一、二分查找
二分查找(Binary Search)算法,也叫折半查找算法。O(logn) 非常高效的查找算法。在不存在重复元素的有序数组中,查找值等于给定值的元素。
eg:数组元素 1 3 4 5 7 8 9 10
mid的位置就是(起点下标+ 终点下标)/2下取整 ,我要查找1,先和5比较,然后和3比较。
eg: public int bsearch(int[] a, int n, int value) {
int low = 0;
int high = n - 1;
while (low <= high) {
int mid = (low + high) / 2;
if (a[mid] == value) {
return mid;
} else if (a[mid] < value) {
low = mid + 1;
} else {
high = mid - 1;
}
}
return -1;
需要着重掌握它的三个容易出错的地方:终止条件、区间上下界更新方法、返回值选择。
小结:二分查找比较好理解,每次一分为二查一半,二分查找算法虽然性能比较优秀,但应用场景也比较有限。底层必须依赖数组,并且还要求数据是有序的。对于较小规模的数据查找,我们直接使用顺序遍历就可以了,二分查找的优势并不明显。二分查找更适合处理静态数据,也就是没有频繁的数据插入、删除操作。数据量太大不能用二分查找。
二、跳表
1、跳表(Skip list):
有序链表加多级索引的结构,就是跳表。
2、跳表的时间空间复杂度:
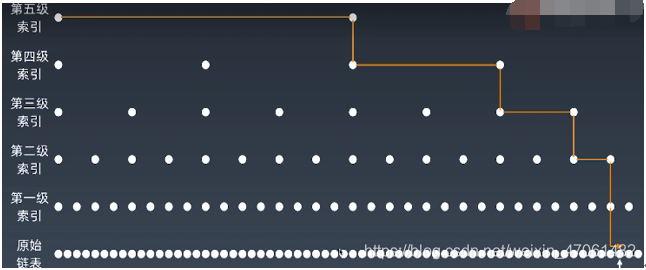
假设有序链表每两个结点会抽出一个结点作为上一级索引的结点,不断升维度,那第一级索引的结点个数大约就是 n/2,依次类推 n/2、 n/4、 n/8 、第k级索引的结点个数就是n/(2k),假设最高级的索引有 2 个结点。那么 n/(2k)=2,从而求得 k=log2n-1。如果包含原始链表这一层,整个跳表的高度就是 log2n。我们在跳表中查询某个数据的时候,如果每一层都要遍历 m 个结点,那在跳表中查询一个数据的时间复杂度就是 O(m*logn)。m为常量级的数,所以跳表插入、删除、查找的时间复杂度O(logn) 。

如上索引节点的总数分析,所以跳表的空间复杂度是 O(n)。也就是说,如果将包含 n 个结点的单链表构造成跳表,我们需要额外再用接近 n 个结点的存储空间。
但是通常实际应用中,原始链表中存储的有可能是很大的对象,而索引结点只需要存储关键值和几个指针,并不需要存储对象,所以当对象比索引结点大很多时,那索引占用的额外空间就可以忽略了。
小结:跳表比较优秀的动态数据结构,有序链表加多级索引的结构,可以支持快速地插入、删除、查找操作,时间复杂度度都是o(logn),区间查找效率很高,类似于基于单链表实现了二分查找,在一些地方可以用来替代平衡树,如redis的有序集合、levelDB。是一种升维,空间换时间的思想,空间复杂度是 O(n)。可以通过改变索引构建策略,有效平衡执行效率和内存消耗。相比红黑树实现简单。
三、散列表(哈希表)
1、散列表
散列表的英文叫“Hash Table”,我们平时也叫它“哈希表”或者“Hash 表”。散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展。我们把一些键(key)或者关键字转化为数组下标的映射方法就叫作散列函数(或“Hash 函数”“哈希函数”),而散列函数计算得到的值就叫作散列值(或“Hash 值”“哈希值”)。
原理:散列表用的就是数组支持按照下标随机访问的时候,时间复杂度是 O(1) 的特性。我们通过散列函数把元素的键值映射为下标,然后将数据存储在数组中对应下标的位置。当我们按照键值查询元素时,我们用同样的散列函数,将键值转化数组下标,从对应的数组下标的位置取数据。
2、散列函数设计的基本要求
散列函数计算得到的散列值是一个非负整数(好理解,要映射成数组下标嘛);
如果 key1 = key2,那 hash(key1) == hash(key2);
如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)。
3、散列冲突
再好的散列函数也无法避免散列冲突。那究竟该如何解决散列冲突问题呢?我们常用的散列冲突解决方法有两类,开放寻址法(open addressing)和链表法(chaining)。
1)开放寻址法:
线性探测:当我们往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止。
二次探测:所谓二次探测,跟线性探测很像,线性探测每次探测的步长是 1,那它探测的下标序列就是 hash(key)+0,hash(key)+1,hash(key)+2……而二次探测探测的步长就变成了原来的“二次方”,也就是说,它探测的下标序列就是
hash(key)+0,hash(key)+12,hash(key)+22…
双重散列:我们使用一组散列函数 hash1(key),hash2(key),hash3(key)……我们先用第一个散列函数,如果计算得到的存储位置已经被占用,再用第二个散列函数,依次类推,直到找到空闲的存储位置。
散列表跟数组一样,不仅支持插入、查找操作,还支持删除操作。对于使用线性探测法解决冲突的散列表,删除不能单纯地把要删除的元素设置为空。也是将删除的元素,特殊标记为 deleted。不然会导致原来的查找算法失效。当线性探测查找的时候,遇到标记为 deleted 的空间,并不是停下来,而是继续往下探测。
不管采用哪种探测方法,当散列表中空闲位置不多的时候,散列冲突的概率就会大大提高。为了尽可能保证散列表的操作效率,一般情况下,我们会尽可能保证散列表中有一定比例的空闲槽位。我们用装载因子(load factor)来表示空位的多少:
`散列表的装载因子=填入表中的元素个数/散列表的长度`
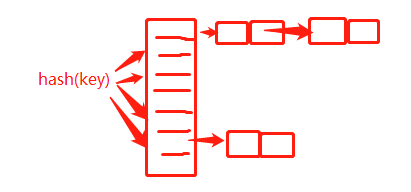
2)链表法:
4、散列冲突解决方法优势和劣势
当数据量比较小、装载因子小的时候,适合采用开放寻址法。这也是 Java 中的ThreadLocalMap使用开放寻址法解决散列冲突的原因。
大部分情况下,链表法更加普适。基于链表的散列冲突处理方法比较适合存储大对象、大数据量的散列表,而且,比起开放寻址法,它更加灵活,支持更多的优化策略,比如红黑树、跳表,来避免散列表时间复杂度退化成O(n),抵御散列冲突攻击。比如HashMap、LinkedHashMap就是使用链表法解决散列冲突 。
5、如何设计散列函数
要尽可能让散列后的值随机且均匀分布,这样会尽可能减少散列冲突,即便冲突之后,分配到每个槽内的数据也比较均匀。
除此之外,散列函数的设计也不能太复杂,太复杂就会太耗时间,也会影响到散列表的性能。
常见的散列函数设计方法:直接寻址法、平方取中法、折叠法、随机数法等。
6、装载因子的阈值和扩容
当散列表的装载因子超过某个阈值时,就需要进行扩容。装载因子阈值需要选择得当。如果太大,会导致冲突过多;如果太小,会导致内存浪费严重. 通过设置装载因子的阈值来控制是扩容还是缩容,支持动态扩容的散列表,插入数据的时间复杂度使用摊还分析法。
装载因子阈值的设置要权衡时间、空间复杂度。如果内存空间不紧张,对执行效率要求很高,可以降低负载因子的阈值;相反,如果内存空间紧张,对执行效率要求又不高,可以增加负载因子的值,甚至可以大于 1。
分批扩容:
为了解决一次性扩容耗时过多的情况,分批完成:
①分批扩容的插入操作:当有新数据要插入时,我们将数据插入新的散列表,并且从老的散列表中拿出一个数据放入新散列表。每次插入都重复上面的过程。这样插入操作就变得很快了。
②分批扩容的查询操作:先查新散列表,再查老散列表。
③通过分批扩容的方式,任何情况下,插入一个数据的时间复杂度都是O(1)。
小结:散列表支持插入、查找操作,还支持删除。常用的散列冲突解决方法有两类,开放寻址法和链表法。其中采用开放寻址法解决冲突时,删除需特殊注意标记,以保证原有查找算法的有效。散列函数设计原则要合适,不能太复杂,也不能散列冲突太多。装载因子过大可能导致冲突频繁,过小可能造成空间浪费。以及装载因子过大时,避免低效扩容如何分批扩容。
Java 中 LinkedHashMap 、HashMap 就采用了链表法解决冲突,ThreadLocalMap 是通过线性探测的开放寻址法来解决冲突。
四、哈希函数
1、哈希函数
将任意长度的二进制值串映射为固定长度的二进制值串,这个映射的规则就是哈希算法,而通过原始数据映射之后得到的二进制值串就是哈希值。
2、优秀的哈希算法需要满足的几点要求:
①单向哈希:
从哈希值不能反向推导出哈希值(所以哈希算法也叫单向哈希算法)。
②篡改无效:
对输入敏感,哪怕原始数据只修改一个Bit,最后得到的哈希值也大不相同。
③散列冲突:
散列冲突的概率要很小,对于不同的原始数据,哈希值相同的概率非常小。
④执行效率:
哈希算法的执行效率要尽量高效,针对较长的文本,也能快速计算哈希值。
3、哈希算法的应用
最常见的几个应用:安全加密、唯一标识、数据校验、散列函数、负载均衡、数据分片、分布式存储等。例如:
安全加密:
最常用于加密的哈希算法:
MD5 Message-Digest Algorithm,MD5消息摘要算法
SHA:Secure Hash Algorithm,安全散列算法
DES:Data Encryption Standard,数据加密标准
AES:Advanced Encryption Standard,高级加密标准
负载均衡算法有很多,比如轮询、随机、加权轮询等。
盐
原密码是123456,如果加盐,密码123456加盐后可能是12ng34qq56zz,再对加盐后的密码进行hash后值就与原密码hash后的值完全不同了。而且加盐的方式有很多种,可以是在头部加,可以在尾部加,还可在内容中间加,甚至加的盐还可以是随机的。这样即使用户使用的是最常用的密码,黑客拿到密文后破解的难度也很高。也是一种常见的应用,防止攻击字典表的一种方案。