2022年4月初,一起AI界的学术不端事件可谓是「引爆」了整个学术圈。知乎讨论也从第一天最初的几万浏览量,飞涨到了现在的600多万。对此,我们可以引用知乎用户、伦敦玛丽皇后大学学子「谢圜不是真名」的一句话来进行总结:「学术声誉的建立是一辈子的事情,然而要推倒只需要一瞬间。」2022年4月13日晚,智源研究院作为这一综述文章的组织者,在知乎的官方账号上发表公开致歉信,称「从互联网上获悉」此事,承认涉事论文有抄袭的部分,并向学界与公众表示歉意。公开致歉信中,智源研究院提到了论文的研究领域综述性质,由百余名作者分多组「并单独署名」撰写多篇文章综合而成。智源未能做到「理应对…所有内容严格审核」。
在承认过失的部分,智源研究院的致歉信承认了爆料者Nicholas Carlini在其个人博客上曝出的部分指控抄袭部分确有其事,论文即将在预印本网站上更新的版本已删除这些内容,其他进展等待正式调查报告并已开展追责处理。
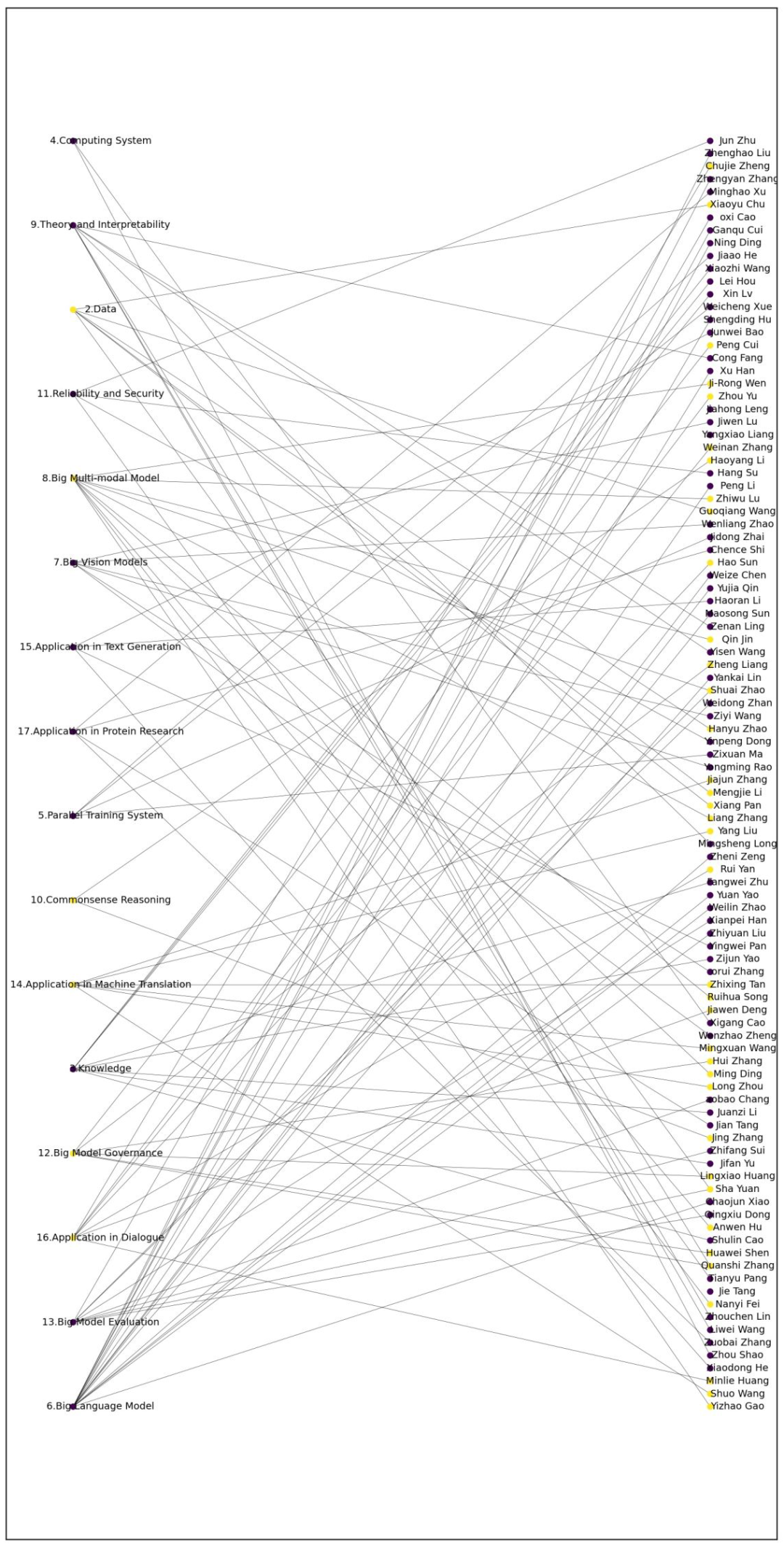
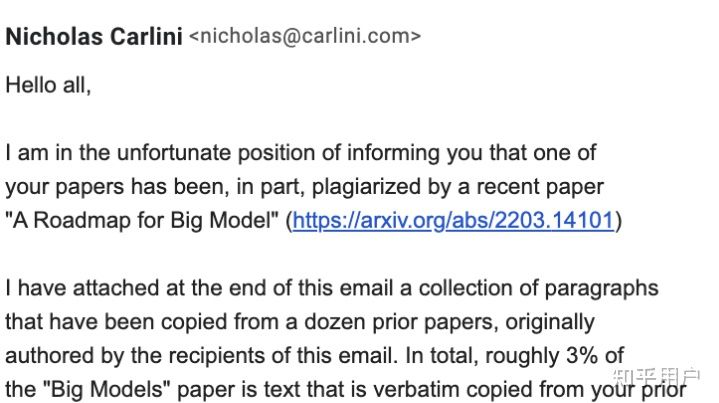
据悉,这是一篇报告而不是论文。也就相当于是16篇文章的合集,其中的内容是由各个作者独立完成和署名的。致歉信中最后表示智源研究院将「根据正式调查结果对相关责任人作出问责处理」,不过尚未提及具体责任人。4月13日上午,智源研究院的官方推特账号也发布了简短的致歉声明,内容与致歉信类似。哈佛预备讲师、创业公司Mosaic Machine Learning的总研究科学家Jonathan Frankle跟帖表示:我等着看后续。整个事件,还是要从这篇在3月26日上传至arXiv的「A Roadmap for Big Model」说起。不得不说,如此大规模的「作者团」也就能在Nature、Science等顶刊中偶尔瞥见。而近一半的共同一作,和四分一的共同通讯作者则实属罕见。随后,作者又分别在3月30日和4月2日对版本进行了更新,这其中也涉及到了作者名单的变动。这篇论文不仅谈到了大模型技术本身,还有训练大模型的前提条件。并介绍了16个有关大模型,分别是:数据、知识、计算系统、平行训练系统、语言模型、视觉模型、多模块模型、理论&可解释性、常识推理、可靠性&安全、治理、评估、机器翻译、文本生成,以及对话和蛋白质研究。在论文的最后,研究人员从更加宏观的角度总结了大模型未来的发展。2022年4月8日,来自谷歌大脑的研究员Nicholas Carlini在其个人博客上贴出文章「机器学习研究中的剽窃事例」(A Case of Plagiarism in Machine Learning Research)。其中条分缕析、清楚克制地指明了「大模型路线图」(A Roadmap for Big Model)的抄袭实迹:「大模型路线图」一文确实抄袭了他所在研究组2021年7月发表在预印本网站上的论文「复制训练数据让语言模型更优」(Deduplicating Training Data Makes Language Models Better)。此外,「大模型」一文还涉嫌抄袭十余篇其他论文。Nicholas Carlini含蓄地表示:「大模型」一文「复制粘贴」了一篇关于数据复制效果的论文,此举实在讽刺到无法被忽视。不过Nicholas Carlini也忠厚地体谅了有关涉事者:「从大局来看,这次复制粘贴并不是最恶劣的事。这又不是此论文直接抄袭了过往研究的方法与结论、然后自称这是开创性新研究成果。不过即便如此,领域总括性综述的价值在于如何重新表述/定义研究领域。直接复制粘贴之前其他论文内容的长篇总括性综述,并不比简短的引用列表的用处更大。」4月13日,在事件被更多人了解并关注后,Nicholas Carlini在此文中补充了更新内容:本文受到了我预期外的太多关注。本文的每小时新增浏览量都多过我博客上周的一周全站浏览量。所以在此恳求,不要让此事发酵成一场猎巫迫害。我看到已有人称应该马上把肇事论文相关人等全部开除、预印本网站应对他们完全禁入等等。我并不假装了解肇事论文何以如此广泛抄袭的幕后原因,因此我不多做论断。可能是一些初级作者并无恶意,以为有引用来源就可以复制粘贴。也可能是学生们受到来自导师的压力,觉得要按时交稿就只好走捷径。高级作者们可能只读了遍文本,认为无大碍就小修小补后放行,不清楚文本的来源为何。关键在于,此事幕后因由现在仍未公开。此论文有过百名作者,任何事都有可能发生。我发布此贴文的愿望,是想给学界常见的积弊招来更多关注。学界有近1%的已发表和被接受的论文,其数据复制粘贴比率比「大模型」一文还要高。我该在写此贴的一开始就说清这个背景。所以再次请大家不用对肇事论文过苛。抄袭是学界常见之弊,我对此事更警醒,是因为被抄袭的是我的论文。希望大家可以将此作为提高学界整体质量的严肃学习经验。Nicholas Carlini在其博客文章中称,在发现「大模型」一文有抄袭后,他与研究组同事将几乎所有机器学习领域的顶会、顶刊论文的PDF文件下载、然后提取所有其中的文本、再录入单个txt文档中,获得对比用的数据集。最后Nicholas Carlini与同事使用-自家被抄袭论文中的-数据集复制工具,将「大模型」一文与对比数据集一跑,发现了「大模型」一文的抄袭部分。博客文章中列举了十处抄袭最昭彰的部分,其中五处的主干部分已被智源研究院的致歉信承认。以下是Nicholas Carlini博文中列举的、智源研究院承认的抄袭处与原文对比的示例,左侧标绿部分为抄袭后的文本,右侧为原文对照文本。为了避免假阳性,Nicholas Carlini列举了自己认定抄袭的标准:1、在文本空格规范化后,至少有十个字词以上的抄袭雷同处;如此可以避免软件工具将论文的版权声明部分、此前论文对更前论文的引用、此前各篇论文的作者这些理应出现雷同处的部分认作抄袭。Nicholas Carlini称,他们的软件工具还跑出来不少「大模型」一文作者们自我抄袭的部分。不过相较于对他人论文的肆意赤裸抄袭,「我抄我自己」简直不算什么大事了。Nicholas Carlini还表示,由于筛选工具的急就性质、和对比数据集的不完备性(只包括已在学刊上发表的论文,不包括预印本网站论文),很可能还有更多的抄袭部分尚未被发现。无论如何,现有程度已经很令人伤感了。「大模型」一文随后也被arXiv官方做了标注:与其他作者的文字「重合」。此外,也有国内的网友对文章进行了源头对比,其中紫色的是无抄袭的,黄色的是涉嫌抄袭的。部分作者没有出现在具体章节里但是在总作者名单里。除了对自己文章进行了一波排查以外,Nicholas也与其他可能被抄袭的作者取得了联系。其中一个收到邮件的网友表示,现在很多人对于抄袭的重视和了解程度是不够的。copy-past是抄袭,copy-paste-edit是抄袭,截图是抄袭,复制别人arxiv上的latex公式也是抄袭。这次的事件影响之大,对整个华人学者的声誉都带来了沉重的打击。AI业界的研究者纷纷在社交网站上表示疑惑:即使有任务分工、或者挂名现象,百多号作者没一个细读过自己要挂名的东西么?科学道德与学术规范,这大概是国内所有研究生都必须要上的课程。在北京大学等高校,还有一年一度的科学道德与学术规范基本知识测试,同时还对不符合科学道德与学术规范的行为进行量化,制定了明确的、从处分到开除的,一系列惩罚措施。看起来我们的体系已经足够完善了,可事实上抄袭、剽窃等情况还是时有发生。那么,什么程度才算抄袭?抄袭和引用的区别又是什么?这些标准不能靠上下嘴唇一碰张口就来,而必须有明确的、可量化、可执行的标准。著名的中文查重平台PaperPass就在其官网上给出了有关抄袭的认定标准。可以看到其中对于抄袭判定的量化规定:连续引用200字且未注明出处、直接翻译或复制、重排超过15%的内容等等。以及,照搬他人论文或著作中的实验结果、分析、系统设计以及问题解决办法而未注明出处、未说明借鉴来源等等。出于严谨起见,我们给出照搬的定义:照原样不动地搬用(现成的方法、经验、教材等)。与此同时,在认定为抄袭之后,对于抄袭程度的判定同样有规可循。重复内容占比的三条划线分别为不到30%、30%~50%之间、50%以上,分别判定为轻度、中度、严重抄袭。此外,IEEE对抄袭也有相关的规定。有非常明确的分级标准,共五级。其中第一级是最严重的,定义为:未注明引用的、全文一字不差的照搬;未注明引用的、对主要部分超过50%的、一字不差的照搬;以及一名作者的多篇论文内都有一字不差的照搬、且总量超过50%。第二级:未注明引用的、一字不差的、对一篇文章20%到50%内容的照搬。第三级:未注明引用的、一字不差的、对一篇文章中段落、句子的照搬,总量20%以下,且使用在抄袭论文中的主要部分。第五级是评判标准中最轻的:注明引用的、但界限不明的、一字不差的、对一篇文章中主要部分的照搬。有国内网友称,本次智源抄袭事件是第五级,处置还算及时妥善。
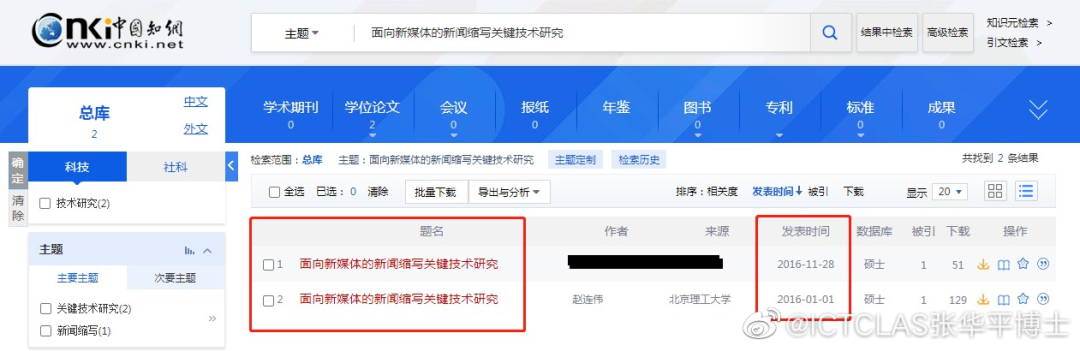
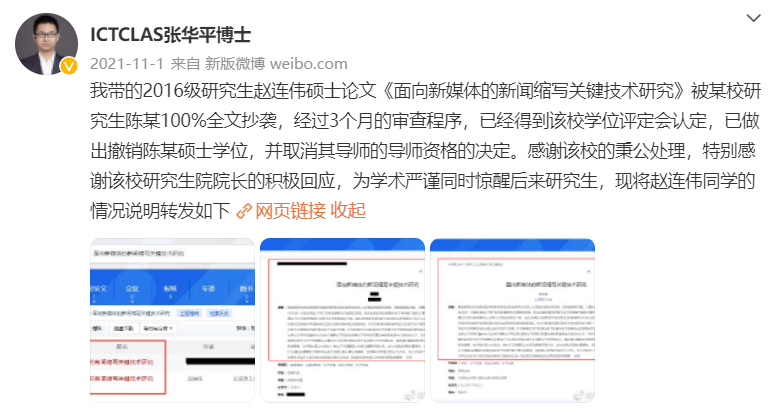
可见,在这套清晰的框架下,任何不端行为皆无处遁形。IEEE分级标准:https://www.ieee.org/content/dam/ieee-org/ieee/web/org/pubs/Level_description.pdf此外,对于这次的「大抄袭」事件,有相当多的网友对论文的「署名」提出了质疑。在此前的学术不端事件中,知乎答主「Summer Clover」就曾指出,现在的paper不仅从灌水变成了抄袭和洗稿,而且还时常出现「挂名成风」的现象。实际上,挂名问题由来已久。通常来说,分为利己型和利他型。要么就是挂一些知名人士的名字上去,以增加文章发表在更高级期刊上的概率,而这些知名人士可能对论文撰写并无任何贡献。不得不说,在学术行为规范这块,中国还有挺长的路要走。小编在撰写这篇文章大量查阅了近几年的毕业论文抄袭的相关新闻事件。用一个词来概括就是,「层出不穷」。比如,湖南大学2016届软件工程硕士毕业生陈某,他的硕士学位论文「面向新媒体的新闻缩写关键技术研究」就被举报抄袭。北京理工大学张华平博士发现,陈某原封不动抄袭了他带的研究生赵连伟的「面向新媒体的新闻缩写关键技术研究」,标题竟也一字未动。湖南大学立即开展相关核查工作,于2021年11月3日在微博发布说明,撤销了陈某的硕士学位。同时,他的导师唐某某也被撤掉了研究生指导教师资格。在湖南大学的说明发出后,张博士也发了一条微博,给整件事收了尾。学生论文抄袭,往浅了说,导师根本没有认真核查、指导,就给予了通过,未尽到责任。往深了说,可能涉及纵容抄袭的情况。无论导师未能及时发现抄袭情况的原因为何,确实是出现失职了。其实,肃清学术风气无外乎两条路可走。一是加强科学道德与学术规范建设,另一个就是严惩出现学术不端行为的个人。北京大学自2020年起,开通研究生科学道德与学术规范的网络学习平台。研究生入学后就要先自学相关建设宣讲大纲和规范指南。自学完毕还要完成相关测试,合格率通过方可过关。这和考驾照的科目一类似。如同一个人在熟谙交规之前不可以驾车上路一样,研究生不充分了解科学道德与学术规范的相关要求,也没道理能被允许开始研究。当然,这些测试更多起到预警目的。真正重要的不是通过测试,而是在进行研究和论文撰写时牢记这些要求,每时每刻践行。如果出现学术不端的行为,相关惩罚措施同样不能缺席。比如,清华大学在学生纪律处分管理规定实施细则就明确规定了一系列惩罚措施。可以看到,出现任何学术不端行为,都会受到严厉的处罚。就像竞技体育打假赛、踢假球一样,学术造假、抄袭、剽窃、盗用,都是无法洗白的事,碰也不能碰。借用知名电竞教练阿布评价假赛选手的一句话,「碰了假赛就必死,无关轻重。」我想学术不端也是一样,这关乎一个人的品性问题,以及整个大环境的清朗。参考资料:
https://www.zhihu.com/question/527620020/answer/2436752217
https://zhuanlan.zhihu.com/p/498064778
https://nicholas.carlini.com/writing/2022/a-case-of-plagarism-in-machine-learning.html
公众号后台回复“CVPR 2022”获取论文打包合集下载~
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~