
消息队列:消息可靠性、重复消息、消息积压、利用消息实现分布式事务
共 7683字,需浏览 16分钟
·
2021-07-17 11:08

- 如何确保消息不丢失 -
1、检测消息丢失的方法
如果是在一个分布式系统中实现这个检测方法,有几个问题需要注意:
2、确保消息可靠传递
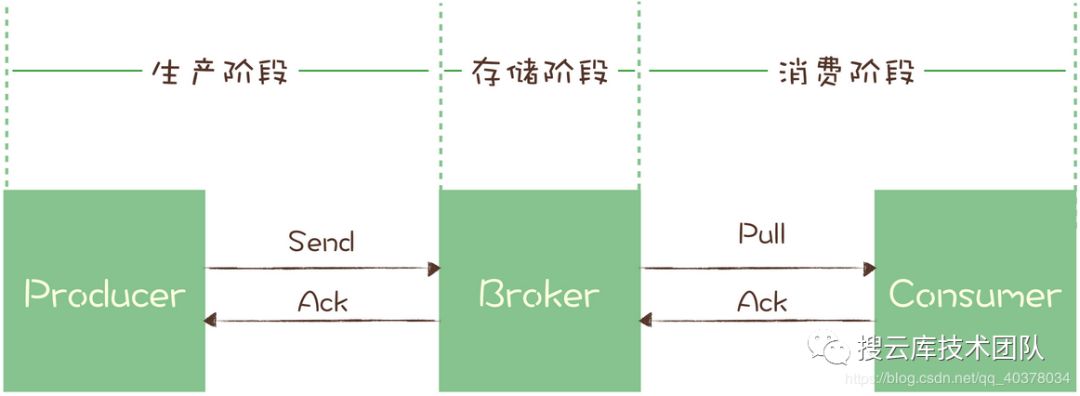
2.1、生产阶段
try{
producer.send(record).get();
System.out.println("消息发送成功");
} catch(Exception e) {
System.out.println("消息发送失败");
System.out.println(e);
}
异步发送时,则需要在回调方法里进行检查:
producer.send(record, newCallback() {
@Override
publicvoid onCompletion(RecordMetadata metadata, Exception exception) {
if(metadata != null) {
System.out.println("消息发送成功");
} else{
System.out.println("消息发送失败");
System.out.println(exception);
}
}
});
producer.send(record, (metadata, exception) -> {
if(metadata != null) {
System.out.println("消息发送成功");
} else{
System.out.println("消息发送失败");
System.out.println(exception);
}
});
2.2、存储阶段
2.3、消费阶段

- 小结 -
- 如何处理消费过程中的重复消息 -
1、消息重复的情况必然存在
2、用幂等性解决重复消息问题
几种常用的设计幂等操作的方法
- 如何处理消息积压? -
优化性能来避免消息积压
发送端准备数据、序列化消息、构造请求等逻辑的时间,也就是发送端在网络请求之前的耗时;
发送消息和返回响应在网络传输中的耗时;
Broker处理消息的时延。
消息积压了该如何处理?
- 利用事务消息实现分布式事务 -
这个过程中有一个需要用到消息队列的步骤,订单系统创建订单后,发消息给购物车系统,将已下单的商品从购物车中删除。因为从购物车删除已下单商品这个步骤,并不是用户下单支付这个主要流程中必需的步骤,使用消息队里来异步清理购物车是更加合理的设计。
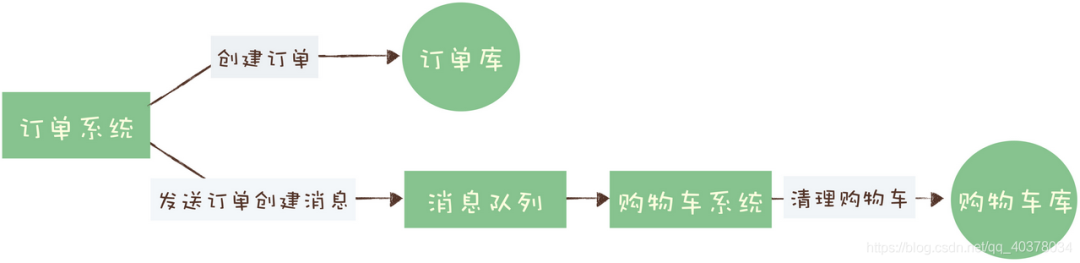
什么是分布式事务?
原子性:指一个事务操作不可分割,要么成功,要么失败,不能有一半成功一半失败的情况。
一致性:指这些数据在事务执行完成这个时间点之前,读到的一定是更新前的数据,之后读到的一定是更新后的数据,不应该存在一个时刻,让用户读到更新过程中的数据。
隔离性:指一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对正在进行的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
持久性:指一个事务一旦完成提交,后续的其他操作和故障都不会对事务的结果产生任何影响 事务消息适用的场景主要是那些需要异步更新数据,并且对数据实时性要求不太高的场景。比如订单系统的例子,在创建订单后,如果出现短暂的几秒,购物车里的商品没有及时情况,也不是完全不可接受的,只要最终购物车的数据和订单数据保持一致就可以了。
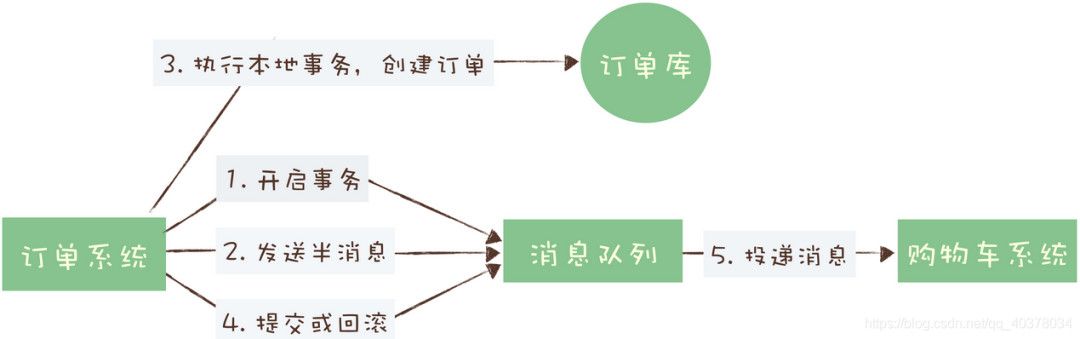
2、消息队列是如何实现分布式事务的?
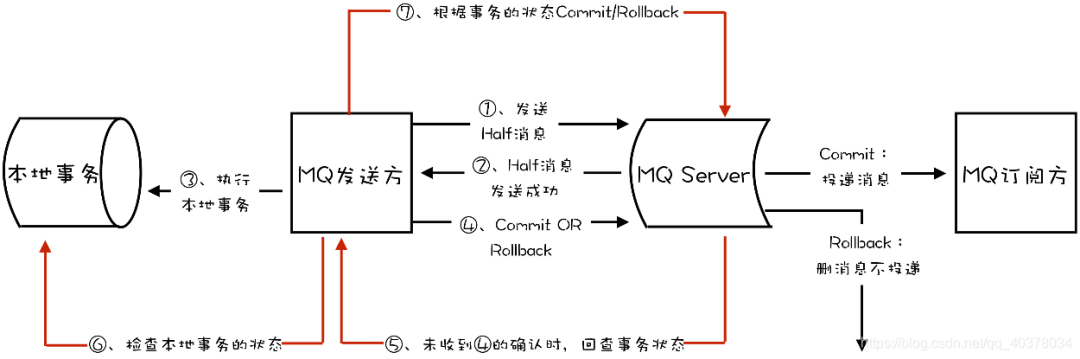
3、RocketMQ中的分布式事务实现
这种情况下,即使是发送事务消息的那个订单服务节点宕机了,RocketMQ依然可以通过其他订单服务的节点来执行反查,确保事务的完整性。
作者:邋遢的流浪剑客
来源:
https://blog.csdn.net/qq_40378034/article/details/98790433
