
全网第一个讲清楚CPK如何计算的,Step by step,Excel和Python同时实...
在网上搜索CPK的计算方法,几乎全是照搬教材的公式,在实际工作做作用不大,甚至误导人。
比如这个
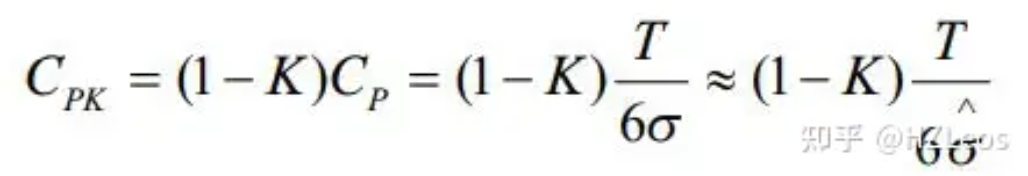 又比如这个:
又比如这个:
CPK=min((X-LSL/3s),(USL-X/3s)) 还有这个 , 很 规范的公式 ,也很清晰
主要是对组内σ的计算没有说清楚。
既然这样,今天我就和大家说说详细的CPK的计算过程,并且在excel中实现,同时也在python中实现,最后提供excel文件和python文件给大家下载。
数据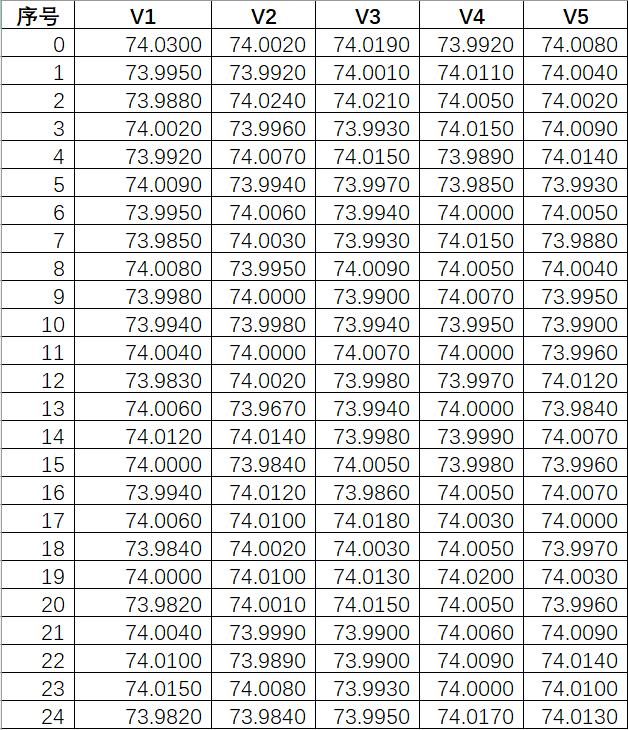
算法和EXCEL实现
CPK的算法不复杂,下面列出CP CPU CPL和CPK的计算,其实看起来上网上介绍的差不多,对,确实差不多。但网上说的基本上没有说清楚σ是怎么算的,我们这次就认真和大家分享一下σ的算法,并且和minitab用同一份数据核对。
CP = (USL-LSL)/3σ CPU = (USL-μ)/3σ
CPL=(μ-LSL)/3σ
CPK = min(CPU,CPL)
CPK就是从CPU和CPL中去最小一个值。 第一步:计算组内标准差 上面的μ是所有数据的平均数,这个很简单没有什么疑问的。USL和LSL是人工设定的一个规格限。那么这里就剩下σ如何计算了。 这里的σ我们称之为组内标准差,用σ组内表示,公式如下: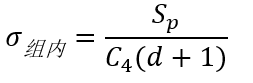 不急,我们一个一个参数来确定计算方法。
不急,我们一个一个参数来确定计算方法。
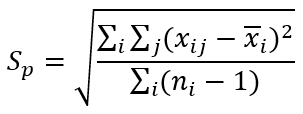
可能有一些朋友对这样的公式不太了解,我们详细解释一下,专家可以跳过。
看我们上面提供的数据,一个有25行数据,每行有5个值。
上面的公式就是计算每行的平均值,在每一行内,每个值分别和行平均值相减取平方,得到5个结果,25行得到125个结果,把这些结果求和,得到的是上述公式的根号里面的分子部分。 数据中每行5个 ni-1就是4,得到25个4,即100,得到的是上述公式的根号里面的分母部分。 最终sp =0.01002576680 接下来我们计算C4(d+1) d是自由度,d=100,即每行的5减去1得到4,25行*4=100
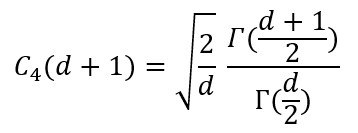 不用怕这个公式,我们代入数据看看
不用怕这个公式,我们代入数据看看
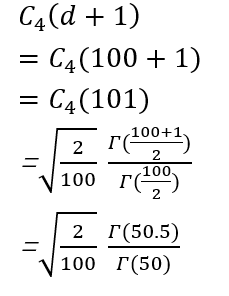 代入后的公式是很简单的,我们看看Γ(n)是怎么算的,这个gamma函数,我们手工是算不出来的,我们通过excel的函数来计算。
代入后的公式是很简单的,我们看看Γ(n)是怎么算的,这个gamma函数,我们手工是算不出来的,我们通过excel的函数来计算。
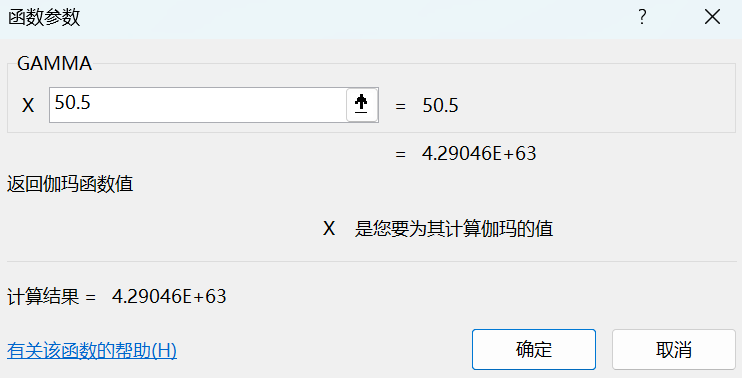 最终gamma(50.5)/gamma(50)= 7.053412515
最终gamma(50.5)/gamma(50)= 7.053412515
 最终分母部分等于0.997503164 σ组内 =0.01002576680/0.997503164 = 0.010050862 同一组数据,我们用minitab核对一下结果
最终分母部分等于0.997503164 σ组内 =0.01002576680/0.997503164 = 0.010050862 同一组数据,我们用minitab核对一下结果
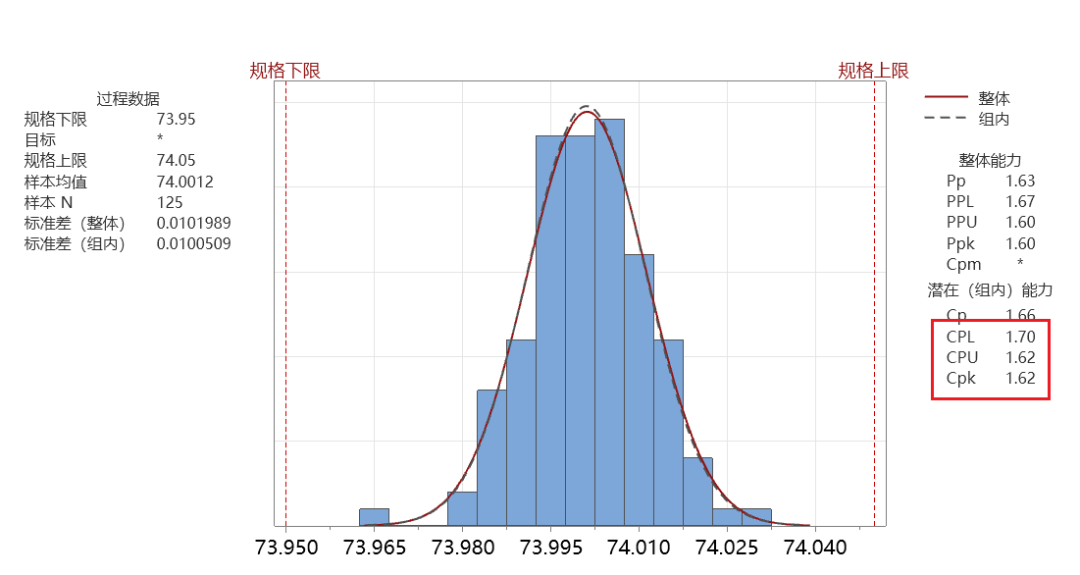
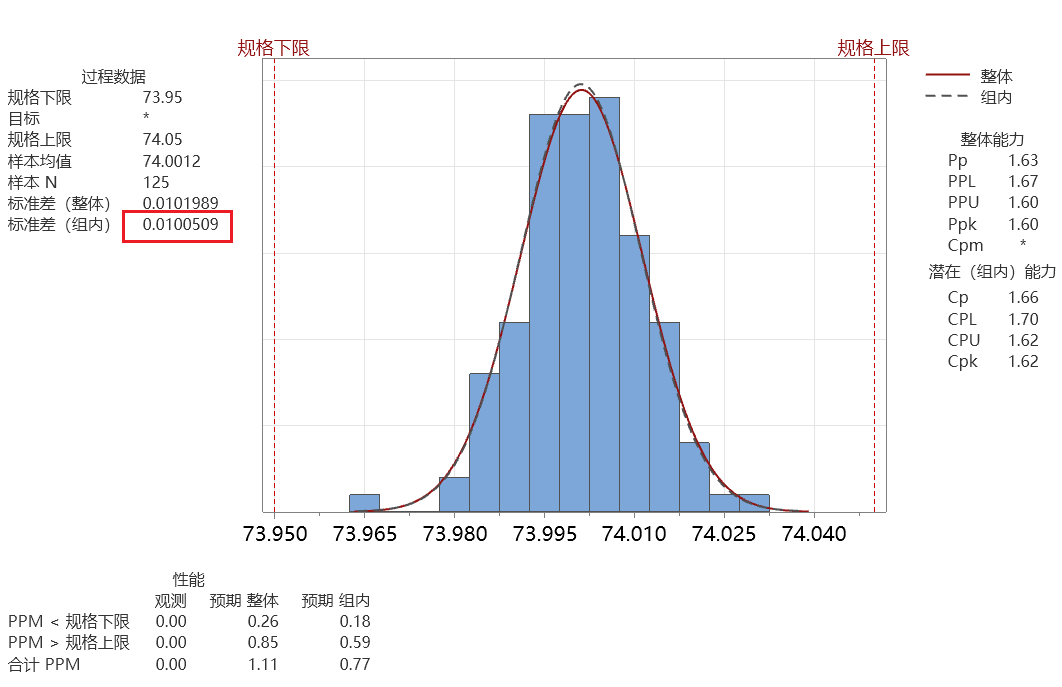 看出来是一样的结果。 第二步:计算CPK
看出来是一样的结果。 第二步:计算CPK
组内σ已经计算出来了。接下来我们就可以计算CPK了,再把CPK计算公式贴一次: CPU = (USL-μ)/3σ
CPL=(μ-LSL)/3σ
CPK = min(CPU,CPL) 我们设定USL=74.05,LSL=73.95,上面的μ= 74.0012 于是 CPU=(74.05-74.0012)/(3*0.010050862)=1.62 CPL=(74.0012-73.95)/(3*0.010050862)=1.70
CPK就是CPU和CPL中最小的一个值,即 CPK=1.62 和minitab的结果核对
python实现 上面的数据,我们用一个列表来表示。
完整的Python文件,请在公众号回复“cpk”下载。
我们介绍的CPK计算用到的σ的算法,是minitab做能力分析默认的组内标准差的计算方法,叫做合并标准差。当然还有其他的算法来计算组内标准差,我们这里详细介绍了minitab默认的,应该是大家最最常用的了。看了我们这篇文章,绝对让你清晰了解了cpk的计算,不像网上的都是照本宣科的教程。
比如这个
又比如这个:CPK=min((X-LSL/3s),(USL-X/3s)) 还有这个 , 很 规范的公式 ,也很清晰

主要是对组内σ的计算没有说清楚。
既然这样,今天我就和大家说说详细的CPK的计算过程,并且在excel中实现,同时也在python中实现,最后提供excel文件和python文件给大家下载。
数据
算法和EXCEL实现
CPK的算法不复杂,下面列出CP CPU CPL和CPK的计算,其实看起来上网上介绍的差不多,对,确实差不多。但网上说的基本上没有说清楚σ是怎么算的,我们这次就认真和大家分享一下σ的算法,并且和minitab用同一份数据核对。
CP = (USL-LSL)/3σ CPU = (USL-μ)/3σ
CPL=(μ-LSL)/3σ
CPK = min(CPU,CPL)
CPK就是从CPU和CPL中去最小一个值。 第一步:计算组内标准差 上面的μ是所有数据的平均数,这个很简单没有什么疑问的。USL和LSL是人工设定的一个规格限。那么这里就剩下σ如何计算了。 这里的σ我们称之为组内标准差,用σ组内表示,公式如下:
不急,我们一个一个参数来确定计算方法。 可能有一些朋友对这样的公式不太了解,我们详细解释一下,专家可以跳过。
看我们上面提供的数据,一个有25行数据,每行有5个值。
上面的公式就是计算每行的平均值,在每一行内,每个值分别和行平均值相减取平方,得到5个结果,25行得到125个结果,把这些结果求和,得到的是上述公式的根号里面的分子部分。 数据中每行5个 ni-1就是4,得到25个4,即100,得到的是上述公式的根号里面的分母部分。 最终sp =0.01002576680 接下来我们计算C4(d+1) d是自由度,d=100,即每行的5减去1得到4,25行*4=100
不用怕这个公式,我们代入数据看看
代入后的公式是很简单的,我们看看Γ(n)是怎么算的,这个gamma函数,我们手工是算不出来的,我们通过excel的函数来计算。
最终gamma(50.5)/gamma(50)= 7.053412515
最终分母部分等于0.997503164 σ组内 =0.01002576680/0.997503164 = 0.010050862 同一组数据,我们用minitab核对一下结果看出来是一样的结果。 第二步:计算CPK 组内σ已经计算出来了。接下来我们就可以计算CPK了,再把CPK计算公式贴一次: CPU = (USL-μ)/3σ
CPL=(μ-LSL)/3σ
CPK = min(CPU,CPL) 我们设定USL=74.05,LSL=73.95,上面的μ= 74.0012 于是 CPU=(74.05-74.0012)/(3*0.010050862)=1.62 CPL=(74.0012-73.95)/(3*0.010050862)=1.70
CPK就是CPU和CPL中最小的一个值,即 CPK=1.62 和minitab的结果核对
python实现 上面的数据,我们用一个列表来表示。
data =[[74.03, 74.002, 74.019, 73.992, 74.008],[73.995, 73.992, 74.001, 74.011, 74.004],[73.988, 74.024, 74.021, 74.005, 74.002],[74.002, 73.996, 73.993, 74.015, 74.009],[73.992, 74.007, 74.015, 73.989, 74.014],[74.009, 73.994, 73.997, 73.985, 73.993],[73.995, 74.006, 73.994, 74.0, 74.005],[73.985, 74.003, 73.993, 74.015, 73.988],[74.008, 73.995, 74.009, 74.005, 74.004],[73.998, 74.0, 73.99, 74.007, 73.995],[73.994, 73.998, 73.994, 73.995, 73.99],[74.004, 74.0, 74.007, 74.0, 73.996],[73.983, 74.002, 73.998, 73.997, 74.012],[74.006, 73.967, 73.994, 74.0, 73.984],[74.012, 74.014, 73.998, 73.999, 74.007],[74.0, 73.984, 74.005, 73.998, 73.996],[73.994, 74.012, 73.986, 74.005, 74.007],[74.006, 74.01, 74.018, 74.003, 74.0],[73.984, 74.002, 74.003, 74.005, 73.997],[74.0, 74.01, 74.013, 74.02, 74.003],[73.982, 74.001, 74.015, 74.005, 73.996],[74.004, 73.999, 73.99, 74.006, 74.009],[74.01, 73.989, 73.99, 74.009, 74.014],[74.015, 74.008, 73.993, 74.0, 74.01],[73.982, 73.984, 73.995, 74.017, 74.013]]
#计算每行平均数row_means = [sum(row) / len(row) for row in data]#计算行的每个值和平均数之差的平方squared_diffs = [[(x - mean)**2 for x in row] for row, mean in zip(data, row_means)]#对所有结果求和total_sum = sum(sum(row) for row in squared_diffs)
#计算自由度和标准差degrees_of_freedom=len(data)*(sizes-1)pooled_std_dev = np.sqrt(total_sum/degrees_of_freedom)
#计算C4(d+1),【标准差修正用】c4 = np.sqrt(2/degrees_of_freedom)*gamma((degrees_of_freedom+1)/2)/gamma(degrees_of_freedom/2)#修正标准差,即组内标准差
pooled_std_dev_unbiased = pooled_std_dev/c4
print("组内标准差",pooled_std_dev_unbiased)
完整的Python文件,请在公众号回复“cpk”下载。
我们介绍的CPK计算用到的σ的算法,是minitab做能力分析默认的组内标准差的计算方法,叫做合并标准差。当然还有其他的算法来计算组内标准差,我们这里详细介绍了minitab默认的,应该是大家最最常用的了。看了我们这篇文章,绝对让你清晰了解了cpk的计算,不像网上的都是照本宣科的教程。
评论