
当我们在学习Hive的时候在学习什么?「硬刚Hive续集」
大家不要在惦记我的师姐了。😆
师姐孩子都幼儿园水平了,上上周来园区,直接给我手撕了一个冒泡排序。
我当时汗都吓出来了。😅
下次有机会我们来介绍一下我的小师妹。
我们又来到「学习什么」系列了。这篇文章是对「硬刚Hive」的补充。
我在之前的硬刚系列《大数据方向另一个十年开启 |《硬刚系列》第一版完结》中写过一个《硬刚Hive | 4万字基础调优面试小总结》,这个小结里基本涵盖了你所看过的关于Hive的常见的知识和面试八股文。
一、基于Hadoop的数据仓库Hive基础知识
二、HiveSQL语法
三、Hive性能优化
四、Hive性能优化之数据倾斜专题
五、HiveSQL优化十二板斧
六、Hive面试题(一)
七、Hive/Hadoop高频面试点集合(二)
然而,我发现漏掉了一些东西。我将在本篇文章进行补充。
Hive工作原理和运行架构
你可以在官网中找到Hive的架构和运行图:
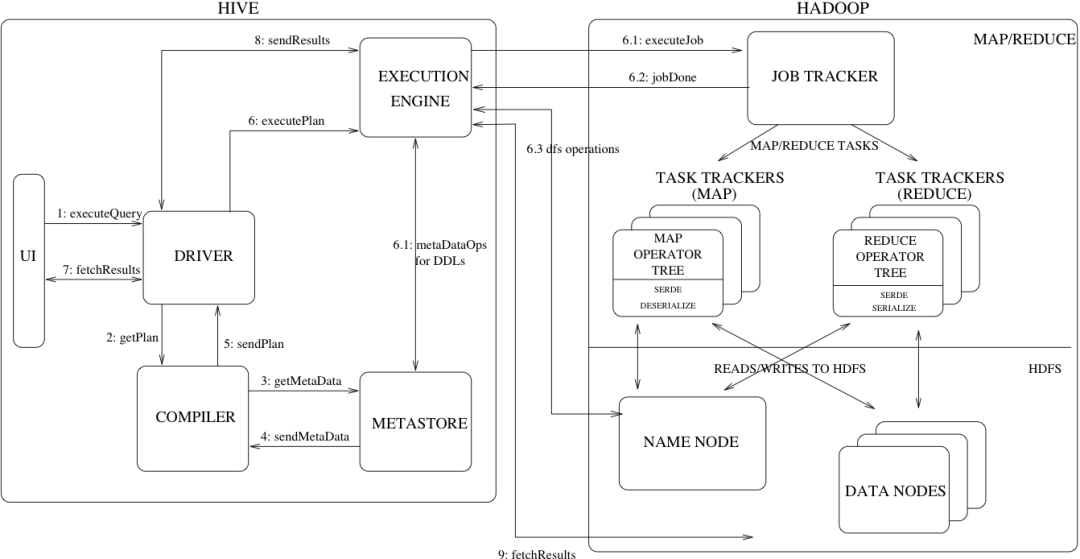
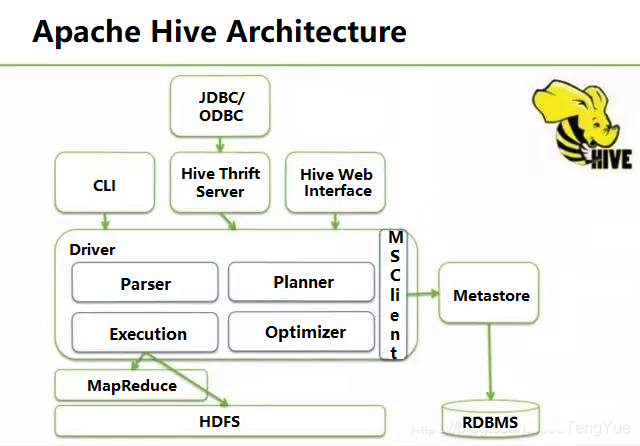
从Hive全局架构图中可以看到Hive架构包括如下组件:CLI(Hive3.0中被废弃被BeeLine取代)、JDBC/ODBC、Thrift Server、Hive WEB Interface(HWI)、Metastore和Driver(Compiler、Optimizer)
Metastore组件:元数据服务组件,这个组件用于存储hive的元数据,包括表名、表所属的数据库、表的拥有者、列/分区字段、表的类型、表的数据所在目录等内容。hive的元数据存储在关系数据库里,支持derby、mysql两种关系型数据库。元数据对于hive十分重要,因此Hive支持把metastore服务独立出来,安装到远程的服务器集群里,从而解耦hive服务和metastore服务,保证hive运行的健壮性。
Driver组件:该组件包括Parser、Compiler、Optimizer和Executor,它的作用是将我们写的HiveQL(类SQL)语句进行解析、编译、优化,生成执行计划,然后调用底层的mapreduce计算框架。
解释器(Parser):将SQL字符串转化为抽象语法树AST;
编译器(Compiler):将AST编译成逻辑执行计划;
优化器(Optimizer):对逻辑执行计划进行优化;
执行器(Executor):将逻辑执行计划转成可执行的物理计划,如MR/Spark
CLI:command line interface,命令行接口。
ThriftServers:提供JDBC和ODBC接入的能力,它用来进行可扩展且跨语言的服务的开发,hive集成了该服务,能让不同的编程语言调用hive的接口。
Hive的工作流程步骤:
ExecuteQuery(执行查询操作):命令行或Web UI之类的Hive接口将查询发送给Driver(任何数据驱动程序,如JDBC、ODBC等)执行;
GetPlan(获取计划任务):Driver借助编译器解析查询,检查语法和查询计划或查询需求;
GetMetaData(获取元数据信息):编译器将元数据请求发送到Metastore(任何数据库);
SendMetaData(发送元数据):MetaStore将元数据作为对编译器的响应发送出去;
SendPlan(发送计划任务):编译器检查需求并将计划重新发送给Driver。到目前为止,查询的解析和编译已经完成;
ExecutePlan(执行计划任务):Driver将执行计划发送到执行引擎;
6.1 ExecuteJob(执行Job任务):在内部,执行任务的过程是MapReduce Job。执行引擎将Job发送到ResourceManager,ResourceManager位于Name节点中,并将job分配给datanode中的NodeManager。在这里,查询执行MapReduce任务;
6.2 Metadata Ops(元数据操作):在执行的同时,执行引擎可以使用Metastore执行元数据操作;
6.3 jobDone(完成任务):完成MapReduce Job;
6.4 dfs operations(dfs操作记录):向namenode获取操作数据;
FetchResult(拉取结果集):执行引擎将从datanode上获取结果集;
SendResults(发送结果集至driver):执行引擎将这些结果值发送给Driver;
SendResults (driver将result发送至interface):Driver将结果发送到Hive接口(即UI)。
HiveSQL转化为MR任务的过程
我在网上找到一个转化图:
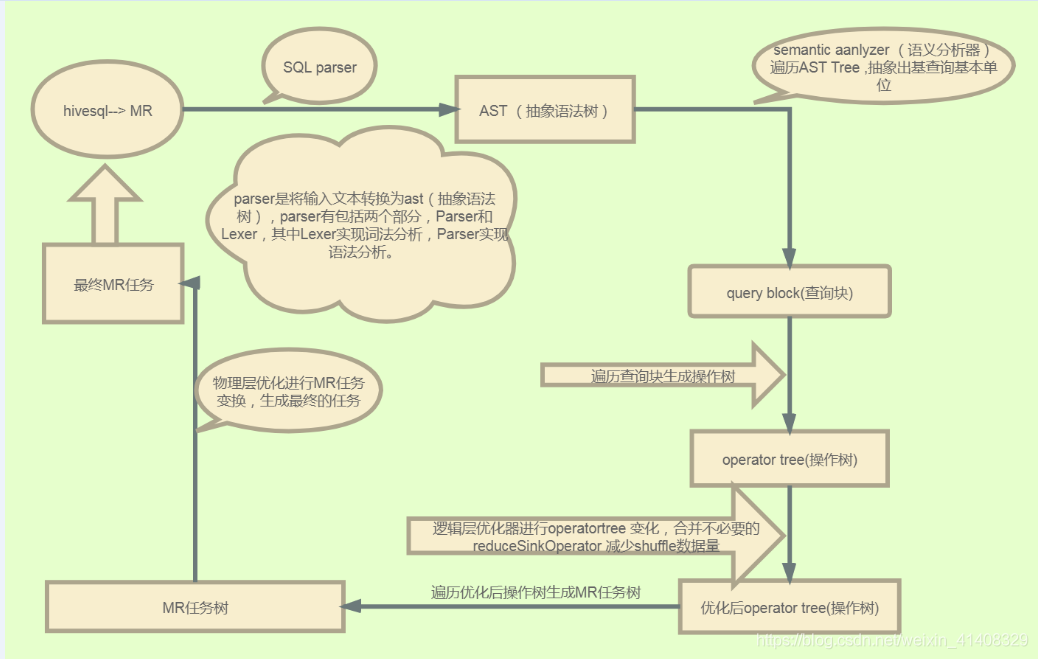
编译 SQL 的任务是在上面介绍的 COMPILER(编译器组件)中完成的。Hive将SQL转化为MapReduce任务,整个编译过程分为六个阶段:
词法、语法解析: Antlr 定义 SQL 的语法规则,完成 SQL 词法,语法解析,将 SQL 转化为抽象语法树 AST Tree;
语义解析: 遍历 AST Tree,抽象出查询的基本组成单元 QueryBlock;
生成逻辑执行计划: 遍历 QueryBlock,翻译为执行操作树 OperatorTree;
优化逻辑执行计划: 逻辑层优化器进行 OperatorTree 变换,合并 Operator,达到减少 MapReduce Job,减少数据传输及 shuffle 数据量;
生成物理执行计划: 遍历 OperatorTree,翻译为 MapReduce 任务;
优化物理执行计划: 物理层优化器进行 MapReduce 任务的变换,生成最终的执行计划。
而且要特别注意:
一个复杂的Hive SQL 可能会转化成多个MapReduce任务执行。
HiveSQL转换成MR任务?你问过Hive3.0的Tez吗?
我上面讲的HiveSQL转化为MR任务的过程只适用于Hive3.0以下版本。在Hive3.0+版本中这个默认执行引擎被替换成了Tez。
为什么抛弃MR任务?因为Hadoop的MapReduce真的太慢了。
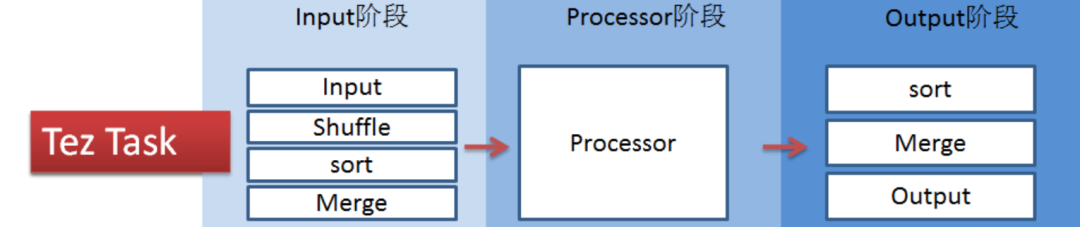
Tez是Apache开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。
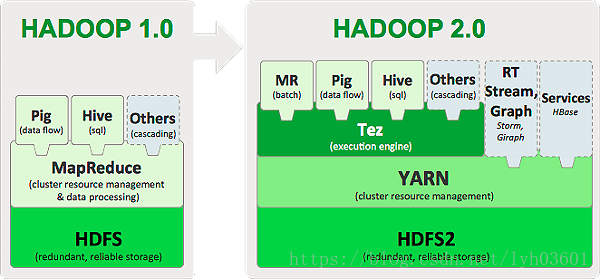
Tez将Map task和Reduce task拆分为如下图所示:

Tez的task由Input、processor、output阶段组成,可以表达所有复杂的map、reduce操作,如下图,
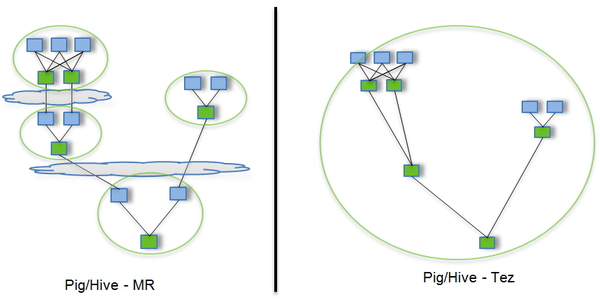
举个栗子看优势,直接看下图,Tez可以将多个有依赖的作业转换为一个作业(这样只需写一次HDFS,且中间节点较少),从而大大提升DAG作业的性能。Tez很早就已被Hortonworks用于Hive引擎的优化,经测试,性能提升约100倍。
在Hive3.0中,Hive终于将执行引擎切换到了Tez。Hive终于不在那么慢了。
Spark on Hive的支持
Spark通过Spark-SQL使用Hive 语句,操作Hive,底层运行的还是Spark rdd。在很多大公司,都实现了对Spark on Hive的支持。
大概的原理是:
通过SparkSql,加载Hive的配置文件,获取到Hive的元数据信息
通过SparkSql获取到Hive的元数据信息之后就可以拿到Hive的所有表的数据
接下来就可以通过通过SparkSql来操作Hive表中的数据
详细可以参考:《Spark on Hive & Hive on Spark,傻傻分不清楚》
另外,还有Hive3.0中更多的特性,我们在后面再一一解答。

你好,我是王知无,一个大数据领域的硬核原创作者。
做过后端架构、数据中间件、数据平台&架构、算法工程化。
专注大数据领域实时动态&技术提升&个人成长&职场进阶,欢迎关注。