
浅谈语音质量保障:如何测试 RTC 中的音频质量?
背景介绍
详解 WebRTC 高音质低延时的背后 — AGC(自动增益控制)
硬货专栏 |深入浅出 WebRTC AEC(声学回声消除)
RTC 语音测试链路拆解
RTC 语音测试链路拆解
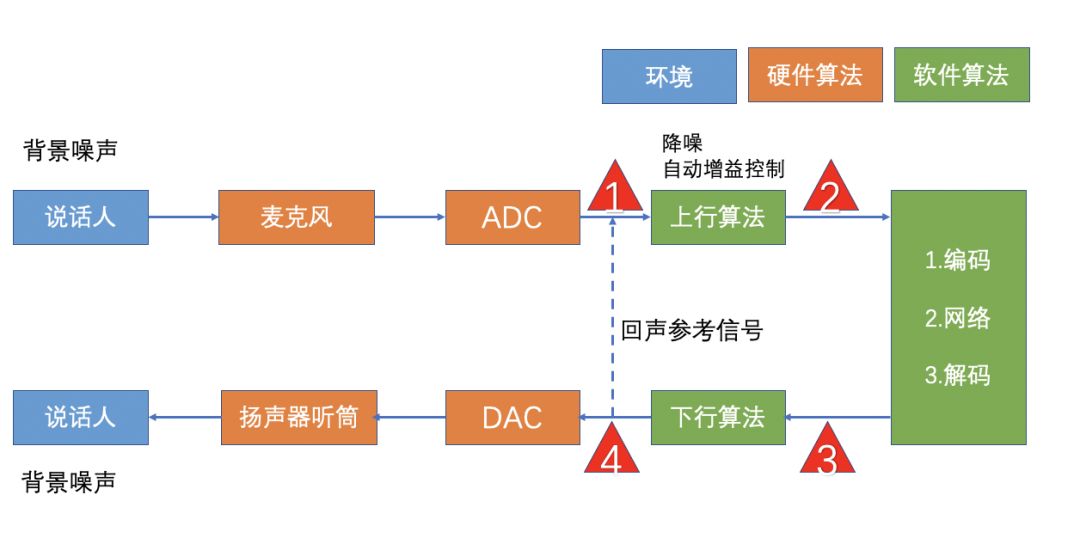
音频质量测试方案

客观测试方法
有效频宽
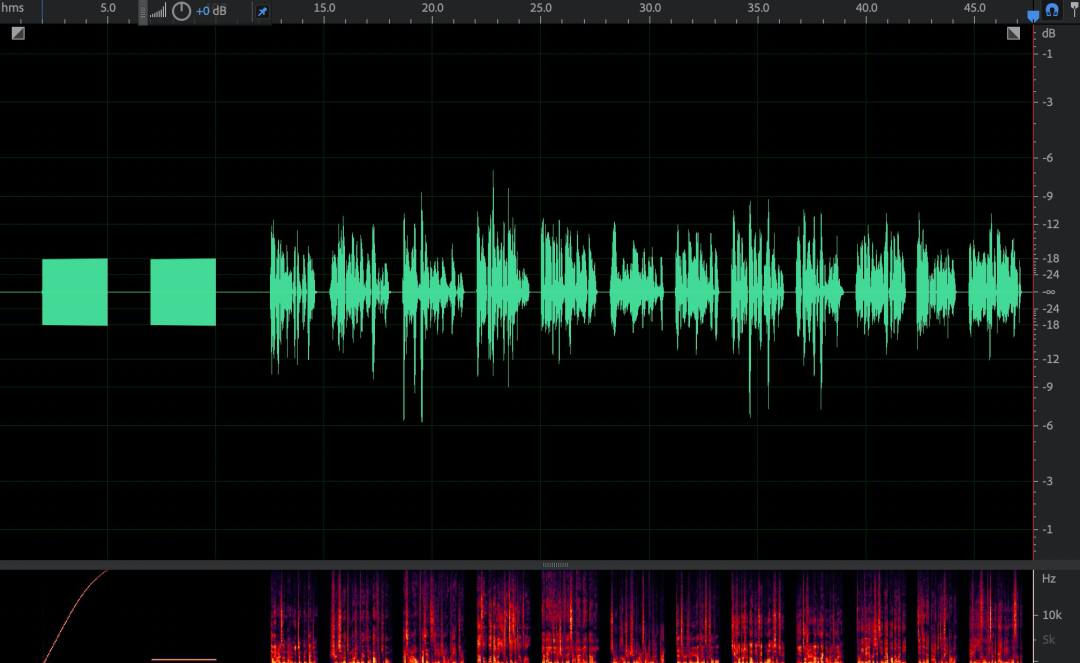
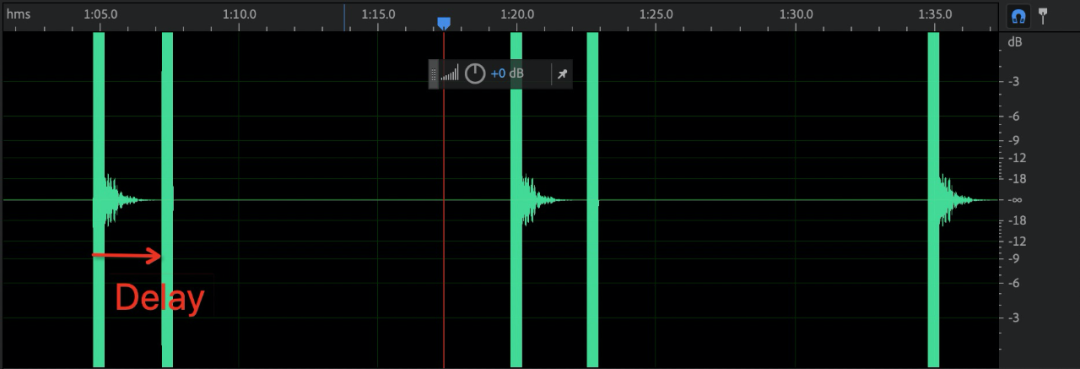
端到端延迟
测试素材:一段连续的单音。
指标计算:录制文件中读取未经过传输的音频起始时间记为 t1,读取经过会议传输的音频起始时间记为 t2,则 Delay=t2-t1。
ANS
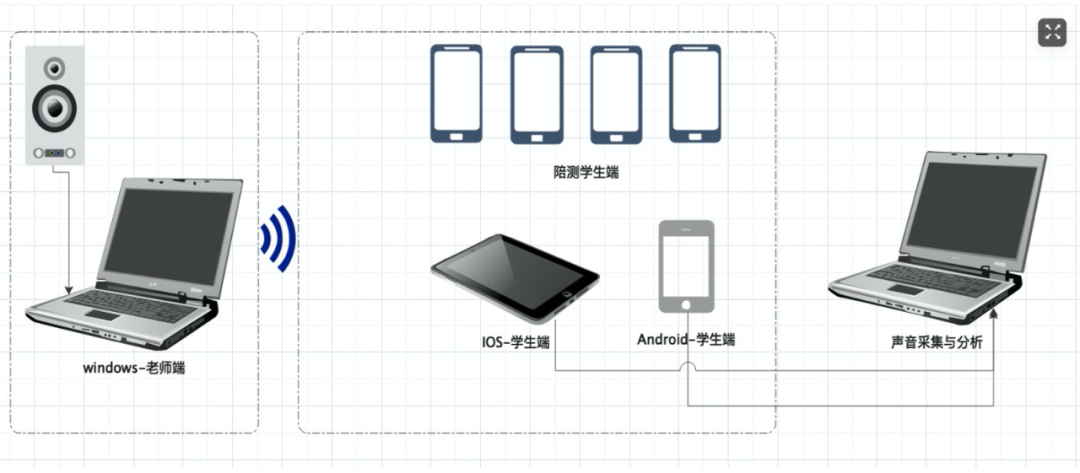
测试拓扑
测试素材
分类 | 音频素材 | 音频素材 |
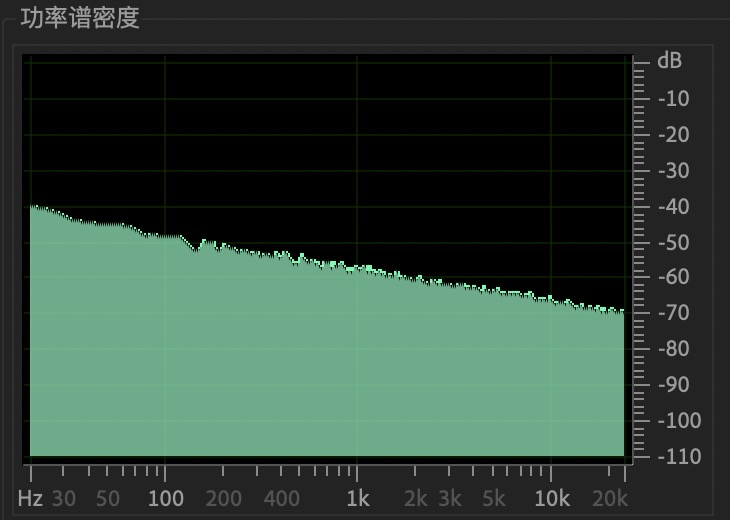
声学噪声 | 白噪声 | 如下是粉红噪声示意图:
|
粉红噪声 | ||
真实环境噪声 | 咖啡馆噪声 | 如下是办公环境噪声示意图:
|
汽车空间内噪声 | ||
会议室空间内噪声 | ||
办公环境噪声 | ||
餐馆环境噪声 | ||
地铁站/高铁站环境噪声 | ||
街道环境噪声 | ||
带噪人声 | 信噪比10dB | 如下是信噪比为10dB的带噪人声:
|
信噪比15dB | ||
信噪比25dB |
指标计算
AGC
测试拓扑
测试素材
分类 | 音频素材 | 音频素材 |
阶梯音量人声 | “大-小-大”平稳性声音素材(以3dB步长音量增减) | 如下是“大-小-大”平稳性声音素材示意图:
|
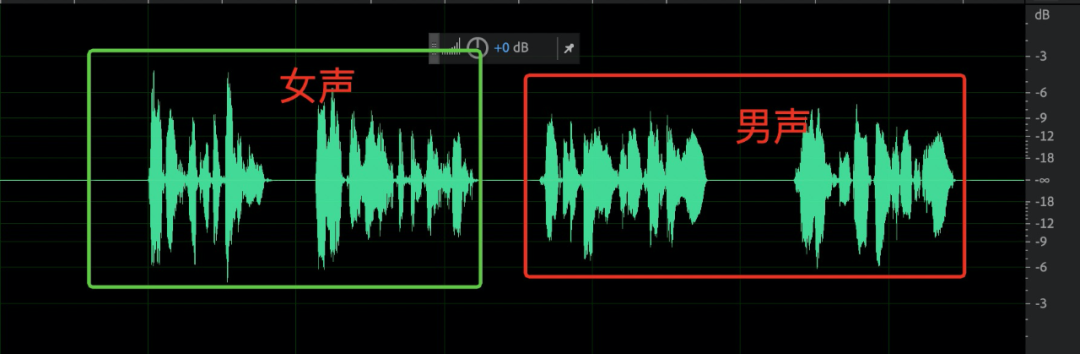
不同音量男声&女声(打分) | 小音量(打分) | 如下是用于打分中音量人声:
|
中音量(打分) | ||
大音量(打分) |
指标计算
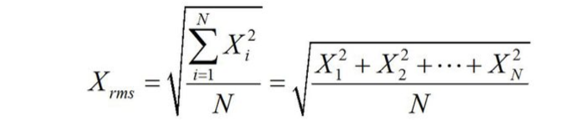
测试拓扑
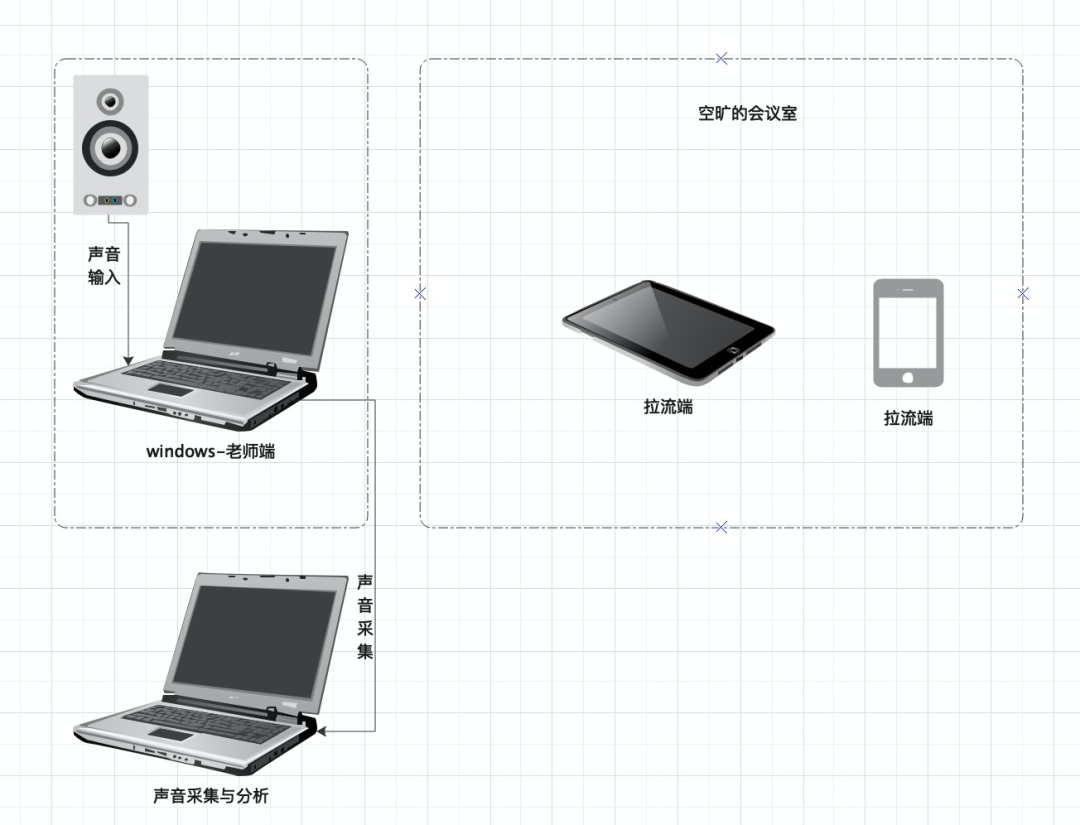
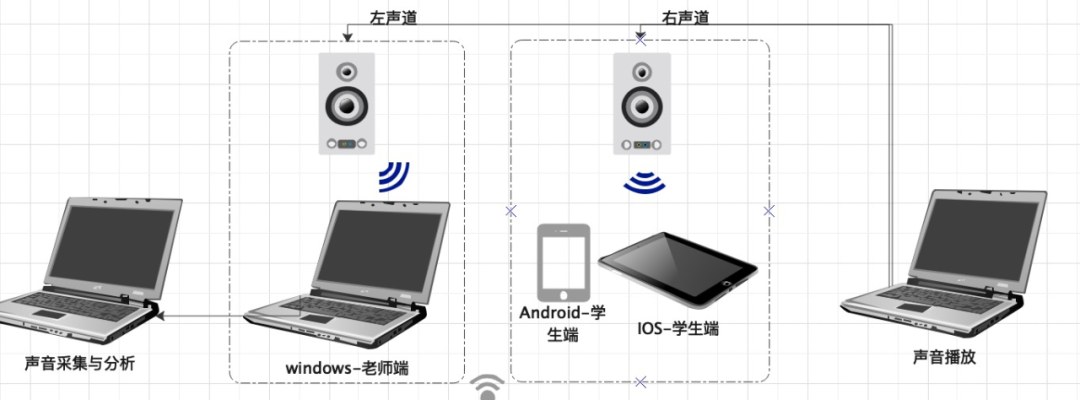
测试素材
分类 | 音频素材 | 音频素材 |
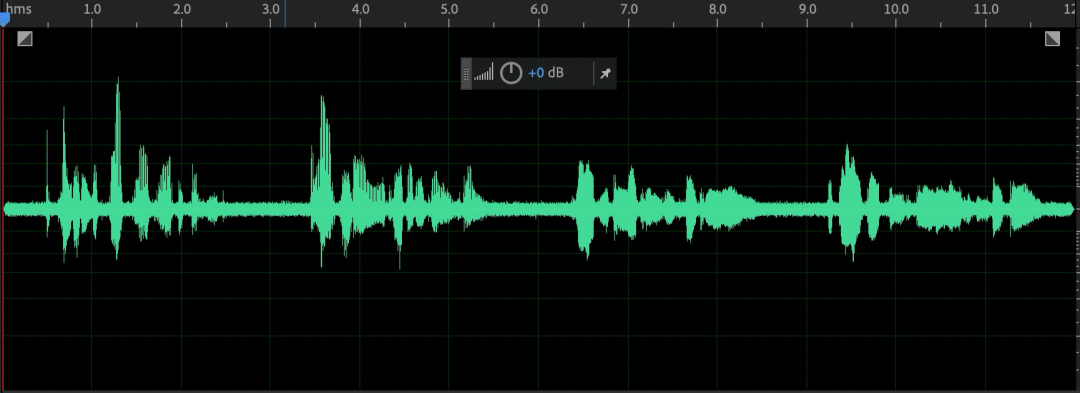
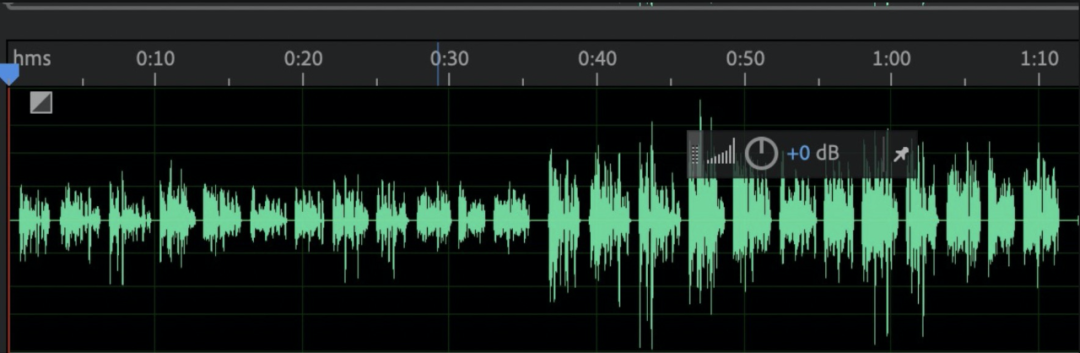
单讲 | 连续标准人声素材(男声、女声、孩童、老人) | 连续人声素材示意图:
|
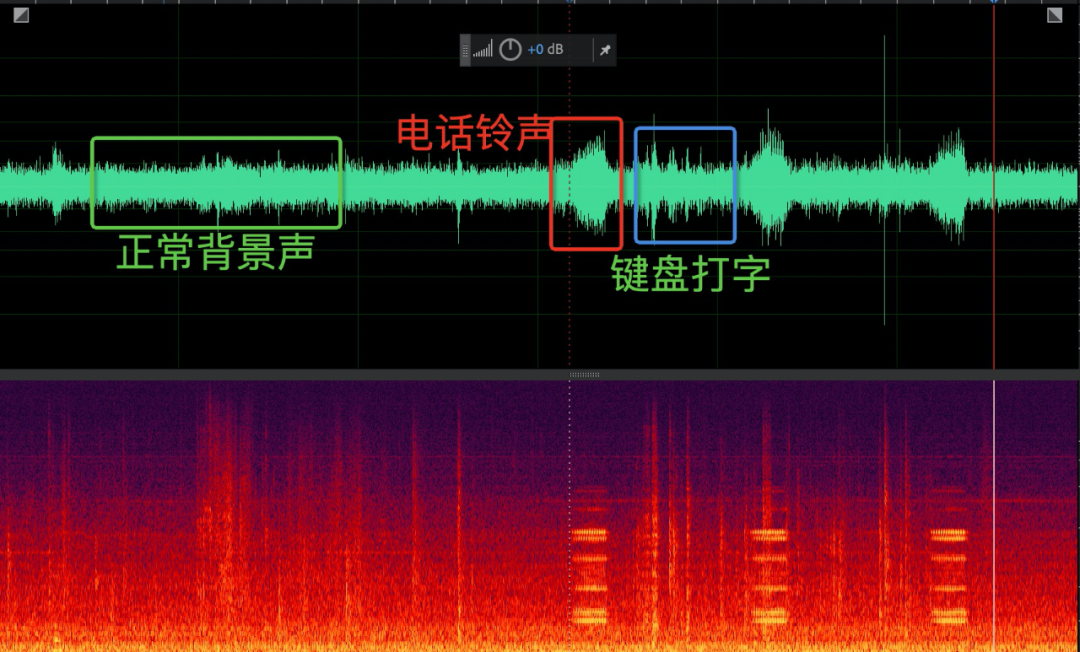
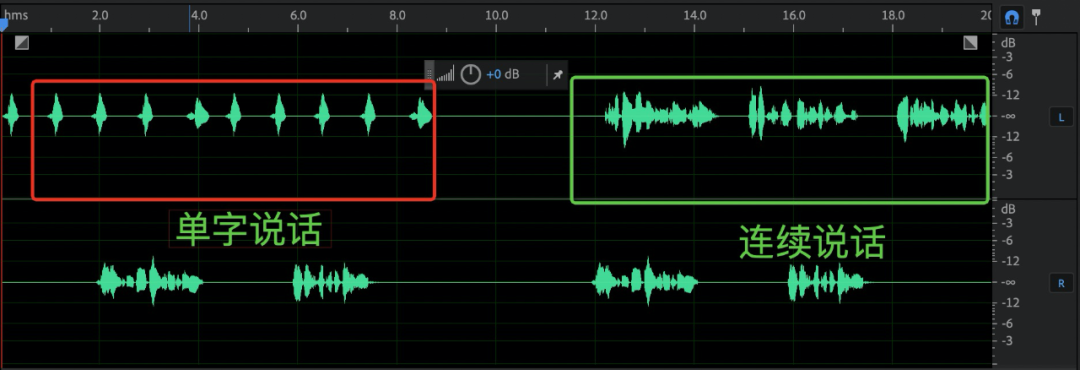
双讲 | 双讲人声素材(包含连续说话、单字说话) | 双讲人声素材(包含连续说话、单字说话)示意如下:
|
指标计算
测试拓扑:参考 ANS 测试拓扑。
测试素材:ITU-P863 提供标准人声素材。
指标计算:如下框架图展示了 STOI 计算流程,当前业内已有 matlab 和 python 对该算法的工程实现。
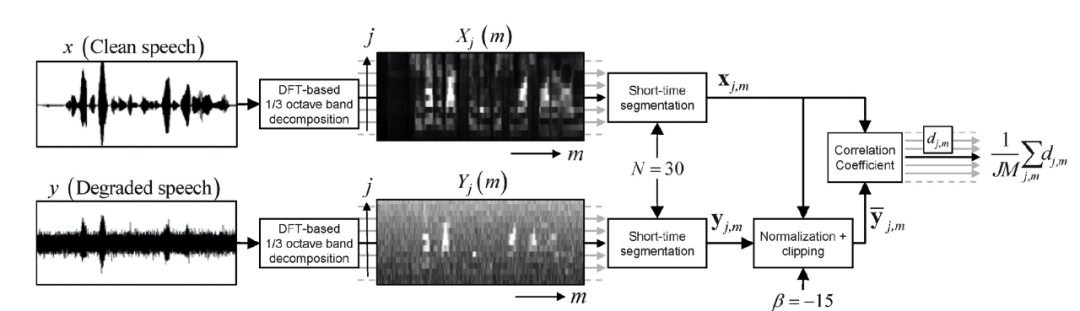
测试拓扑:参考 ANS 测试拓扑。
测试素材:ITU-P863 提供标准人声素材 &VQT 内置语音测试素材。
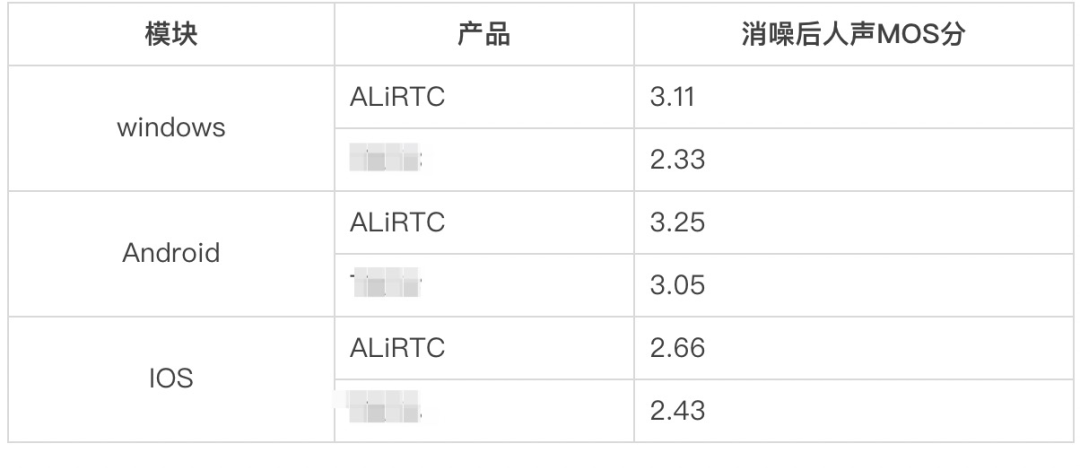
指标计算:POLQA MOS 分。
测试拓扑:参考 ANS 测试拓扑。
测试方法:测试素材:ITU-P863 提供标准人声素材。
指标计算:PESQ MOS 分
主观测试方法
评分方法

评价维度

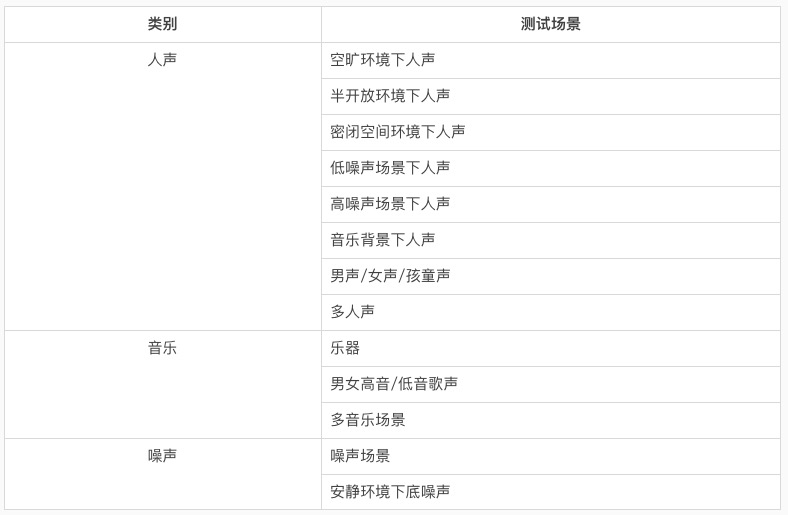
测试场景
技术交流,欢迎加我微信:ezglumes ,拉你入技术交流群。
推荐阅读:
觉得不错,点个在看呗~

评论