
#Spdlog# Spdlog的编译与使用
“ 文章所涉及内容更多来自网络,在此声明,并感谢知识的贡献者!”
Cmake简介
CMake是一个跨平台的编译(Build)工具,可以用简单的语句来描述所有平台的编译过程。
CMake能够输出各种各样的makefile或者project文件,能测试编译器所支持的C++特性,类似UNIX下的automake。
CMake 不仅可以编译源代码、制作程序库、产生适配器(wrapper)、还可以用任意的顺序建构执行档。CMake 支持 in-place 建构(二进档和源代码在同一个目录树中)和 out-of-place 建构(二进档在别的目录里),因此可以很容易从同一个源代码目录树中建构出多个二进档。CMake 也支持静态与动态程式库的建构。
https://blog.csdn.net/weixin_45525272/article/details/122053959
下载并安装Cmake
https://cmake.org/download/
Cmake编译教程
https://www.bilibili.com/read/cv14249845
https://blog.csdn.net/m0_61812914/article/details/127952081
Eigen简介:
Eigen是一个高层次的C ++库,有效支持线性代数,矩阵和矢量运算,数值分析及其相关的算法。
下载Eigen源码
https://eigen.tuxfamily.org/index.php?title=Main_Page
https://gitlab.com/libeigen/eigen/-/releases/3.4.0
编译安装Eigen源码
https://www.likecs.com/show-204786214.html#sc=2625
https://blog.csdn.net/OOFFrankDura/article/details/103586893
PCL简介
PCL(Point Cloud Library)是在吸收了前人点云相关研究基础上建立起来的大型跨平台开源C++编程库,它实现了大量点云相关的通用算法和高效数据结构,涉及到点云获取、滤波、分割、配准、检索、特征提取、识别、追踪、曲面重建、可视化等。支持多种操作系统平台,可在Windows、Linux、Android、Mac OS X、部分嵌入式实时系统上运行。如果说OpenCV是2D信息获取与处理的结晶,那么PCL就在3D信息获取与处理上具有同等地位,PCL是BSD授权方式,可以免费进行商业和学术应用。
https://blog.csdn.net/qq_41951923/article/details/103375681
https://blog.csdn.net/expert_joe/article/details/123342098
下载并安装PCL
https://github.com/PointCloudLibrary/pcl/releases/tag/pcl-1.8.1
下载PCL源码
http://pointclouds.org/documentation/index.html
编译PCL
https://blog.csdn.net/weixin_43186817/article/details/103469057
https://blog.csdn.net/luolaihua2018/article/details/116919716
https://blog.csdn.net/hanxue20100/article/details/116654750
https://blog.csdn.net/weixin_44456692/article/details/113508167
https://blog.csdn.net/whutt_/article/details/122756505
https://blog.csdn.net/m0_61812914/article/details/127952081
Spdlog简介
spdlog是一款优秀的基于C++ 11的轻量级的日志管理库,使用时只需要引入头文件即可。将记录日志交给spdlog,事半功倍。
下载spdlog源码
https://github.com/gabime/spdlog
编译spdlog源码
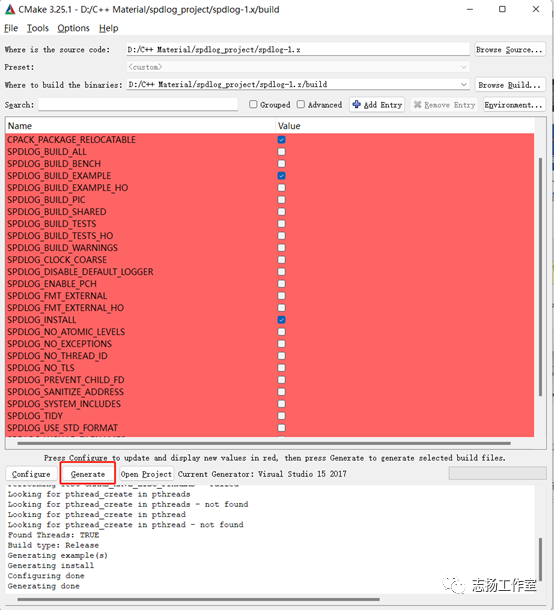
使用Cmake GUI编译spdlog
-在spdlog源码中新建build文件夹

-在Cmake Gui 配置项目的编译信息

-配置VS的属性
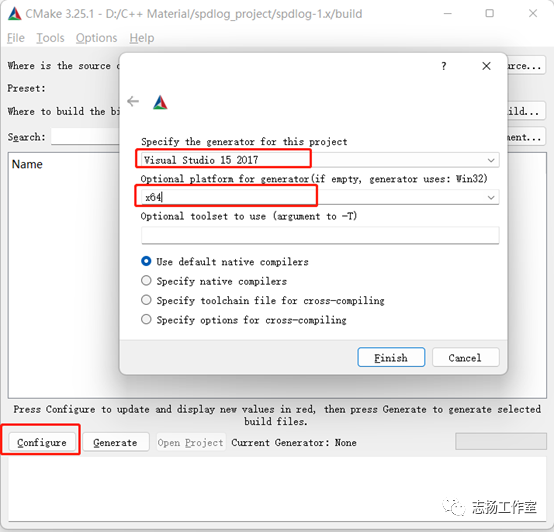
-点击Generate,生成spdlog.sln
-vs 2017编译生成 spdlog.dll
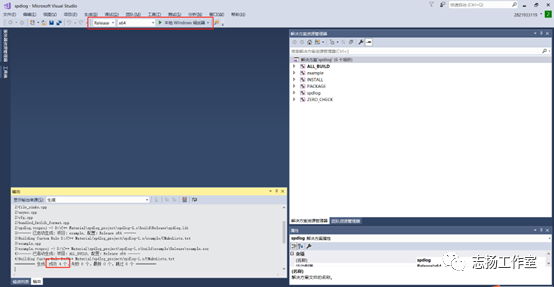
生成的目标文件:
spdlog_project\spdlog-1.x\build\Release\spdlog.lib
-新建项目
-创建第三方库文件夹
-将编译生成的spdlog.lib文件复制到第三方库ThirdLib文件夹
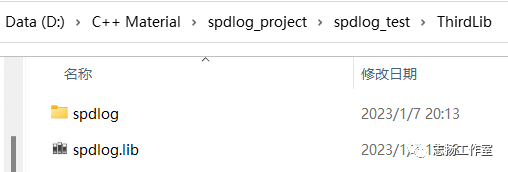
-将spdlog源码中include文件夹下的spdlog文件夹复制到ThirdLib文件夹
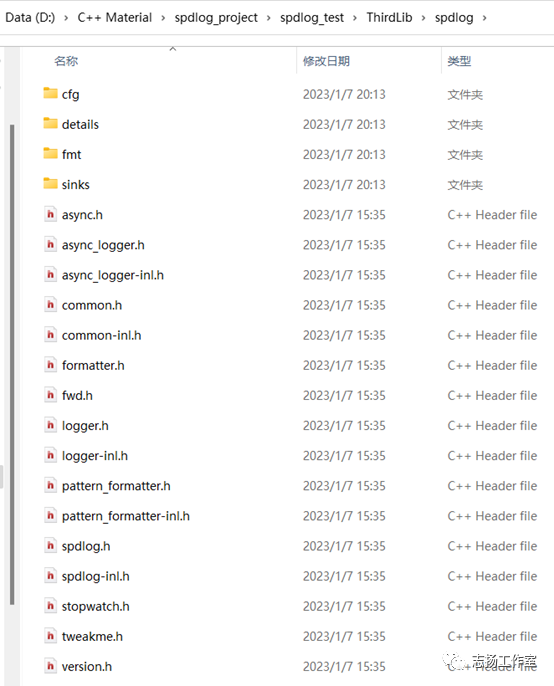
-配置spdlog库的引用信息
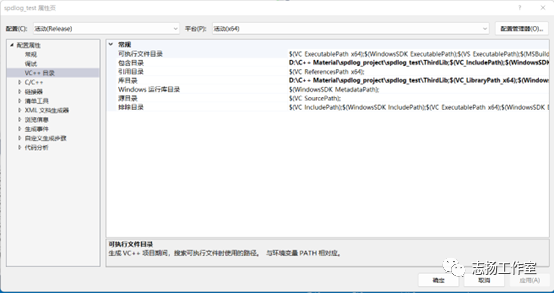

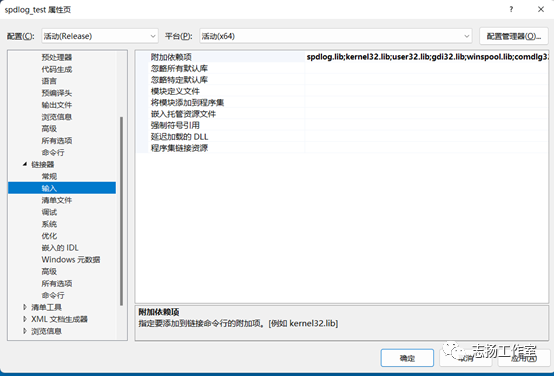 https://www.jianshu.com/p/64bcc1fe3fab
https://www.jianshu.com/p/64bcc1fe3fab
-在自定义类中引用spdlog
-运行效果
Spdlog特性
-非常快
-只包含头文件
-无需依赖第三方库
-支持跨平台 - Linux / Windows on 32/64 bits
-支持多线程
-可对日志文件进行循环输出
-可每日生成日志文件
-支持控制台日志输出
-可选的异步日志
-支持日志输出级别
-可自定义日志格式
Spdlog 功能:
Spdlog只有一个管家register,管家按照日志名字管理所有日志(即文件日志和控制台日志),管家有提供很多服务,主要有输出日志级别,刷新文件日志方式,设置日志格式等
Spdlog 结构:
spdlog可以分成三级结构,从上而下是logger registry、logger、sink,其各自功能如下:
logger registry(日志管理器):负责管理所有的logger,用户建立的所有logger都会在registry处进行登记然后统一管理
logger(日志记录器):是用户直接操作的对象,通过操作logger进行日志逻辑的生成
sink(日志记录器槽):受logger控制,执行具体的动作(动作包括写入日志文件/输出到控制台)
一个logger registry管多个logger,一个logger管多个sink。logger registry中的logger是通过name进行对应的。后面使用的时候可以直接通过名称获取对应的日志对象。
有了这种层级结构,在代码调用的时候,logger的每个操作都会下顺到sink层面,调用sink的对象。比如像一些set_pattern()和set_level()。
日志库的目的就是把日志信息写到指定地方。从上面对于结构的功能描述,sink才是真正操作日志进行写操作的结构,那sink可以把日志信息写到哪里呢?主要有三个去向:
1)控制台输出(stdout)——默认输出方式
2)日志文件
3)数据库或其他外部实体
Spdlog 存储:
spdlog中提供了以下几种存放方式:
1)当天日志(spdlog::daliy_logger):记录当天的所有日志,但在指定时间点会把日志清空
2)循环日志(spdlog::rotating_logger):日志创建成功后,如果写入的日志大小超过限制就会写入到新日志文件中去。不过同时存在的日志总数是有上限的,达到上限后按指定策略淘汰。需要特别注意的是日志更迭的规则是:当日志A存满时,将日志A名称更改为B,再新建一个日志命名为A,依次类推,直到达到上限数字
3)单个日志(spdlog::basic_logger):只有一个日志文件,所有日志都会在该文件中累加
除了3种文件日志外,输出终端(控制台)也比较常用啦
4)输出终端(spdlog::stdout_color):日志打印至终端,不同等级日志颜色不同
Spdlog 日志等级
enum level_enum {
trace = SPDLOG_LEVEL_TRACE 0
debug = SPDLOG_LEVEL_DEBUG 1
info = SPDLOG_LEVEL_INFO 2(默认输出等级)
warn = SPDLOG_LEVEL_WARN 3
err = SPDLOG_LEVEL_ERROR 4
critical = SPDLOG_LEVEL_CRITICAL 5
off = SPDLOG_LEVEL_OFF 6
}
日志级别
控制台日志级别
SPDLOG_DEBUG
SPDLOG_INFO
SPDLOG_WARN
SPDLOG_ERROR
SPDLOG_CRITICAL
旋转日志级别
SPDLOG_INFO_FILE
SPDLOG_WARN_FILE
SPDLOG_ERROR_FILE
SPDLOG_CRITICAL_FILE
Spdlog 异步与同步
同步/异步指日志信息是否直接输出/写入文件,直接写就是同步,稍后写就是异步。spdlog默认的状态就是同步了。
异步状态下,日志会先存入队列,然后由线程从队列中取数据,当队列满的时候会有淘汰策略。如果工作线程中抛出了异常,向队列写入下一条日志时异常会再次抛出,可以在写入队列时捕捉工作者线程的异常,淘汰策略一般两种:
1)阻塞新来的的日志,直到队列有剩余空间(默认处理方式)
2)把新的日志丢掉(需要设定:spdlog::set_async_mode(队列大小,
Spdlog 单线程与多线程
spdlog中提供了单线程和多线程模式,由使用者在对象创建中自己指定。
st:单线程版本,不用加锁,效率高,但不保证线程安全
mt:多线程版本,保证多线程并发情况线程安全,但效率稍低
Spdlog 输出格式:
Pattern说明
输出格式的Pattern中可以有若干 %开头的标记,含义如下表:
标记 说明
%v 实际需要被日志记录的文本,如果文本中有{占位符}会被替换
%t 线程标识符
%P 进程标识符
%n 日志记录器名称
%l 日志级别
%L 日志级别简写
%a 简写的周几,例如Thu
%A 周几,例如Thursday
%b 简写的月份,例如Aug
%B 月份,例如August
%c 日期时间,例如Thu Aug 23 15:35:46 2014
%C 两位年份,例如14
%Y 四位年份,例如2014
%D 或 %x MM/DD/YY格式日期,例如"08/23/14
%m 月份,1-12之间
%d 月份中的第几天,1-31之间
%H 24小时制的小时,0-23之间
%I 12小时制的小时,1-12之间
%M 分钟,0-59
%S 秒,0-59
%e 当前秒内的毫秒,0-999
%f 当前秒内的微秒,0-999999
%F 当前秒内的纳秒, 0-999999999
%p AM或者PM
%r 12小时时间,例如02:55:02 pm
%R 等价于%H:%M,例如23:55
%T 或 %X HH:MM:SS
%z 时区UTC偏移,例如+02:00
%+ 表示默认格式
Spdlog 刷新参数:
刷新方式指日志何时写入文件中,spdlog提供了两种刷新方式:
1)程序正常退出时写入(默认)
2)程序运行中,在指定位置进行写入(实时刷新日志,便于锁定错误所在位置)
要想使用实时刷新日志,spdlog提供了两种方法:
方法一:logger对象->flush_on(设定等级),flush_on是一次性刷新,执行到此时按照设定等级进行日志刷新。
方法二:logger对象->flush_every(周期时间),flush_every是设置刷新周期,定时进行刷新。刷新的级别采取默认了。
参考资料:
https://zhuanlan.zhihu.com/p/337877916
https://blog.csdn.net/xmcy001122/article/details/105864473/?utm_medium=distribute.pc_relevant.none-task-blog-title-2&spm=1001.2101.3001.4242
https://www.cnblogs.com/Braveliu/p/12375556.html
https://www.jianshu.com/p/b0322391da9f
https://www.freesion.com/article/397888765/
https://blog.gmem.cc/spdlog
http://www.360doc.com/content/20/0114/10/65839724_886099666.shtml
https://blog.csdn.net/gls_nuaa/article/details/126738472
https://blog.csdn.net/qq_36583051/article/details/115628620
https://cloud.tencent.com/developer/article/2102109
VS SDK安装:
VS2017报错之“error MSB8036: 找不到 Windows SDK 版本8.1。请安装所需的版本的 Windows SDK 或...”解决方法
https://blog.csdn.net/weixin_43051346/article/details/122407923
"0xa0"转换为十进制为160,表示汉字的开始。这种错误主要是因为拷贝导致,在程序头或者尾部,可能又空格之类的符号
https://blog.csdn.net/yunken28/article/details/96331082
https://blog.csdn.net/lihaidong1991/article/details/104503187