深入理解word2vec
Author:louwill
From:深度学习笔记
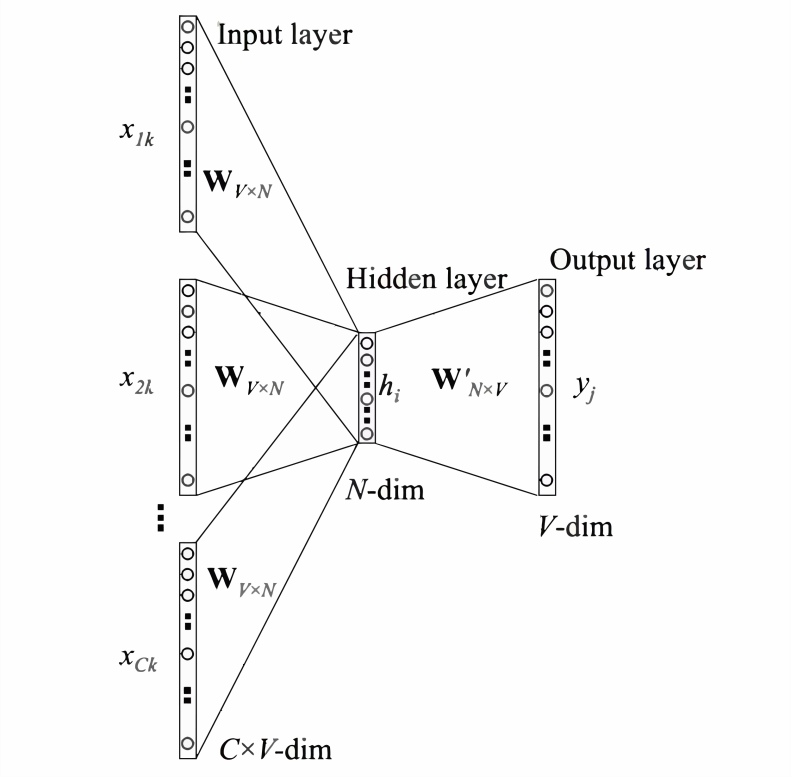
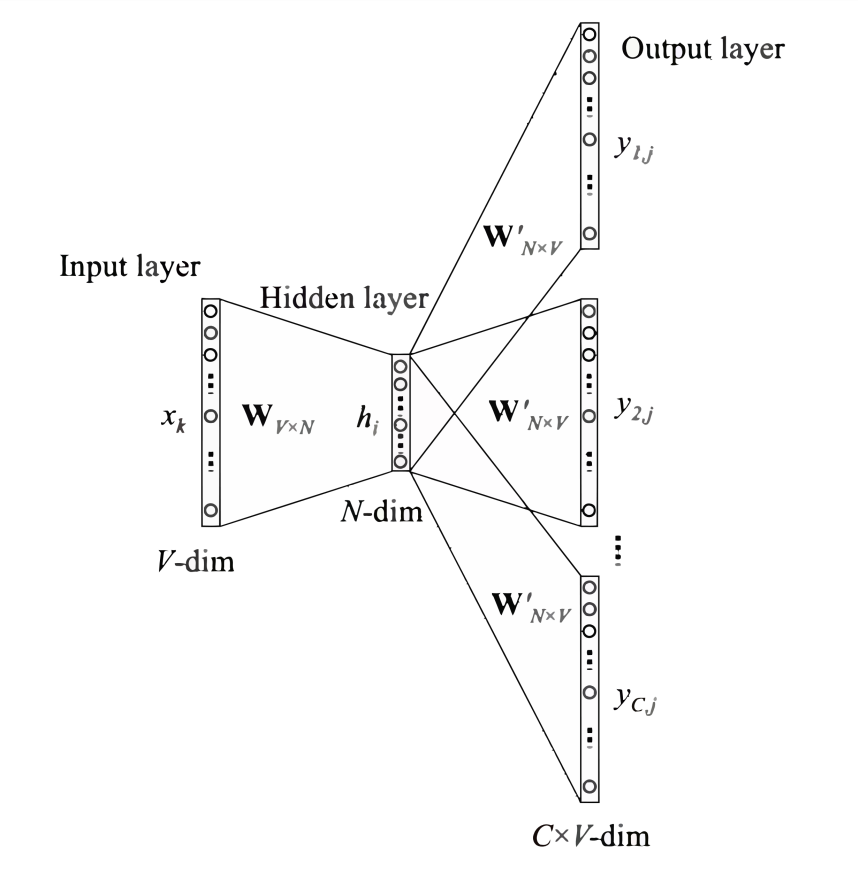
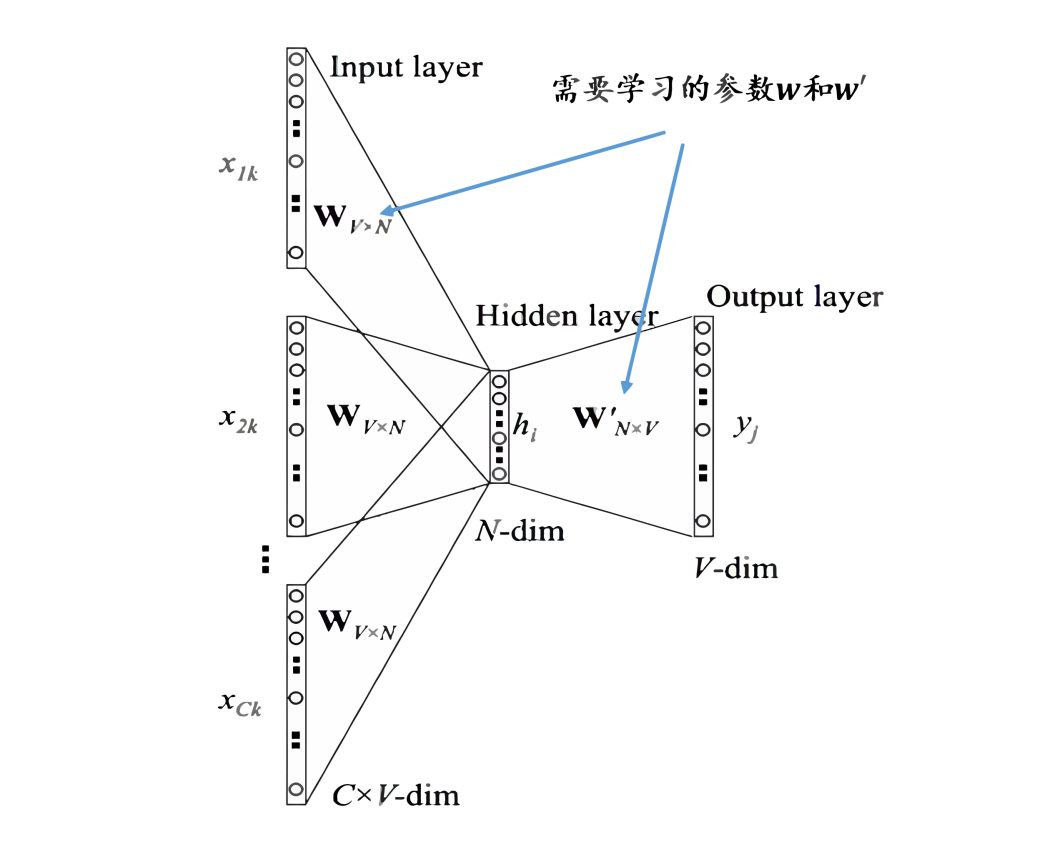
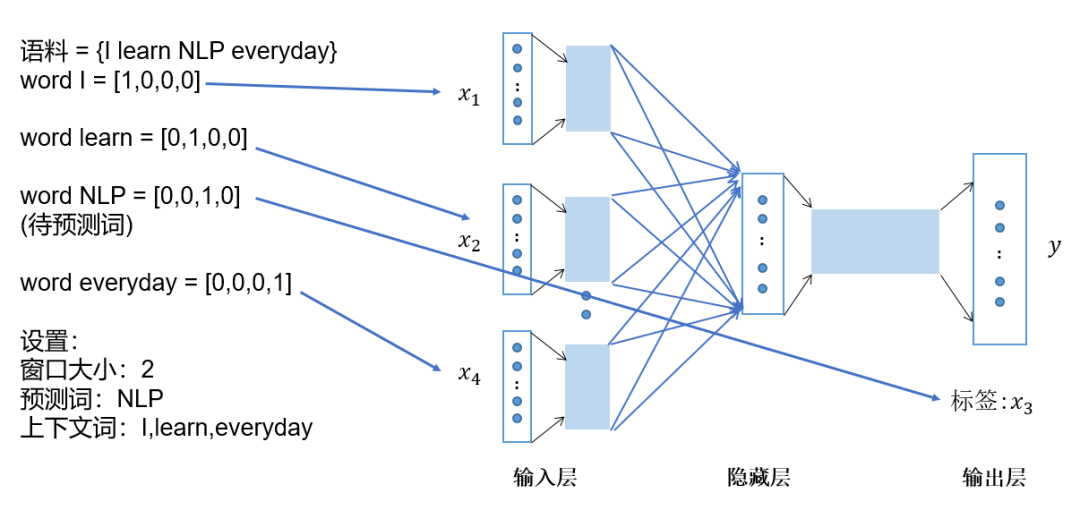
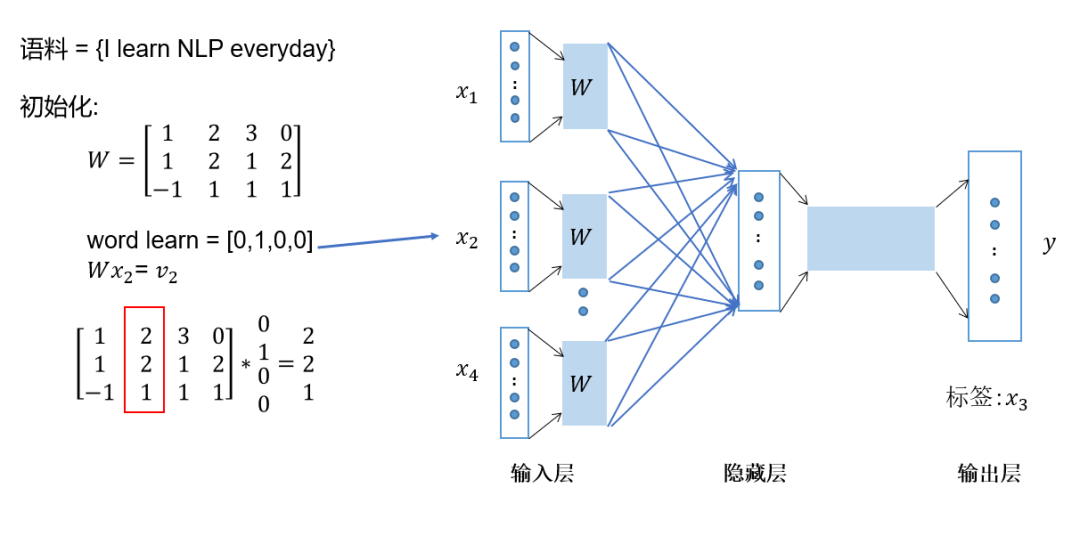
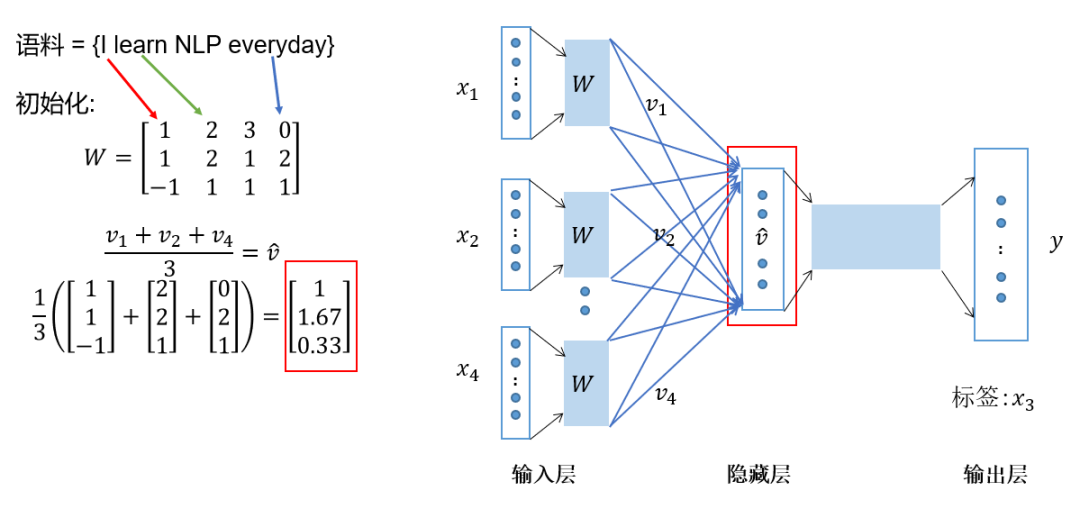
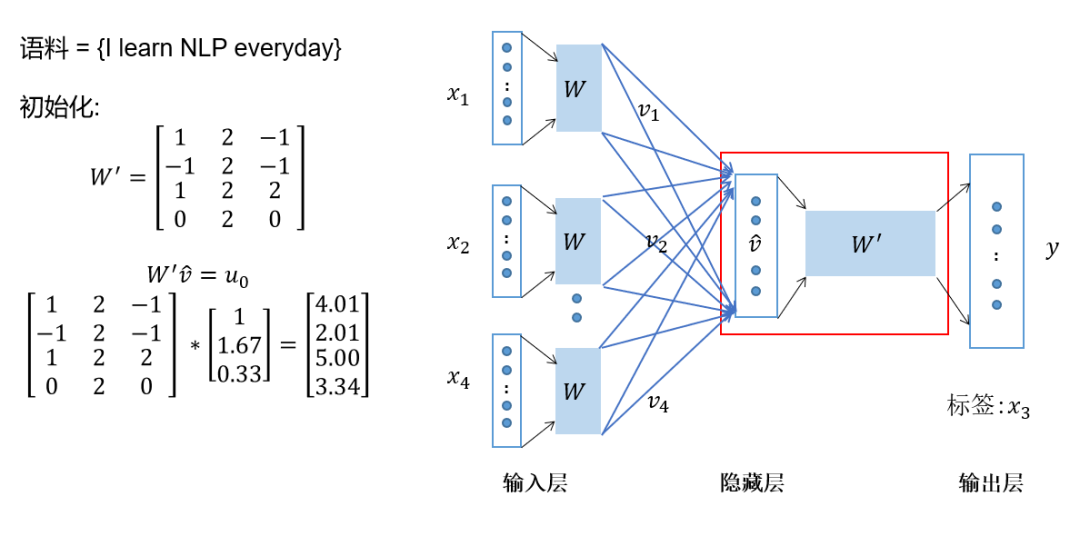
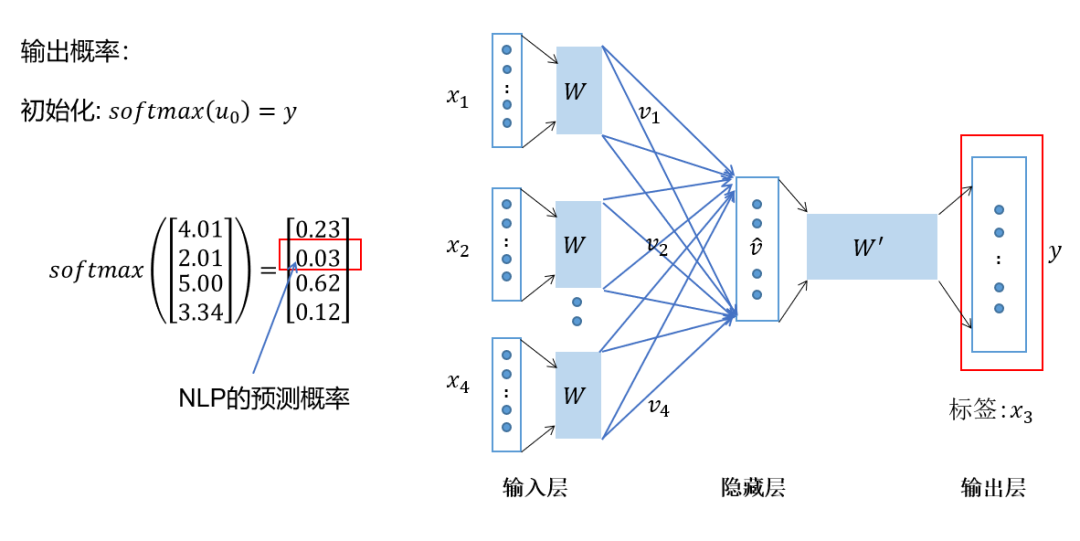
将上下文词进行one-hot表征作为模型的输入,其中词汇表的维度为,上下文单词数量为; 然后将所有上下文词汇的one-hot向量分别乘以共享的输入权重矩阵; 将上一步得到的各个向量相加取平均作为隐藏层向量; 将隐藏层向量乘以共享的输出权重矩阵; 将计算得到的向量做softmax激活处理得到维的概率分布,取概率最大的索引作为预测的目标词。
往期精彩:

喜欢您就点个在看!
评论
 下载APP
下载APPAuthor:louwill
From:深度学习笔记
往期精彩: