W为
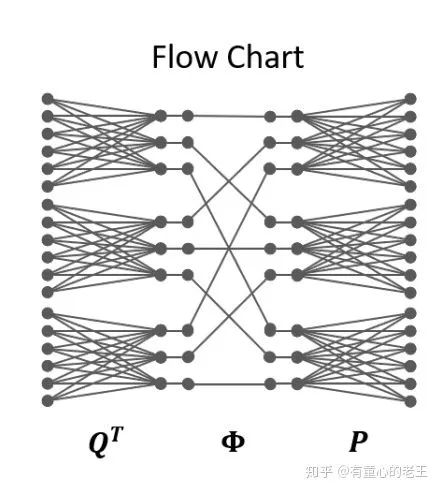
如上图所示,我们把一个特征图(通道)当作一个节点,输入和输出都是C=18个节点, 压缩率 R=2, 分组数 G=3。原始点卷积就需要一个18*18的实矩阵实现变换。作者将原始的点卷积操作分为3步:
将18个节点映射到9个节点(压缩率为2),分三组卷积,因此每组需要一个6*3的矩阵。
将9个节点使用置换矩阵,进行重新排序。
将9个节点分三组,映射回18个节点,每组需要一个3*6的矩阵。
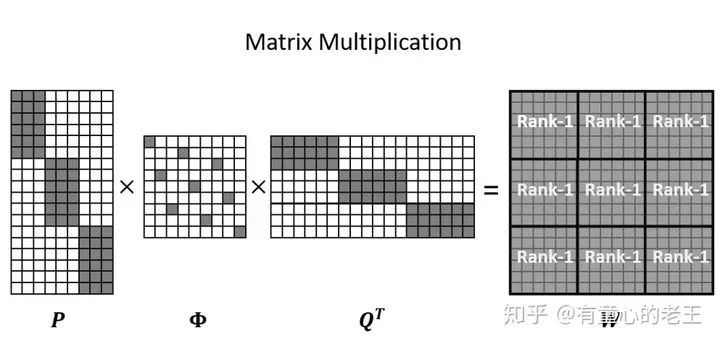
如上图所示,上图即为计算过程中矩阵的形态,其中P和Q为对角块矩阵,
Micro-Factorized Depth-wise Convolution
对于depth-wise卷积的分解,就是常规的空间可分离卷积,即将一个K*K的卷积核分解为两个K*1和1*K的向量。

将Micro-Factorized Pointwise Convolution和Depth-wise Convolution结合起来,得到Lite Combination。其并非是简单地将depthwise和pontwise卷积拼在一起,而是先用depthwise进行expand(通道数增加),再使用pointwise进行squeeze(通道压缩),这样可以节省更多的计算资源用到depthwise上,而非通道融合的pointwise上。
3. Dynamic Shift-Max
假设
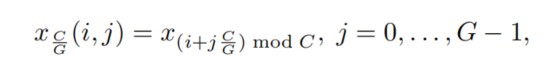
则引入动态最大偏移函数(Dynamic Shift-Max)如下:
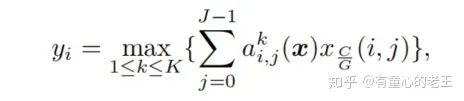
其中
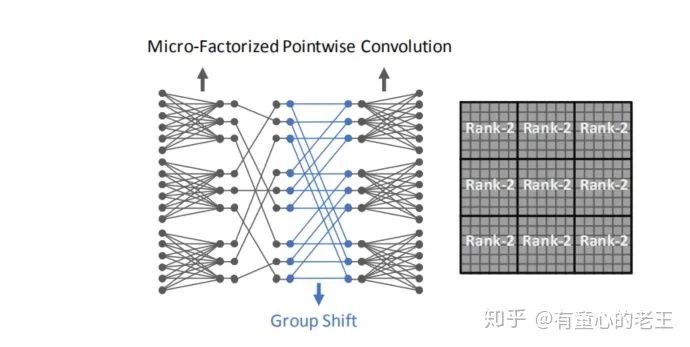
如上图所示,使用Dynamic Shift-Max改装后的Micro-Factorized Pointwise Convolution(K=1,J=2),在置换矩阵之后又添加了Group Shift映射,实现2个通道的信息融合(每个节点都来自两个不同组节点的映射)。通过添加Dynamic Shift-Max激活函数,卷积矩阵W中9个子矩阵块的秩从1上升到了2,提高了连通性。
4. Micro-Net Architecture
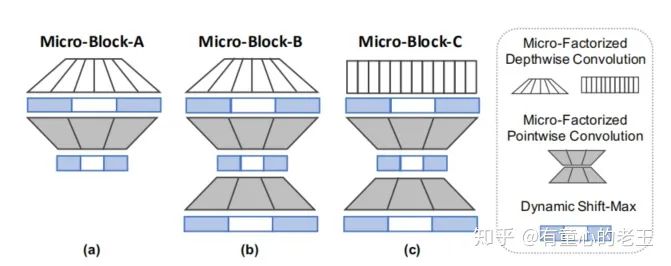
作者介绍了3种不同MicroNet模型,其计算量FLOPs从6M到44M.它们都是由 Micro-Factorized Pointwise Convolution 和 Micro-Factorized Depth-wise Convolution以不同的形式组合而来,并且它们都使用Dynamic Shift-Max作为激活函数。
Comments
最开始入坑计算机视觉,我是先埋头研究压缩神经神经网络(轻量化神经网络设计)。我是一个很矛盾的一个人,当初决定读博是因为觉得当一个码农每天做一些重复性的机械工作实在是没有什么意思。我想要去勘探人类智慧的高峰,去做一些开创性的工作。我当初尤其对深度学习所谓的黑箱认识十分不满意,对于深度学习从业者被称为炼丹师的污名感到诧异。于是我立志发掘出深度学习“最核心的本质”,妄想建立一个能够解释炼丹种各种现象的“终极理论”。从此之后各种超参数的选择,模型网络的设计不再那么依赖经验和实验。
但是学习了一段之后,我就发现自己的无知和渺小。我之前所鄙夷的“不够本质、不够基础,只面向应用的研究”,也是并非浅薄,相反也处处透露出智慧的锋芒,我也不能完全理解。我渐渐了解到目前深度学习或者计算机视觉主要的问题并非是模型精度不够高,而是过于理论化,太脱离实际,只能是实验室里面的玩具。
于是我选择轻量化网络设计这个方向,一方面它是模型落地的关键性技术(不再需要实验室里强劲算力的服务器)。另一方面,它是一件更具有挑战性的工作。人类的大脑种神经元的连接时非常稀疏的,其容量和参数应该不会太多。而我们粗暴地增加网络容量和深度,里面应该是存在大量的冗余。研究清楚如何设计出轻量又高效的网络,也许就能更接近我之前所幻想的“终极理论”。
这篇论文主要的创新点:
通过分解卷积核,进一步压缩网络的连接性,使得网络更加稀疏化,提高计算性能。
设计了全新的动态激活函数,引入更多的非线性特征,增强模型表现力。
Reference
[1] Micro-Net: Towards Image Recognition with Extremely Low FLOPs
[2]Mobile-Nets: Efficient Convolutional Neural Networks for Mobile Vision Applications
[3]Shuffle-Net: An Extremely Efficient Convolutional Neural Network for Mobile Devices
[4]Squeeze-and-Excitation Networks
END
点赞三连,支持一下吧↓