
大模型RLHF理论详细讲解
知乎镜像 https://zhuanlan.zhihu.com/p/657490625
写这篇文章的动机是:
-
在笔者看来RLHF是LLMs智能的关键之一; -
国内厂商在这方面投入比较少,目前看起来并没有很重视; -
大家偏向于认为ChatGPT的RLHF做法最多的线索来源于InstructGPT,但是InstructGPT原文的描述也挺含糊的,很多东西只能靠猜和结合开源的实现来解读; -
通常学习强化学习所依赖链路比较长,笔者希望以最直观的方式帮助大家通关。
笔者会分两篇文章来介绍,第一篇是理论篇,第二篇是实践篇。读者会在第一篇学习到PPO的原理和instrcutGPT中的RLHF做法;在第二篇中学习到目前影响比较大的开源RLHF实现。
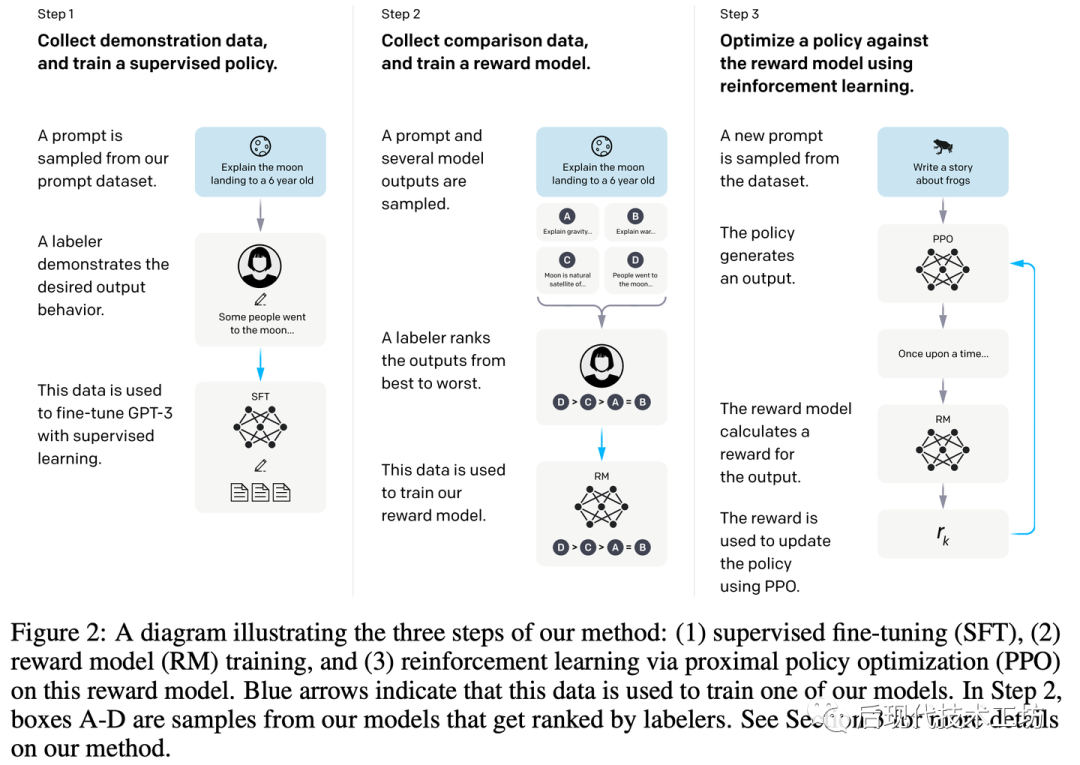
据公开可获得的信息来看,ChatGPT需要有大致三个阶段的训练过程,如上图所示:
-
Pretraining: 在大规模“无监督”的语料上训练,训练任务是预测下一个词。 -
Supervised Fine-Tuning(SFT):在人类标注上进行微调,所谓人类标注就是人类写Prompt,人类写答案。然后语言模型学习模仿人类是如何作答的。这部分通常要求数据集多样性很好,也因为标注成本很高,通常量级很小。 -
Reinforcement Learning with human feedback(RLHF):对于同一个Prompt把模型的多个输出给人类排序,获取人类偏好标注。用人类的偏好标注,训练一个reward model。训练得到的reward model会作为PPO算法中的reawrd function,来继续优化SFT得到的模型。
通常来说,第一步最有资源门槛,第三步最有技术门槛(同时也需要大量的资源),第二步最简单。所以目前很多厂商是直接拿了开源的第一步的模型,做SFT,或者continue-pretrain(比较小规模的无监督训练)再SFT。他们PR的时候可能会嘴一句,无需复杂的RLHF,只需做细致的微调也能达到很好的效果。
后面两个步骤,通常被视作是人类偏好对齐(alignment),让模型更好地跟随人类的指令作回复。而一些研究发现,对齐后的模型是会有对齐税的现象的(alignment tax),即在通用能力上会有所下降。
因此,不少人是这样认为的:第一步预训练得到的模型就已经决定了后续模型的能力上限;后面两步要做的事情仅仅是在尽可能减少对齐税的情况下,对齐人类偏好。
这里可以分两种情况分析:
-
SFT过数据太多遍了,导致大模型出现遗忘; -
安全性对齐很多模型能回答的问题,强制不让回答肯定会对模型能力有所牵制。
在笔者看来,某种意义下RL提供了对LLM的response的Global-level的监督,在一些需要答案非常精确的场景上,RL可能可以发挥出更大的威力。这个看法的依据也很朴素:
-
比如在coding、数学推导等场景,只要response在关键的地方犯了一点点错给人的感觉就是模型不会,但是SFT的loss可能区分不出来是犯错了还是只是写法风格的差异。 -
SFT给定了标准答案,LLM的上限可能会被标注者的水平所限制;RLHF则只给定了人类偏好,得到了一定(有可能是很大)程度的解放,模型有可能探索出更高程度的智能。这一点并不是无中生有的想法,在游戏AI领域有太多的验证,即在模仿人类玩法(imitation learning)之后,再用RL训练出来的模型,就是能获得更高的智能。这里语言模型跟游戏又有多少本质的区别呢。
这里笔者暂时打住,为了不增加读者的阅读成本,更多的讨论独开文章系列扯皮。
InstructGPT中的RLHF
这里简要带过具体数据构造和训练细节,后面会专门有一篇对InstructGPT像素级的解读。如前文所述,InstructGPT也是包含3阶段的训练,同时我们应该注意到,RLHF这一步训练,实则包含两步训练:
-
训练Reward Model(RM); -
用Reward Model和SFT Model构造Reward Function,基于PPO算法来训练LLM。
数据集
SFT、RM和PPO用到的数据集数据量如下表所示:

注意,上表统计的是prompts数量,在RM数据中每个prompt,对应会有4~9个responses。在构造RM数据的时候,作者采集了用户的prompts,每个prompts包含4~9个模型的输出,模型的输出会给标注员进行排序。
训练Reward Model(RM)
目标: 给pormpt-response pair打分,拟合人类的偏好。
模型: 这InstructGPT的paper中,虽然用了1.3B、6B和175B的GPT-3来做实验,但是综合考虑下,只用6B的模型来训练Reward Model,因为作者发现用175B的模型会不稳定。把最后的unembedding层换成一个输出为scalar的线性层。这里读者可能会有点混乱,众所周知,GPT的模型结构是sequence-in,sequence-out的,怎么变成scalar呢?这里文章似乎也没提到,根据笔者的判断和开源实现,推测是直接用最后一个token的输出接一个linear。
Reward Model的初始化: 6B的GPT-3模型在多个公开数据((ARC, BoolQ, CoQA, DROP, MultiNLI, OpenBookQA, QuAC, RACE, and Winogrande)上fintune。不过Paper中提到其实从预训练模型或者SFT模型开始训练结果也差不多。
训练:以前的做法是,RM每次比较两个模型输出的好坏,做法很简单类似对比学习,两个样本对应两个类别,RM对这两个样本分别输出两个得分,拼成一个logits向量;人类标注比较好的那个输出作为label,比如第一个比较好那么label为0,第二个比较好label为1;用cross entropy约束之。
但是作者发现这么做很容易过拟合;也不高效,因为每比较一次都要重新过一下reward model。因此作者的做法是,在一个batch里面,把每个Prompt对应的所有的模型输出,都过一遍Reward model,并把所有两两组合都比较一遍。比如一个Prompt有K个模型输出,那么模型则只需要处理K个样本就可以一气儿做 次比较。loss的设计如下:

很直观,其中, 是prompt, 和 分别是较好和较差的模型response, 是Reward Model的输出。 在文中似乎没有解释,不过根据公式推断和开源实现,应该是sigmoid函数。
这里要注意一个细节:在RM训练完之后,会让RM的输出减去一个bias,使得reward score在人类写的答案上(labeler demonstrations)的平均分为0。这里笔者没找到具体在什么数据上统计的,猜测是在SFT数据上做的,如果有读者知道是怎么做的欢迎指出。
Reinforcement Learning(RL)
直接看需要最大化的目标函数

其中, 和 分别是正在用RL训练的语言模型和SFT训练得到的模型。
上式中,
第一项期望式 是在最大化reward的同时,最小化和SFT模型的per-token KL penalty,可以理解为是一种正则手段,两者组合成关于prompt-Responce pair最终的Reward:。在这篇paper中解释per-token KL penalty的好处如下:
-
充当熵红利(Entropy bonus),鼓励policy探索并阻止其坍塌为单一模式。 -
确保策略模型产生的输出 与 Reward Model在训练期间看到的输出 不会相差太大,保证Reward的可靠性。
仅含这一项就是单纯使用了PPO。这里也可以看出来,Reward model的能力可能会成为RLHF的瓶颈。
第二项期望式 是可选项,注意到它其实是使用预训练的数据来做跟预训练同样的任务(predict next word),因为这一项的数据不是模型生成的其实跟RL是并行的目标。包含这一项的算法称之为PPO-ptx。
PPO算法
本小节以最小知识补充为前提,快速介绍PPO,不用犯怵,很简单而直观。
通常来说,对于一个强化学习模型,会有一个做动作的策略网络 ,它根据自己观测的状态( )做出动作( )跟环境交互,然后会拿到一个即刻的reward( ), 同时进入到下一个状态( );策略网络再继续观测状态 做下一个动作 ...直到达到最终状态。这样,策略网络和环境的一系列互动后最终会得到一个轨迹(trajectory):。
那么,在语言模型的场景下,策略网络就是待微调的LLM,它所能做的动作就是预测下一个token,它观测的转状态就是预测下一个token时所能观测到的context(Prompt+这个token前所生成的所有tokens)。reward除了最后一个 等于上文提到的其他的。
好,在LLM的场景中,现在可以统一一下符号: , ,,其中 是prompt, 是第i步蹦的token。看到这,了解PPO的同学基本上就清晰了RLHF具体是怎么做优化的了,可以直接跳过下面的科普部分。
因为PPO原文是基于Actor-Critic算法做的,Actor-Critic算法是进阶版的Policy Gradient算法。下面我们从policy gradient到Actor-Critic,再到PPO,帮助RL背景比较弱的读者串一遍。
Policy Gradient(PG)算法
核心要义:用“Reward”作为权重,最大化策略网络所做出的动作的概率。伪代码核心部分一句话的事:

用策略网络 采样出一个轨迹,然后根据即刻得到的reward 计算discounted reward ;用 作为权重,最大化这个轨迹下所采取的动作的概率 ,用梯度上升优化之。
虽然在强化学习算法中对每一步都有一个即时的“reward”,但是每一步对后面的可能状态都是有影响的。即,后面的动作获取的即时“reward”都能累计到前面的动作的贡献。但是直接加上去可能不好,毕竟不是前面的动作直接获取的reward,但是可以打个折扣再加上去,即乘个小于1的 。
这里面读者可能会有个问题:可是不好的动作也要最大化概率吗?这里有必要稍微展开一下:
-
也可以是负的,对负的 那就是最小化动作 的概率,这也是为什么前面提到要对RM的输出做归一化的其中一个原因之一。 -
即便 都是正的,但只要充分采样,同一个状态下 相对较小的动作也是会被抑制的,因为同一个状态下的动作概率求和等于1,此消彼长,只有权重最大的动作才会得到奖励。
可是,比如同一个状态下,有两个动作的 是正的,但是因为动作采样本来就很稀疏的,我们很可能不幸运采样到了相对较小的 对应的动作,而没有采样到相对较大的。但因为它是正的,这时候当前的机制下,还是会鼓励这个动作,这样的话网络很容易一直沿着不太好的策略去优化。为了解决这个问题,我们引入Actor-Critic算法。
Actor-Critic (AC)算法
核心要义:再增加一个Critic网络来构造一个Reward baseline,只有获得的reward比baseline要好才奖励这个动作,否则抑制它。

Actor指的是策略网络 ;Critic 目的就是给定一个策略网络,预估每个状态 ,策略网络所能拿到期望reward 是多少。什么是期望reward,无非就是在状态 ,对采样不同的动作 所能获取的 的平均值嘛。我们要选择的动作当然是获取的reward比平均reward要好的动作,不比baseline好的动作就得抑制它。
观测上面算法2,其实对比PG算法就加了两行:
-
原来用Reward function来加权,现在用Advantage function来加权。现在我们把 当作一个baseline方法所能拿到的reward, 用采样出来的 所拿到的reward 减去 作为最大化当前动作概率的权重: 。其中 通常被称作是Advantage function(或Advantage estimator),即优势函数。 -
拉近 和 的距离,初学者对这个可能会费解。实则很好理解,记住 在做什么,要预估当前策略下 的期望,我只要不管三七二十一,每来一个动作的 都拉近一下距离,其实就是在预估平均值。
更一般地:其实上面用到的 ,它无非是换了皮的 (简写成 ),即RL中的重要概念V function:给定策略 在 上的期望reward。那么最后一步 到达的state 通常来讲是没有随机性的(比如下棋,最后一个state决定赢输就是固定的reward;LLM,最后一个token生成完,response确定了,reward也就确定了),因此 应该和 相等。
所以我们可以重写上面的优势函数:
写成Generalized Advantage Estimation,当 下式等于上式:
其中,是时序差分式(TD error)。
记住这个结论:这样我们可以用 优化 ,现在我们可以用 来更新策略网络了。
PPO 算法
上面提到的算法,有一个最严重的弊端是,一个轨迹只用一次就丢掉了。可是,采样轨迹通常是很耗时的,对应到在LLM场景则需要做推理,众所周知LLM的推理是比训练费劲很多的,它需要一个一个地蹦词。可是直接用之前的策略采样出来的样本来优化现在的策略网络肯定不行,如何合理复用样本则是PPO要做的事情。
做法巨简单,大致可以用这个思想来更新:
定义 动作概率比,用 去梯度上升更新策略网络,注意这里 和 都是只之前的策略网络 采样得到的。这个公式,在笔者看来没有直观的解释,需要一丢丢推导,因为是科普向这里读者先承认就好了,后面笔者会单开一篇文章再重新梳理一遍。
本质上是最大化这个目标函数:

但是如果 和 如果差别太大,就不能用这个式子优化了,PPO给出的做法是给 卡阈值,太大或太小就不用这一步的样本更新了:
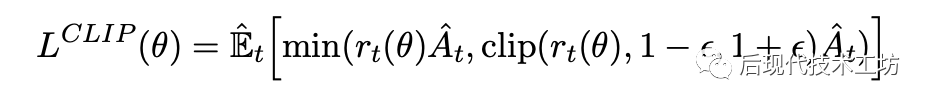
上面的目标函数可以分类讨论进行分析,对优势函数 大于0和小于0两种情况分析,这个目标函数的图像长这样:
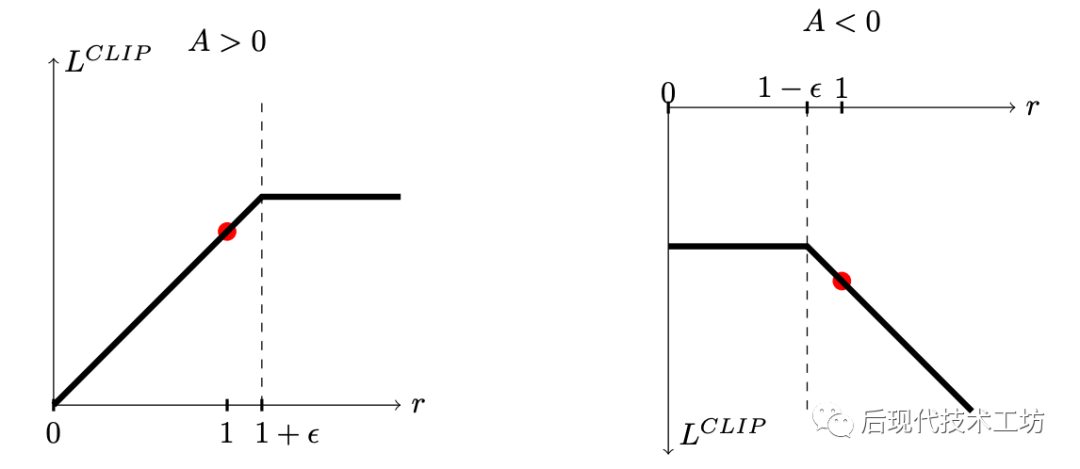
观测图像:
-
当 大于0,要提高动作的概率,但是如果概率比之前大比较多了( 是 的 倍),就不提高了
-
当 小于0,要减少动作的概率,但是如果概率比之前小比较多了( 是 的 倍),就不减少了
伪代码如下:

科普到此结束,看到这读者就可以看懂RLHF的代码。值得注意的是为了减少读者负担做了大量的叙述上的简化,方法上是比较完备的,但是说法上不够严谨。Again,更详细的强化学习科普会单开一篇文章。
大语言模型的PPO
稍微整理一下,符号和上面的科普部分不一致,不过应该不影响理解
-
现在我们的actor是SFT初始化的LLM
-
为了计算reward,我们需要两个冻住参数网络,一个RM,一个是冻住的SFT模型 用来计算KL散度,参考下面两式子:其他步的
-
为了执行PPO算法,我们需要引入一个估计V值的网络 ,它初始化来自RM。
所以统共,有4个网络,两个训练的actor 和critic ;两个用来计算reward的SFT模型 和RM模型。然后actor初始化来自SFT,critic初始化来自RM。
把这四个网络,结合reward的构造,带入到上面提到的PPO算法中,整个过程就比较清晰了。盗一下DeepSpeed-Chat的图,图解如下:

看到这,相信读者已经可以轻易看懂的DeepSpeed-Chat代码了。
推荐阅读