
Alluxio简介
共 2947字,需浏览 6分钟
·
2021-08-17 09:42
Alluxio简介
Alluxio是什么
Alluxio(之前名为 Tachyon)是世界上第一个以内存为中心的虚拟的分布式存储系统。 它统一了数据访问的方式,为上层计算框架和底层存储系统构建了桥梁。应用只需要连接Alluxio即可访问存储在底层任意存储系统中的数据。此外,Alluxio的以内存为中心的架构使得数据的访问速度能比现有常规方案快几个数量级。
在大数据生态系统中,Alluxio 介于计算框架(如 Apache Spark,Apache MapReduce,Apache Flink)和现有的存储系统(如 Amazon S3,OpenStack Swift,GlusterFS,HDFS, Ceph,OSS)之间。Alluxio 为大数据软件栈带来了显著的性能提升。 用户可以以独立集群方式(如Amazon EC2)运行Alluxio,也可以从Apache Mesos或Apache YARN上启动Alluxio。
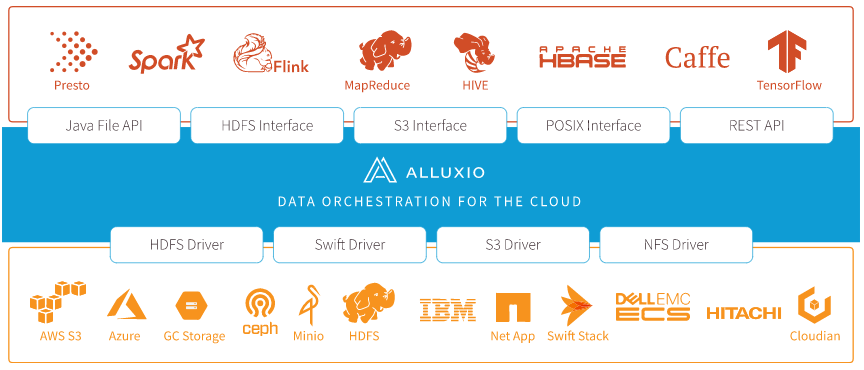
Alluxio 与 Hadoop是兼容的。 这意味着已有的Spark和MapReduce程序可以不修改代码直接在 Alluxio上运行。Alluxio 是一个已在多家公司部署的开源项目(Apache License 2.0)。
Alluxio 是发展最快的开源大数据项目之一。 自 2013 年 4 月开源以来,已有超过 100 个组织机构的 250 多贡献者参与到 Alluxio 的开发中。包括阿里巴巴, Alluxio, 百度, 卡内基梅隆大学,IBM,Intel, 南京大学, Red Hat,UC Berkeley和 Yahoo。Alluxio 处于伯克利数据分析栈(BDAS)的存储层,也是 Fedora 发行版的一部分。

Alluxio的由来
内存计算思想在三个层面的体现:
内存数据库:HANA,Redis,MemCached等 内存计算引擎:Spark、Pregel、Trinity等 内存文件系统:Tachyon=>Alluxio
最初的设计思想:研究实现一个基于分布式内存的文件存储系统,提高大数据处理时的IO性能。
随着Tachyon系统逐步深入的研发,设计目标有了很大的提升
分布式文件系统:加速大数据处理系统数据访问 现有底层大数据存储系统的集成与统一访问:避免已有大数据存储平台的迁移代价 形成统一化的数据共享与交换平台:支持各种上层的大数据处理系统
问题:
传统大数据分析系统通过磁盘文件系统(如HDFS)来共享数据,大量磁盘I/O成为影响分析性能的瓶颈 大数据计算引擎的处理进程(spark的Executor,MapReduce的Child JVM等)崩溃出错后,缓存的数据也会丢失。 基于内存的存储数据冗余,对象太多导致Java GC 时间过长。
解决方案:
Alluxio为大数据分析流水线提供内存级数据共享服务 内存中的数据存放在Alluxio中,即使计算引擎处理进程崩溃,内存中的数据仍然不会丢失。 存放在Alluxio内存中的数据无冗余,同时GC开销大大减少
系统架构
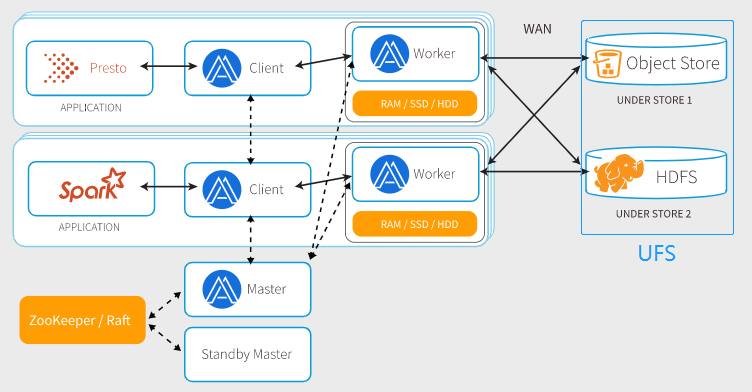
Master 管理文件和对象元数据 监控各个Worker状态 Worker 管理本地MEM、SSD和HDD Client 向用户和应用提供访问接口 向Master和Worker发送请求 Under File System 用于备份
优势
通过简化应用程序访问其数据的方式(无论数据是什么格式或位置),Alluxio 能够帮助克服从数据中提取信息所面临的困难。Alluxio 包括如下优势。
内存速度 I/O
Alluxio 能够用作分布式共享缓存服务,这样与 Alluxio 通信的计算应用程序可以透明地缓存频繁访问的数据(尤其是从远程位置),以提供内存级 I/O 吞吐率。此外,Alluxio的层次化存储机制能够充分利用内存、固态硬盘或者磁盘,降低具有弹性扩张特性的数据驱动型应用的成本开销。
统一数据访问接口
Alluxio 能够屏蔽底层持久化存储系统在API、客户端及版本方面的差异,从而使整个系统易于扩展和管理。

能够将多个数据源中的数据挂载到Alluxio中 多个数据源使用统一的命名空间 用户使用统一的路径访问
提升远程存储读写性能
以Hadoop为代表的存储计算紧耦合的传统架构具有优良的计算本地性。通过在邻近所需数据的节点上来部署运行计算任务,可以尽量减少通过网络传输数据,从而有效地提升性能。然而,维持这种紧耦合结构所需要付出的成本代价正逐渐让性能优势带来的意义变得微乎其微。
Alluxio通过在当前主流的存储计算分离解耦的架构中,提供与紧耦合架构相似甚至更优的性能,来解决解耦后性能降低的难题。推荐把Alluxio与集群的计算框架并置部署(co-locate),从而能够提供靠近计算的跨存储缓存来实现高效本地性。
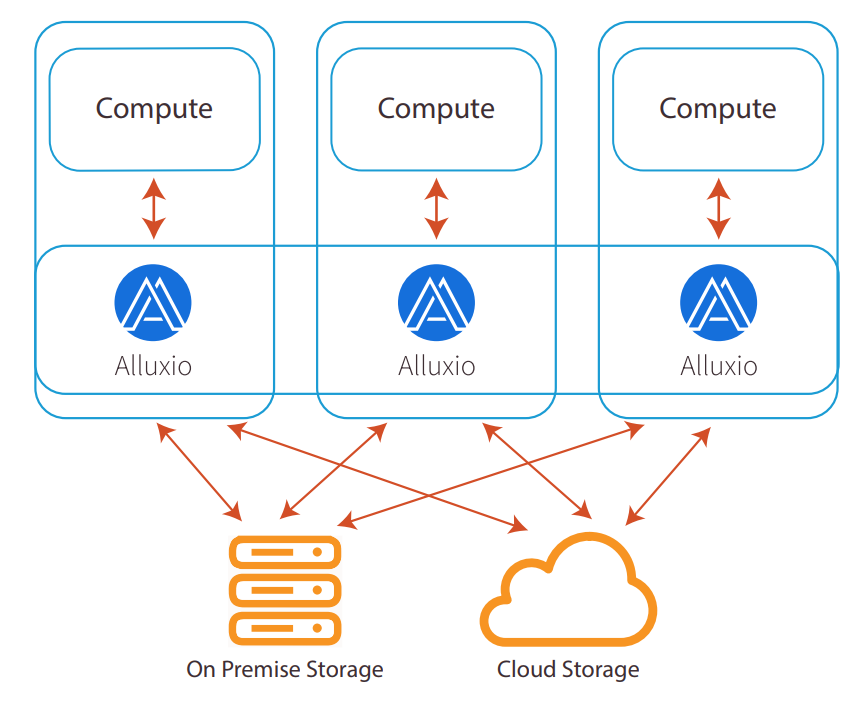
与传统的架构方案相比,Alluxio架构带来两个关键区别。
Alluxio存储中不需要保存底层存储中的所有数据,它只需要保存工作集(WorkingSet)。即使全体数据的规模非常大,Alluxio也不需要大量存储空间来存储所有数据,而是可以在有限的存储空间中只缓存作业所需要的数据。 Alluxio存储采用了一种弹性的缓存机制来管理、使用存储资源。访问热度越高的数据(如被很多作业读取的数据表),会产生越多的副本,而请求很少甚至没有复用的数据则会被逐渐替换出Alluxio存储层(其在远端存储系统中的副本不会被清除)。而以HDFS为代表的存储系统通常是采用一个固定的副本数目(如3副本),很难根据具体的数据访问热度动态调节存储资源的使用。
数据快速复用与共性
Alluxio可以帮助实现跨计算、作业间的数据快速复用和共享。
对于用户应用程序和大数据计算框架来说,Alluxio存储通常与计算框架并置。这种部署方式使Alluxio可以提供快速存储,促进作业之间的数据共享,无论它们是否在同一计算平台上运行。
集成机器学习和深度学习
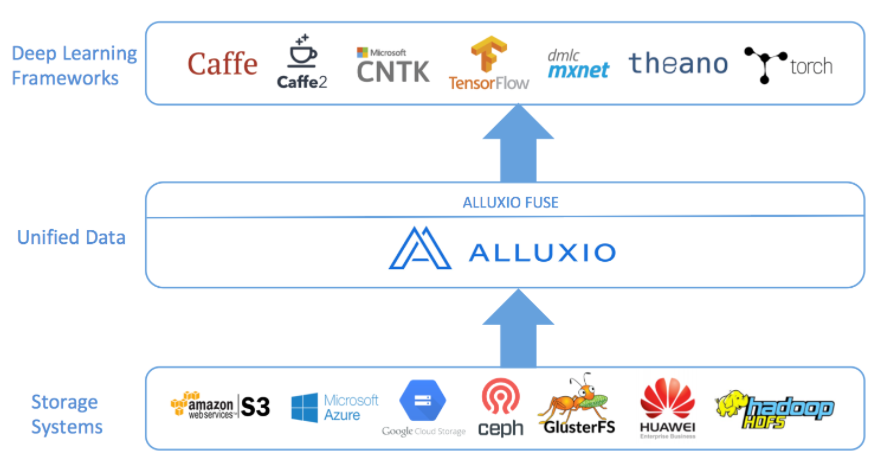
机器学习和深度学习框架往往需要从Hadoop或对象存储中提取大规模数据,这通常是手动且非常耗时的过程。通过Alluxio POSIX API克服该问题。
Alluxio的FUSE功能支持POSIX兼容的API,因此通过Alluxio,TensorFlow、 Caffe等框架以及其他基于Python的模型可以使用传统文件系统的访问方式直接访问任何存储系统中的数据。
集群运维问题
权限问题
需要赋值alluxio client客户端文件及其父目录 755权限,最好放到 /opt 或者/usr/local 目录下,不要放到/home/用户/ 目录下,因为/home/用户 目录及其父目录赋值 755权限后可能会破坏ssh免密登录。
挂载HDFS问题
挂载HDFS文件需要打通 alluxio到 hdfs namenode 8020端口和hdfs datanode 9866端口