点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来源:机器之心
CVPR 2020 会议上,有哪些目标检测论文值得关注?
目标检测是计算机视觉中的经典问题之一。凭借大量可用数据、更快的 GPU 和更好的算法,现在我们可以轻松训练计算机以高精度检测出图像中的多个对象。前不久结束的 CVPR 2020 会议在推动目标检测领域发展方面做出了一些贡献,本文就为大家推荐其中 6 篇有价值的目标检测论文。
A Hierarchical Graph Network for 3D Object Detection on Point Clouds
HVNet: Hybrid Voxel Network for LiDAR Based 3D Object Detection
Point-GNN: Graph Neural Network for 3D Object Detection in a Point Cloud
Camouflaged Object Detection
Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector
D2Det: Towards High-Quality Object Detection and Instance Segmentation
1. A Hierarchical Graph Network for 3D Object Detection on Point Clouds
论文地址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Chen_A_Hierarchical_Graph_Network_for_3D_Object_Detection_on_Point_CVPR_2020_paper.pdf 这项研究提出了一种基于图卷积 (GConv) 的新型层次图网络 (HGNet),它用于三维目标检测任务,可直接处理原始点云进而预测三维边界框。HGNet 能够有效捕获点之间的关系,并利用多级语义进行目标检测。具体而言,该研究提出了新的 shape-attentive GConv (SA-GConv),它能通过建模点的相对几何位置来描述物体的形状,进而捕获局部形状特征。基于 SA-GConv 的 U 形网络捕获多层次特征,通过改进的投票模块(voting module)将这些特征映射到相同的特征空间中,进而生成候选框(proposal)。该研究提出的模型主要以 VoteNet 作为 backbone,并基于它提出了一系列改进。由下图可以看出:将 VoteNet 中的 PointNet++ 换成特征捕捉能力更强的 GCN;
为 up-sample 的多层中的每一层都接上 voting 模块,整合多个尺度的特征;
在 proposal 之间也使用 GCN 来增强特征的学习能力。
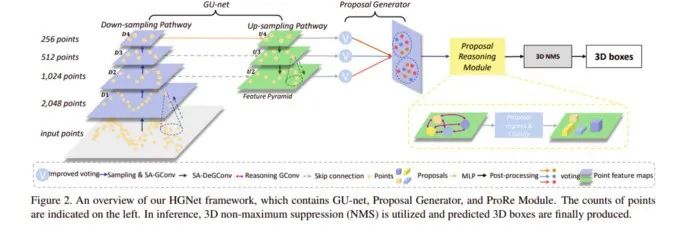
本文提出了 Shape-attentive Graph Convolutions(SA-GConv),并且将这个卷积同时用在了 down-sampling pathway 和 up-sampling pathway 中。本文提出了一个 Proposal Reasoning Module,在 proposal 之间学习其特征之间的交互。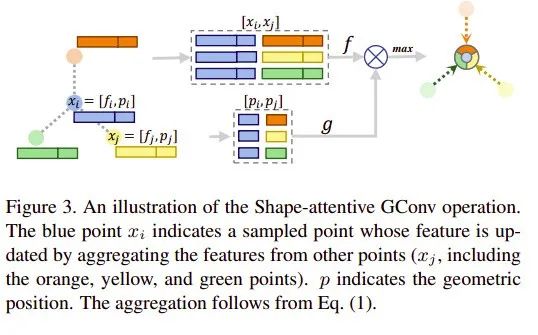
不同模型在 SUN RGB-D V1 数据集上的实验结果如下所示: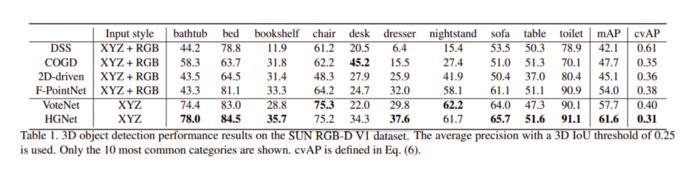
2. HVNet: Hybrid Voxel Network for LiDAR Based 3D Object Detection
论文地址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Ye_HVNet_Hybrid_Voxel_Network_for_LiDAR_Based_3D_Object_Detection_CVPR_2020_paper.pdf这篇论文提出了一种基于点云的自动驾驶三维目标检测 one-stage 网络——混合体素网络 (Hybrid Voxel Network, HVNet),通过在点级别上混合不同尺度的体素特征编码器 (VFE) 得到更好的体素特征编码方法,从而在速度和精度上得到提升。
HVNet 采用的体素特征编码(VFE)方法包括以下三个步骤:
该研究提出的 HVNet 架构包括:HVFE 混合体素特征提取模块;2D 卷积模块;以及检测模块,用来输出最后的预测结果。

不同模型在 KITTI 数据集上获得的结果如下表所示: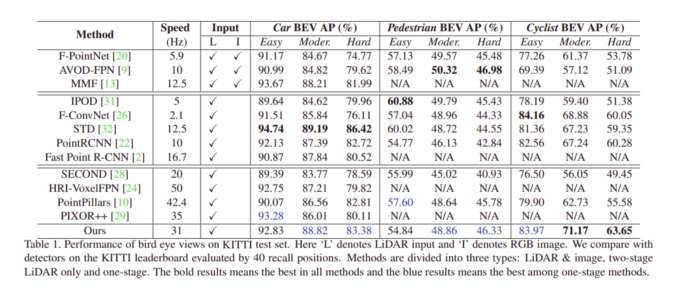
3. Point-GNN: Graph Neural Network for 3D Object Detection in a Point Cloud
基于点云的 3D 目标检测具有非常重要的应用价值,尤其是在自动驾驶领域。使用激光雷达传感器获得的 3D 点云数据描述了周围环境,使得 3D 目标检测能够比单纯使用 RBG 摄像头提供更多的目标信息(不仅有位置信息,还有距离信息)。该研究指出,以往使用 CNN 的方法处理点云数据时往往需要在空间划分 Grids,会出现大量的空白矩阵元素,并不适合稀疏点云;近来出现的类似 PointNet 的方法对点云数据进行分组和采样,取得了不错的结果,但计算成本太大。于是该研究提出一种新型 GNN 网络——Point-GNN。Point-GNN 方法主要分为三个阶段,如下图所示:图构建:使用体素降采样点云进行图构建;
GNN 目标检测(T 次迭代);
边界框合并和评分。

以下是不同模型在 KITTI 数据集上获得的结果: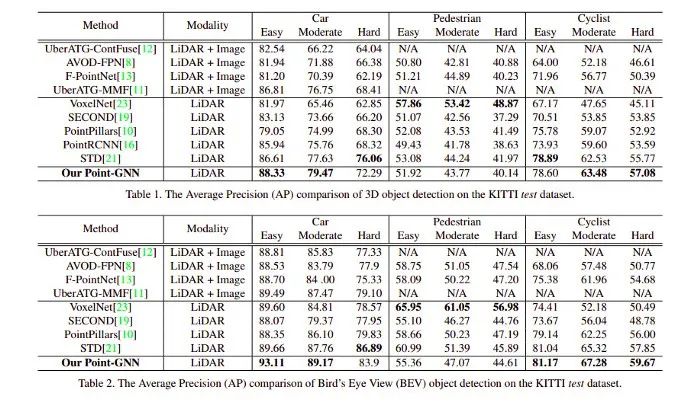
4. Camouflaged Object Detection
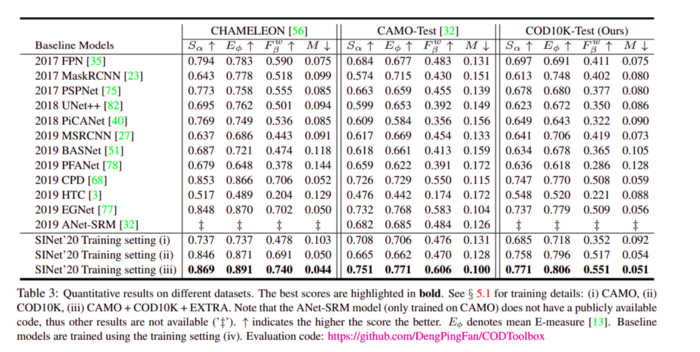
这篇论文解决的问题是:如何检测嵌入在周围环境中的物体,即伪装目标检测(camouflaged object detection,COD)。 此外,该研究还创建了一个名为 COD10K 的新型数据集。它包含 10,000 张图像,涵盖许多自然场景中的伪装物体。该数据集具有 78 个类别,每张图像均具备类别标签、边界框、实例级标签和抠图级(matting-level)标签。下图展示了 COD10K 数据集中的样本示例及其难点。

为了解决伪装目标检测问题,该研究提出了一种叫做搜索识别网络(Search Identification Network,SINet)的 COD 框架。搜索模块(SM),用于搜索伪装的物体;
识别模块(IM),用于检测该物体。

5. Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector
论文地址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Fan_Few-Shot_Object_Detection_With_Attention-RPN_and_Multi-Relation_Detector_CVPR_2020_paper.pdf传统的目标检测算法需要大量数据标注才能训练模型,而数据标注不但耗费人力,可能还会因为标注质量而影响训练效果。这篇论文提出了一种「小样本」目标检测网络,旨在通过少量标注数据使模型有效检测到从未见过的目标。该方法的核心包括三点:Attention-RPN、Multi-Relation Detector 和 Contrastive Training strategy,利用小样本 support set 和 query set 的相似性来检测新的目标,同时抑制 background 中的错误检测。该团队还贡献了一个新的数据集,该数据集包含 1000 个类别,且具备高质量的标注。该研究提出一个新型注意力网络,能在 RPN 模块和检测器上学习 support set 和 query set 之间的匹配关系;下图中的 weight shared network 有多个分支,可以分为两类,一类用于 query set,另一类用于 support set(support set 的分支可以有多个,用来输入不同的 support 图像,图中只画了一个),处理 query set 的分支是 Faster RCNN 网络。
作者还提出用 Attention RPN 来过滤掉不属于 support set 的目标。
以下是不同模型在 ImageNet 数据集上的实验结果:

6. D2Det: Towards High-Quality Object Detection and Instance Segmentation
这篇论文提出了一种提高定位精度和分类准确率的方法 D2Det,以提升目标检测的效果。针对这两项挑战,该研究分别提出了 dense local regression(DLR)和 discriminative RoI pooling(DRP)两个模块。其中 DLR 与 anchor-free 方法 FCOS 的 detect loss 类似,DRP 则是利用了 deformable convolution 的思想,分别从第一阶段和第二阶段提取准确的目标特征区域,进而获得相应的性能提升。具体方法流程如下图所示: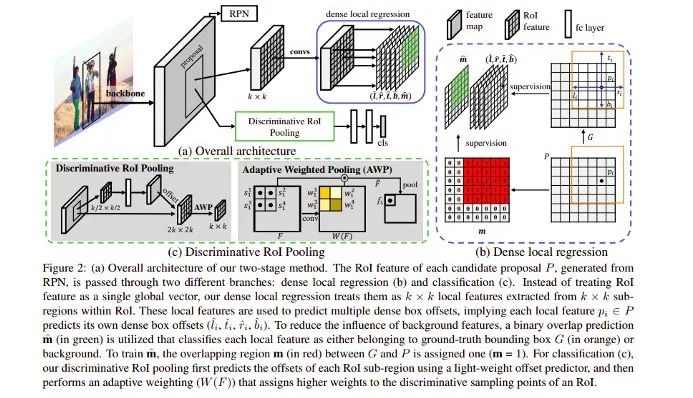
在这两个阶段中,第一阶段采用区域建议网络(RPN),而第二阶段采用分类和回归的方法,分类方法基于池化,局部回归则用于物体的定位。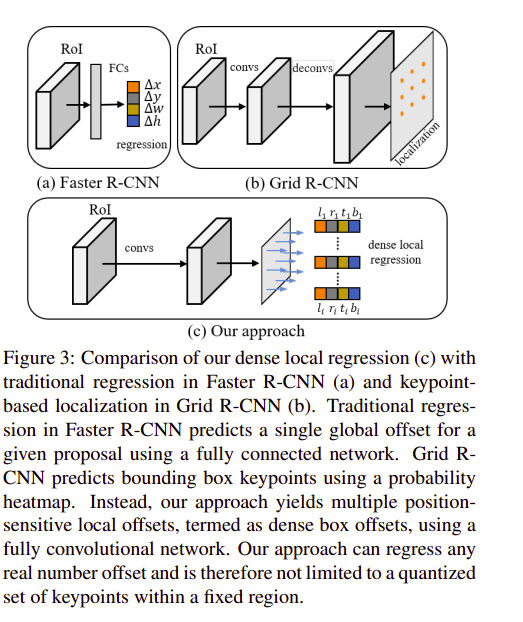
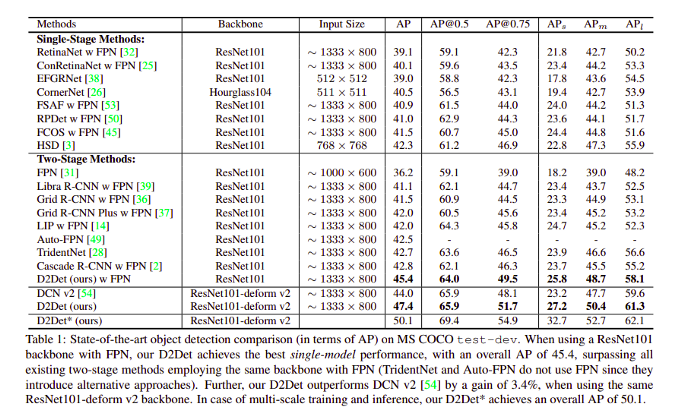
以下是不同模型在 MS COCO 数据集上的结果:
计算机视觉顶会 CVPR 2020 提供了很多目标检测等领域的研究论文,如果你想获取更多论文信息,请点击以下网址:https://openaccess.thecvf.com/CVPR2020。最后的最后求一波分享!
YOLOv4 trick相关论文已经下载并放在公众号后台
关注“AI算法与图像处理”,回复 “200714”获取

