
不到1000行代码,GitHub 1400星,天才黑客开源深度学习框架tinygrad

极市导读
最近,天才黑客 George Hotz 开源了一个小型深度学习框架 tinygrad,兼具 PyTorch 和 micrograd 的功能。tinygrad 的代码数量不到 1000 行,目前该项目获得了 GitHub 1400 星。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
在深度学习时代,谷歌、Facebook、百度等科技巨头开源了多款框架来帮助开发者更轻松地学习、构建和训练不同类型的神经网络。而这些大公司也花费了很大的精力来维护 TensorFlow、PyTorch 这样庞大的深度学习框架。
除了这类主流框架之外,开发者们也会开源一些小而精的框架或者库。比如今年 4 月份,特斯拉人工智能部门主管 Andrej Karpathy 开源了其编写的微型 autograd 引擎 micrograd,该引擎还用 50 行代码实现了一个类 PyTorch api 的神经网络库。目前,micrograd 项目的 GitHub star 量达到 1200 星。
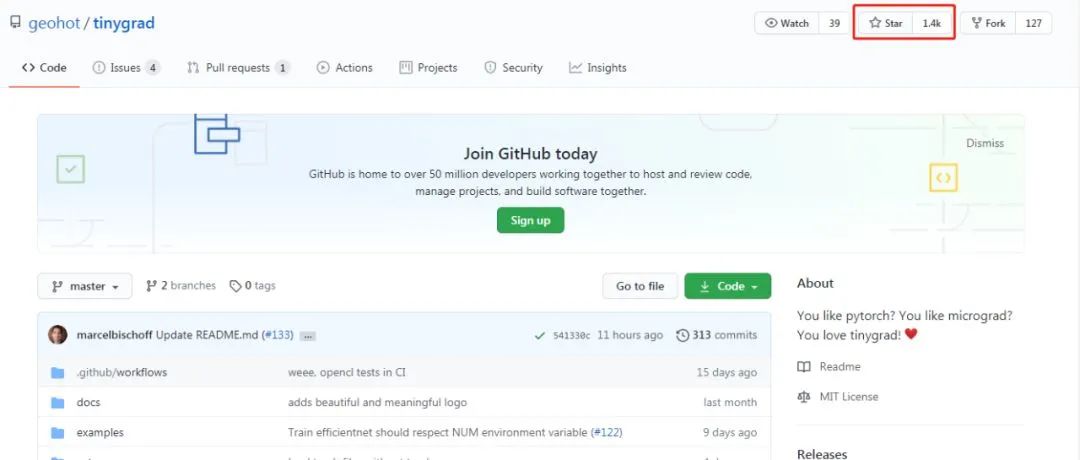
不久前,天才黑客 George Hotz(乔治 · 霍兹)开源了一个小型 Autograd Tensor 库 tinygrad,它介于 PyTorch 和 micrograd 之间,能够满足做深度学习的大部分要求。上线不到一个月,该项目在 GitHub 上已经获得 1400 星。
pip3 install tinygrad --upgrade
from tinygrad.tensor import Tensor
x = Tensor.eye(3)
y = Tensor([[2.0,0,-2.0]])
z = y.matmul(x).sum()
z.backward()
print(x.grad) # dz/dx
print(y.grad) # dz/dy
import torch
x = torch.eye(3, requires_grad=True)
y = torch.tensor([[2.0,0,-2.0]], requires_grad=True)
z = y.matmul(x).sum()
z.backward()
print(x.grad) # dz/dx
print(y.grad) # dz/dy
from tinygrad.tensor import Tensor
import tinygrad.optim as optim
from tinygrad.utils import layer_init_uniform
class TinyBobNet:
def __init__(self):
self.l1 = Tensor(layer_init_uniform(784, 128))
self.l2 = Tensor(layer_init_uniform(128, 10))
def forward(self, x):
return x.dot(self.l1).relu().dot(self.l2).logsoftmax()
model = TinyBobNet()
optim = optim.SGD([model.l1, model.l2], lr=0.001)
# ... and complete like pytorch, with (x,y) data
out = model.forward(x)
loss = out.mul(y).mean()
loss.backward()
optim.step()
from tinygrad.tensor import Tensor
(Tensor.ones(4,4).cuda() + Tensor.ones(4,4).cuda()).cpu()
ipython3 examples/efficientnet.py https://upload.wikimedia.org/wikipedia/commons/4/41/Chicken.jpg
ipython3 examples/efficientnet.py webcam
python -m pytest



推荐阅读

评论