
现代数据中心SmartNIC/DPU 的演变
链接:https://www.linkedin.com/pulse/evolution-smartnicsdpus-modern-data-centers-sharada-yeluri?trk=public_post-content_share-article



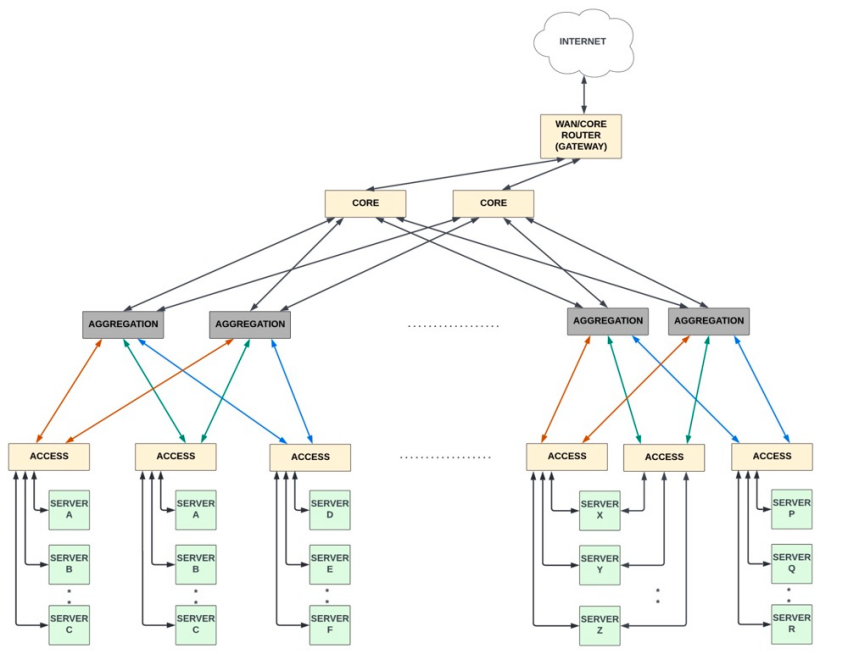
三层架构
两层或Spine-Leaf架构
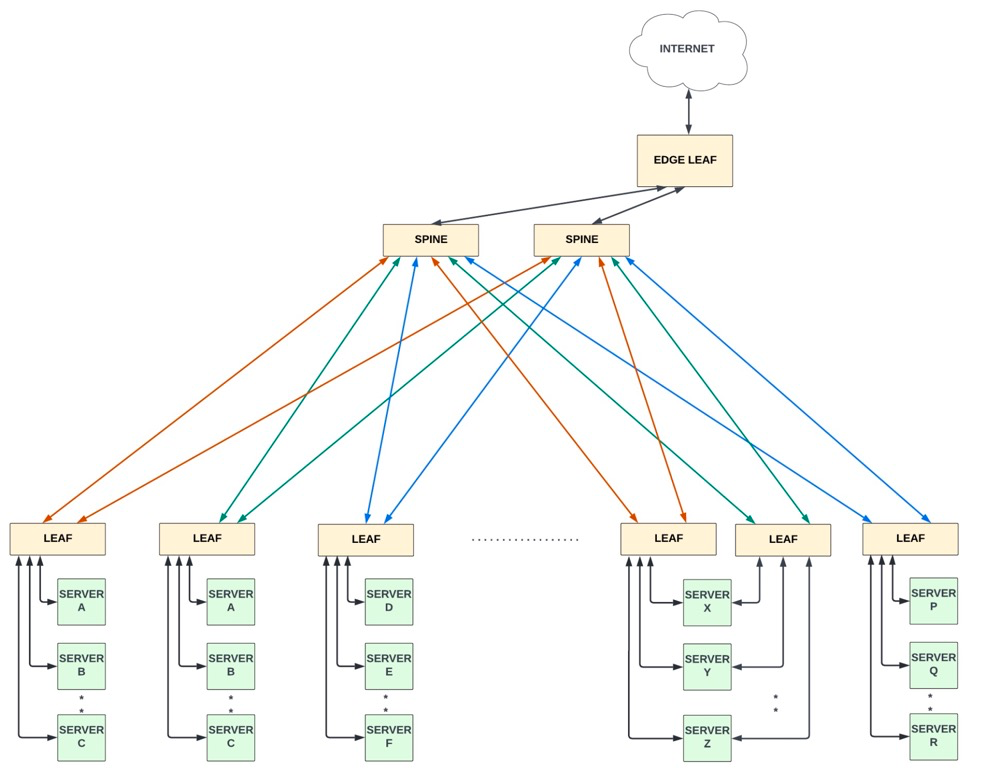
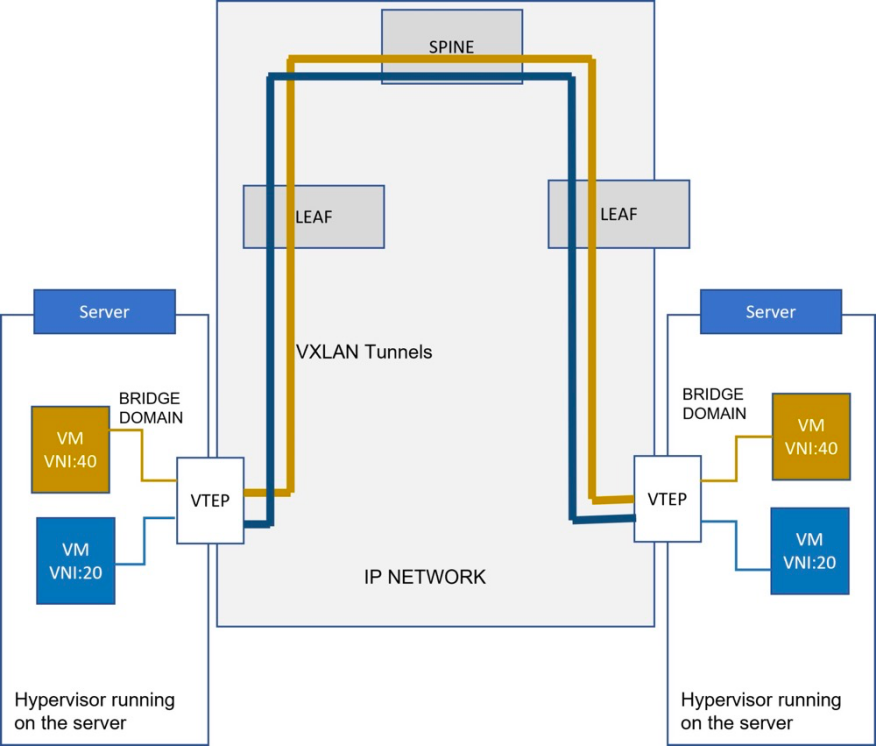
两台服务器之间的东西向流量最多有四个跃点 (host-leaf-spine-leaf-host),这有助于减少总体延迟和功耗。
简化了中间层,与三层相比,拓扑中的网络设备更少。
可以独立添加Leaf和Spine设备,以增加网络容量,有时被称为“横向扩展”架构。




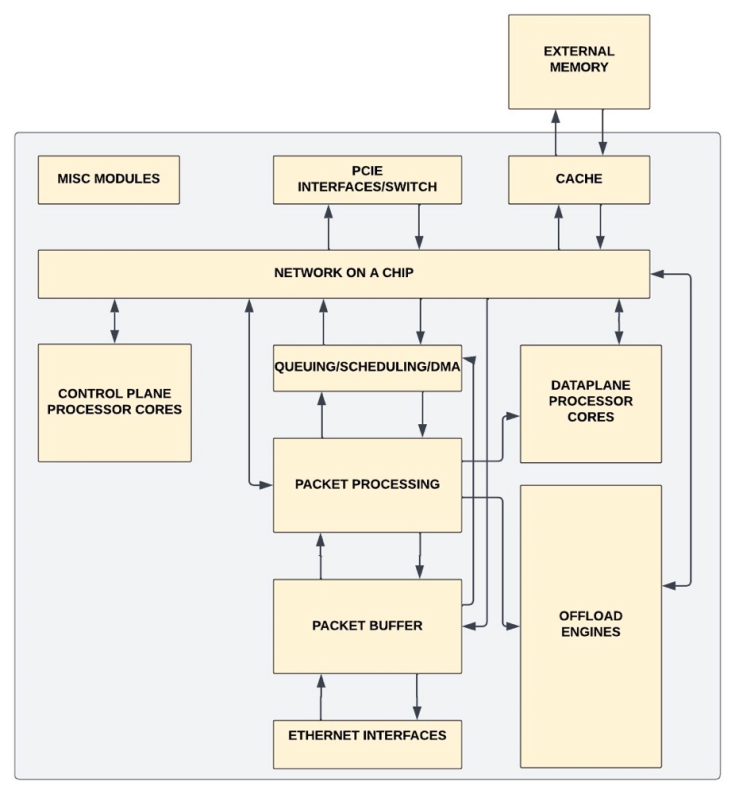
以太网接口
与主机之间的 PCIe 接口
数据包转发
TCP 基本功能
TCP 校验和卸载
CP 报头有一个校验和字段,DPU 可以计算校验和并将错误标记给 CPU。
TCP 分段卸载
CPU 可以将大数据块与报头模板一起发送给 DPU。DPU 对数据包进行分段,并在每个分段中添加以太网/IP 和 TCP 报头。
TCP Large Receive Offload
DPU 可以收集单个流的多个 TCP 报文,并将它们发送到 CPU,以便 CPU 不必处理许多小报文。
Receive Side scaling
DPU 可以通过对五元组进行哈希来确定数据包的流。属于不同流的数据包可以到达 CPU 的不同内核。这减少了单个 CPU 线程上的负载。
流表
安全功能
加密/解密
DPU 支持 VPN 终端,可对加密的VPN流量进行在线加/解密和IPsec认证。
防火墙/ACL
现代数据中心依赖于分布式防火墙,防火墙可以通过数据平面处理器内核或卸载引擎来加速。不同的DPU 具有不同的防火墙功能。通常,厂商提供静态数据包过滤、访问控制列表 (ACL) 和 NAT。
TLS 加密/解密
传输层安全 (TLS) 对应用层流量进行加密,使黑客无法窃听/篡改敏感信息。它运行在 TCP 之上,最初用于加密 HTTP 会话——Web 应用程序和服务器之间的流量。最近,许多运行在 TCP 上的应用程序也开始使用 TLS 来实现端到端安全。TLS 也可以运行在 UDP 之上,称为 DTLS协议。某些 DPU 提供代理 TCP/TLS 服务,用于终止 TCP 会话、解密 TLS 加密流量,以及在将流量发送到主机处理器之前对其进行身份验证。TCP/TLS 卸载通常通过专用硬件和处理器内核的组合来完成。
控制平面的处理器内核
Cross-Bar或NoC
QoS/流量整形
DMA 引擎
存储功能
负载均衡器

最近很多小伙伴找我要一些程序员必备资料,于是我翻出了压箱底的宝藏,免费分享给大家!
扫描海报二维码免费获取。