
太酷了!手把手教你用 Python 绘制桑基图! | 用户行为路径分析
作者:python与数据分析
链接:https://www.jianshu.com/p/16ccab26360f
公众号后台回复:「Python绘制桑基图」,即可获取本文完整数据。
对于很多产品来说,分析用户行为都是非常重要的。用户分析能推动产品的迭代,为精准营销提供一些定制化服务,驱动我们做一些产品上的决策。常用的用户专题分析方法,包括用户分群、留存分析、转化分析、行为路径分析和事件分析、用户画像、用户增长等。
那么,本篇文章会为大家重点介绍用户行为路径分析,并结合可视化图表——桑基图,来实现落地。
一、什么是用户路径?
用户路径,就是用户在网站或 APP 中的访问行为路径,为了衡量网站/APP的优化效果或者营销推广效果,了解用户的行为偏好,要对访问路径的数据进行分析。
二、用户路径分析的价值
用户路径分析和转化分析有点类似,转化分析能告诉我们最终有多少用户成功转化,多少用户流失了。可这些流失的用户都去了哪?他们在流失前都有什么行为?这些问题转化分析都无法告诉我们,因此我们需要对用户的行为路径进行分析,以帮助我们更深入了解流失背后的原因。行为路径分析相比于转化分析记录的信息要更广。
用户路径分析,以目标事件为起点|终点,通过描述用户的行为路径,可以查看某个事件节点用户的流向,科学的路径分析能够带来以下价值:
可视化用户流向,对海量用户的行为习惯形成宏观了解
通过用户路径分析,可以将整个用户路径的上下游进行可视化展示。即可看到用户群体的登录,跳转、流失、成交等事件的情况。运营人员可通过用户整体的行为路径找到不同行为间的关系,挖掘规律并找到瓶颈。
定位影响转化的因素,推动产品的优化与改进
路径分析对产品设计的优化与改进有着很大的帮助,了解用户从登录到购买整体行为的主路径和次路径,根据用户路径中各个环节的转化率,发现用户的行为规律和偏好,也用于监测和定位用户路径走向中存在的问题,判断影响转化的主要因素和次要因素,也可以发现某些冷门的功能点。
三、路径分析与漏斗分析的区别
行为路径分析是用来追踪用户从某个事件开始到某个事件结束过程中的全部动线的分析方法。转化漏斗是人为定义的,而对于用户的行为路径,我们虽然可以通过产品设计进行引导,但却无法控制。因此我们分析用户的行为路径可以了解用户的实际操作行为,让产品顺应用户,通过优化界面交互让产品用起来更加流畅和符合用户习惯,产出更多价值。
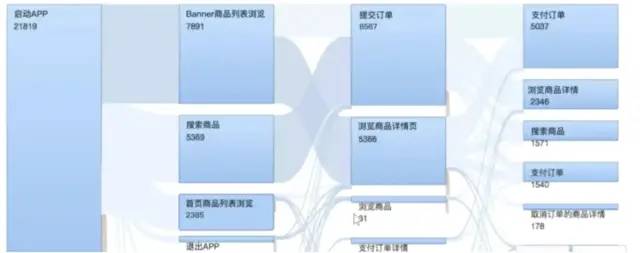
用户行为路径:桑基图
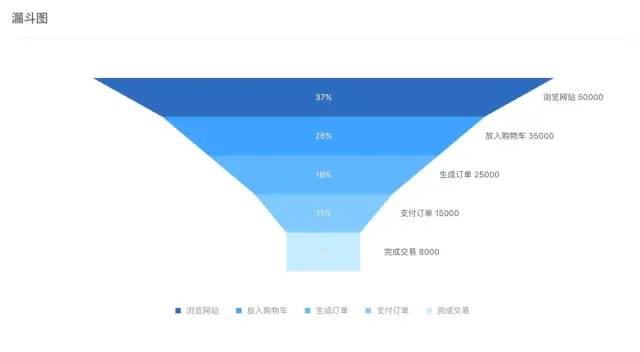
所以,简单来说:
漏斗分析:人为设定一条或者若干条漏斗,先有假设再数据验证。
路径分析:基于用户所有行为,挖掘出若干条重要的用户路径,先有数据再验证假设。
四、用代码实现—桑基图
桑基图,它的核心是对不同点之间,通过线来连接。线的粗细代表流量的大小。
很多工具都能实现桑基图,比如:Excel、tableau,我们今天要用 Pyecharts 来绘制。
因为没有用户行为路径相关的公开数据,所以本次实现可视化是根据泰坦尼克号,其生存与遇难的人的数据,来分析流向路径。学会思路,你也可以换成自己公司的用户行为埋点数据。
读取数据
数据来源:https://www.kaggle.com/c/titanic
from pyecharts import options as opts
from pyecharts.charts import Sankey
import pandas as pd
data = pd.read_excel('/Users/wangwangyuqing/Desktop/train.xlsx')
data
整理数据结构:父类→子类→值
从父类到子类,每相邻的两个分类变量都需要计算,使用 Pandas 中数据透视表,计算后的数据纵向合并成三列。
lis = data.columns.tolist()[:-1]
lis1 = lis[:-1]
lis2 = lis[1:]
data1 = pd.DataFrame()
for i in zip(lis1,lis2):
datai = data.pivot_table('ID',index=list(i),aggfunc='count').reset_index()
datai.columns=[0,1,2]
data1 = data1.append(datai)
data1
生成节点数据
需要把所有涉及到的节点去重规整在一起。列表内嵌套字典的形式去重汇总。
# 生成nodes
nodes = []
# 先添加几个顶级的父节点
nodes.append({'name':'C港口'})
nodes.append({'name':'Q港口'})
nodes.append({'name':'S港口'})
# 添加其他节点
for i in data1[1].unique():
dic = {}
dic['name'] = i
nodes.append(dic)
nodes
组织数据:定义节点和流量
数据从哪里流向哪里,流量(值)是多少,循环+字典来组织数据
links = []
for i in data1.values:
dic = {}
dic['source'] = i[0]
dic['target'] = i[1]
dic['value'] = i[2]
links.append(dic)
links
数据可视化
c = (
Sankey(init_opts=opts.InitOpts(width="1200px", height="800px",theme='westeros'))
.add(
"",
nodes=nodes,
links=links,
linestyle_opt=opts.LineStyleOpts(opacity=0.2, curve=0.5, color="source"),
label_opts=opts.LabelOpts(position="right"),
)
.set_global_opts(title_opts=opts.TitleOpts(title="桑基图"))
.render("/Users/wangwangyuqing/Desktop/image.html")
)
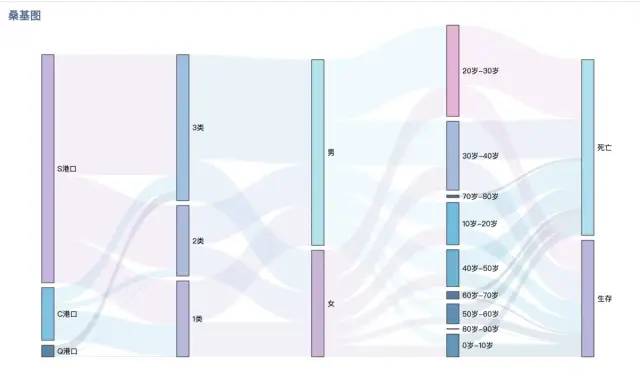
五、总结
桑基图是分析用户路径的有效方法之一,能非常直观地展现用户旅程,帮助我们进一步确定转化漏斗中的关键步骤,发现用户的流失点,找到有价值的用户群体,看用户主要流向了哪里,发现用户的兴趣点以及被忽略的产品价值,寻找新的机会。
推荐阅读
用 Python 批量提取 PDF 的图片,并存储到指定文件夹
用 Python 批量提取 PDF 的表格数据,保存为 Excel
