用可视化理解神经网络!
尽管如此,仍有一些人对此表示关切。一是很难去理解神经网络真正在做什么。如果一个人训练得很好,就可以获得高质量的结果,但是要理解它是如何做到的是很困难的。如果网络出现故障,很难解释出了什么问题。
虽然理解深层神经网络的一般行为很有挑战性,但事实证明,探索低维深层神经网络要容易得多——每层只有几个神经元的网络。事实上,我们可以通过可视化来理解这种网络的行为和训练。这一观点将使我们对神经网络的行为有更深的直觉,并观察到神经网络与一个称为拓扑学的数学领域之间的联系。
接下来有许多有趣的事情,包括能够对特定数据集进行分类的神经网络复杂性的基本下界。
一个简单的例子
让我们从一个非常简单的数据集开始,平面上的两条曲线上的所有点。神经网络将试着把点分为两类。
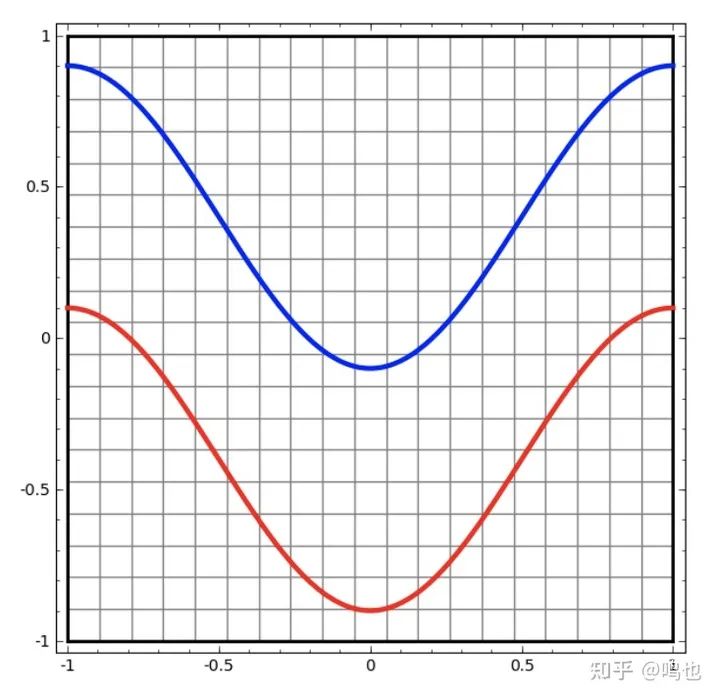
一个最直观的方式去观察神经网络的行为(或任何分类算法),就是看看它是如何对每个可能的数据点进行分类的。
我们将从最简单的神经网络开始,这个只有一个输入层和一个输出层。这样的网络只是试图用一条线将这两类数据分开。
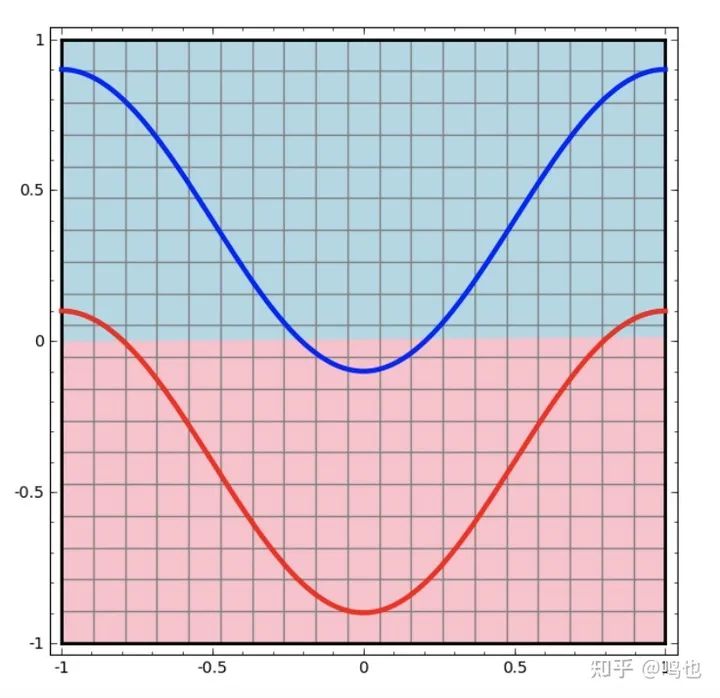
这种网络不够有趣。现代神经网络通常在输入和输出之间有多层,称为“隐藏”层。但这个网络好歹有一层可研究。
一个简单的网络图,来自维基百科
类似地,我们可以通过查看神经网络对其域中不同点所做的操作,来观察该网络的行为。下面这个图用比直线更复杂的曲线来分离数据。
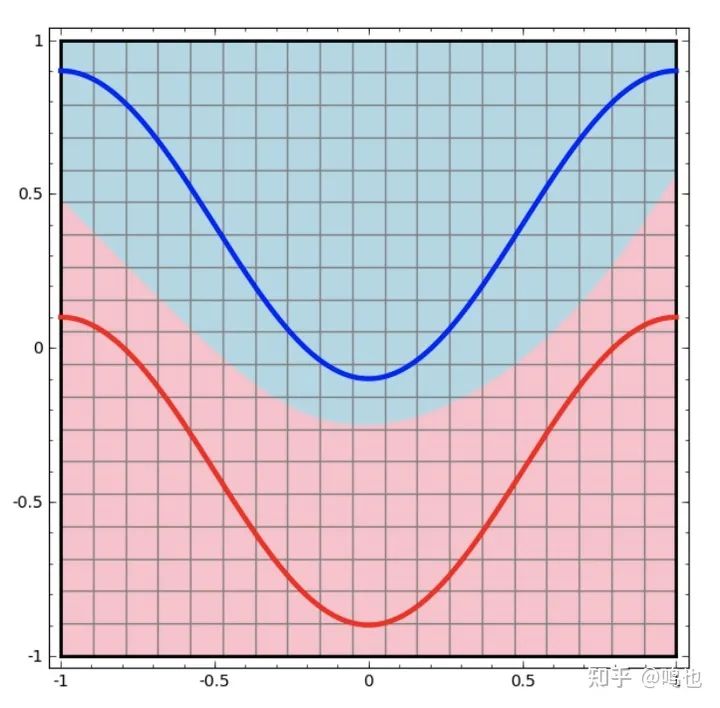
对于每一层,网络都会转换数据,创建一个新的表示形式。我们可以查看这些表示形式中的数据以及网络如何对它们进行分类。当我们得到最终的表示时,网络只会在数据中画一条线(可能在更高的维度中,是一个超平面)。
在前面的可视化中,我们查看了数据的“原始”表示形式。你可以把它看作是我们在看「输入层」。现在我们将在它被第一层转化之后再看一看。你可以认为这是我们在看「隐藏层」。
每一个维度都对应于该层神经元的激活。
隐藏层学习的一种表示,这样使得数据可以线性分离
层的连续可视化
在上一节中概述的方法中,我们通过查看与每一层对应的表示来学习理解网络。这给了我们一个离散的表示列表。
棘手的部分在于理解我们如何从一个到另一个。谢天谢地,神经网络层有很好的特性,使这变得非常容易。
在神经网络中有各种不同的层。我们将讨论 tanh 层作为一个具体例子。一个tanh层,包括:
用“权”矩阵 W 作线性变换 用向量 b 作平移 用 tanh 逐点表示
我们可以将其视为一个连续的转换,如下所示:
其他标准层的情况大致相同,由仿射变换和单调激活函数的逐点应用组成。
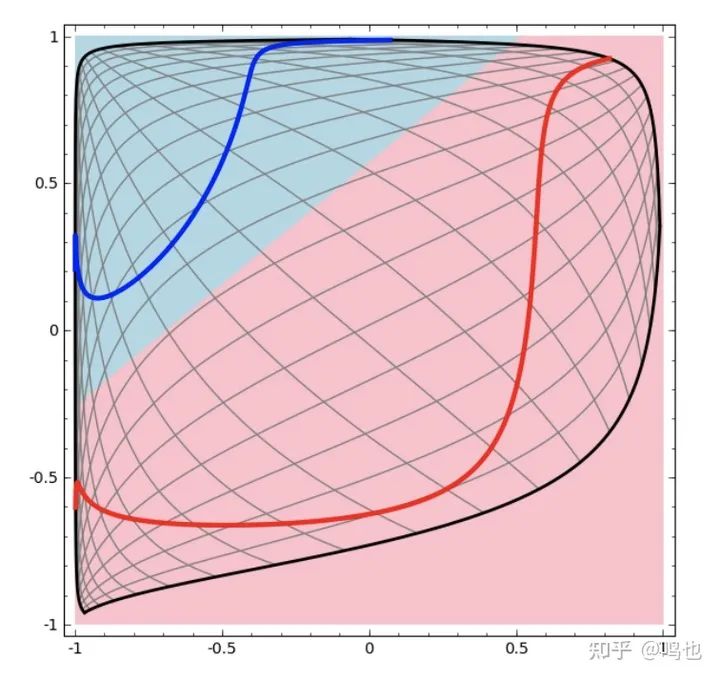
我们可以应用这种技术来理解更复杂的网络。例如,下面的网络使用四个隐藏层对两个稍微纠缠的螺旋进行分类。随着时间的推移,我们可以看到,为了对数据进行分类,它从“原始”的表示方式转变为更高级别的表示方式。虽然螺旋最初是纠缠在一起的,但到最后它们是线性可分离的。
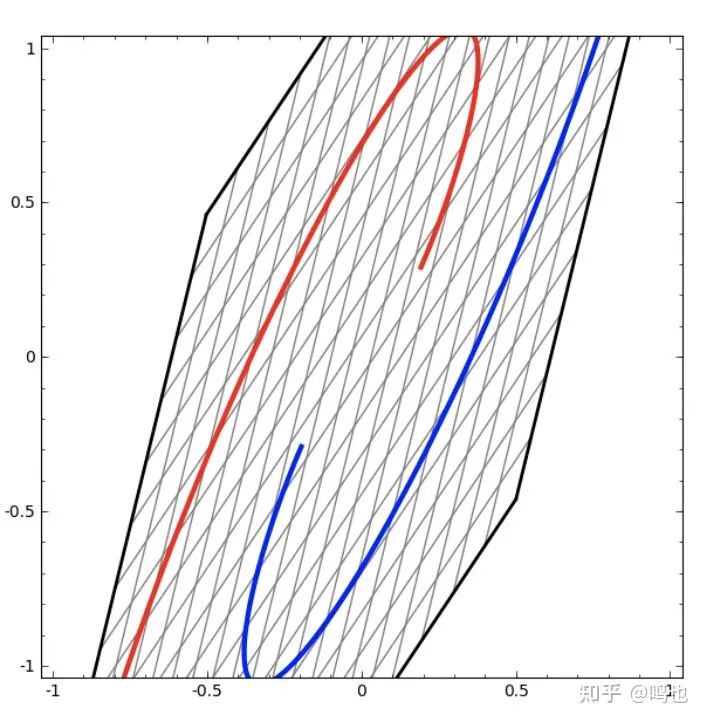
另一方面,下面的网络,也使用多层,但无法分类两个更纠缠的螺旋。
这里值得明确指出的是,这些任务只是有些挑战性,因为我们使用的是低维神经网络。如果我们使用更广泛的网络,这一切都会很容易。
(Andrej Karpathy基于ConvnetJS制作了一个很好的demo,让您可以通过这种可视化的训练交互式地探索网络!)
tanh层的拓扑
每一层都会拉伸和挤压空间,但它从不切割、断裂或折叠空间。直观上来看,它保持了拓扑性质。例如,如果一个集合在之前连续,那么它将在之后也如此(反之亦然)。
像这样不影响拓扑的变换称为同胚。形式上,它们是双向连续函数的双射。
定理:神经网络的一层有N个输入和N个输出,这层的映射是同胚,如果权重矩阵 W 是非奇异的。
证明:让我们一步一步地考虑这个问题
假设 W 存在非零行列式。那么它是一个具有线性逆的双射线性函数。线性函数是连续的。那么乘以 W 是同胚 translations是同胚的 tanh(和sigmoid和softplus,但不是ReLU)是具有连续逆的连续函数。它们就是双射,逐点的应用它们就是一个同胚
因此,如果 W 存在一个非零行列式,我们的层就是同胚。
如果我们任意地将这些层组合在一起,这个结果仍然成立。
拓扑与分类
我们考虑一个二维数据集,它包含两类:
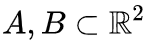
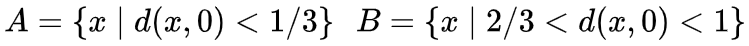
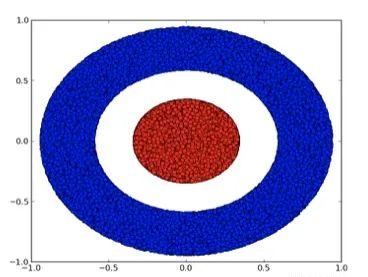
A是红的,B是蓝的
说明:如果一个神经网络没有一个包含3个或更多隐藏单元的层,不管深度如何,它都不可能对这个数据集进行分类。
如前所述,使用sigmoid单元或softmax层进行分类相当于试图找到一个超平面(在本例中是一条线)来分隔 A 和 B。由于只有两个隐藏单元,网络在拓扑上无法以这种方式分离数据,并且在这个数据集上注定会失败。
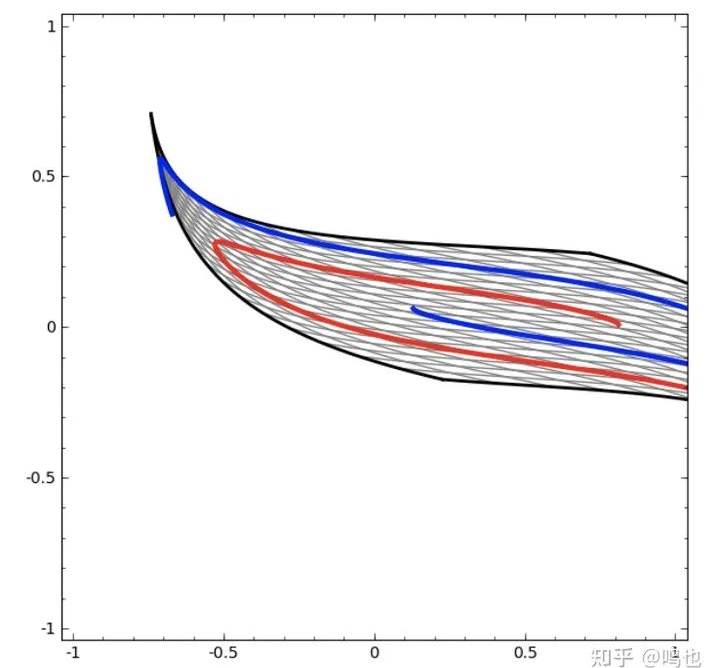
在下面的可视化中,当一个网络沿着分类线训练时,我们观察到一个隐藏的表示。正如我们所看到的,它试图学习一种方法来做到这一点。
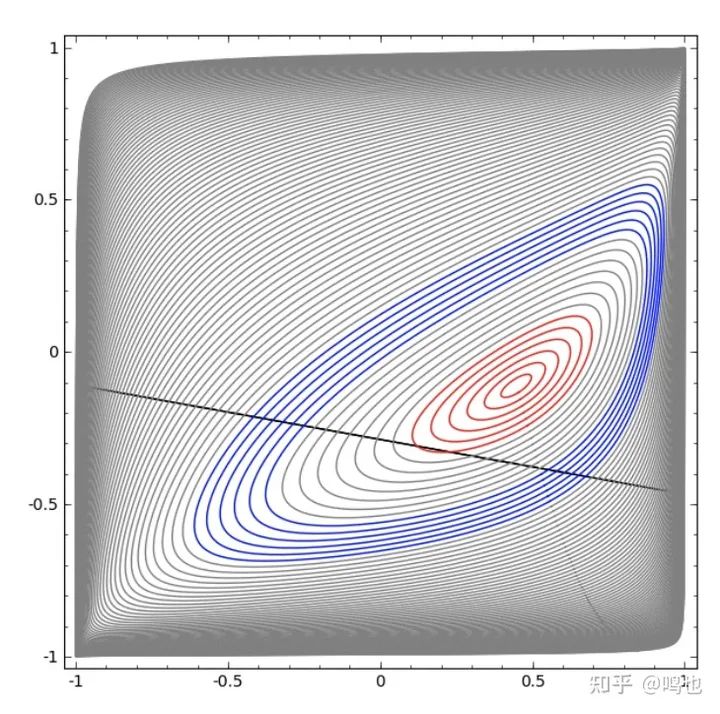
最后它被拉进了一个相当不好的局部极小值。虽然它实际上能够达到80%的分类精度。
这个例子只有一个隐藏层,但是无论如何它都会失败。
证明:要么每层是同胚,要么层的权矩阵有行列式0。如果是同胚的话,A仍然被B包围着,一条线不能把它们分开。但是假设它的行列式为0,那么数据集将在某个轴上折叠。因为我们处理的是与原始数据集同胚的东西,A 被 B 包围,A 在任何轴上塌陷意味着我们将有一些A 和 B 混合的点,它们变得无法区分。
如果我们添加第三个隐藏单元,问题就变得不重要了。
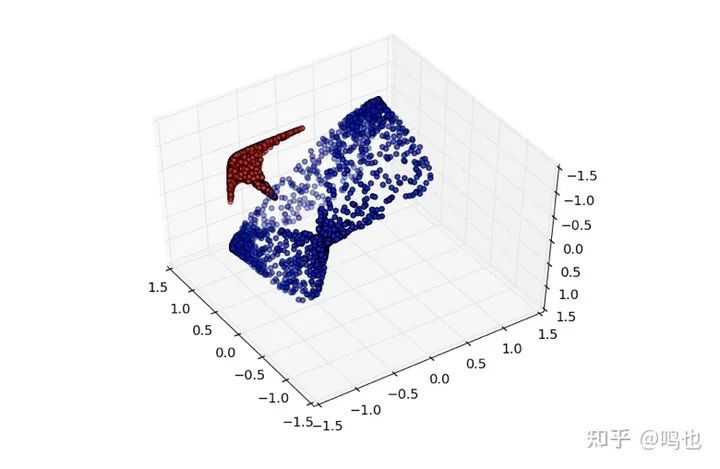
通过这种表示,我们可以用一个超平面来分隔数据集。
为了更好地了解发生了什么,让我们考虑一个更简单的一维数据集:
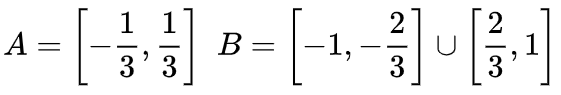
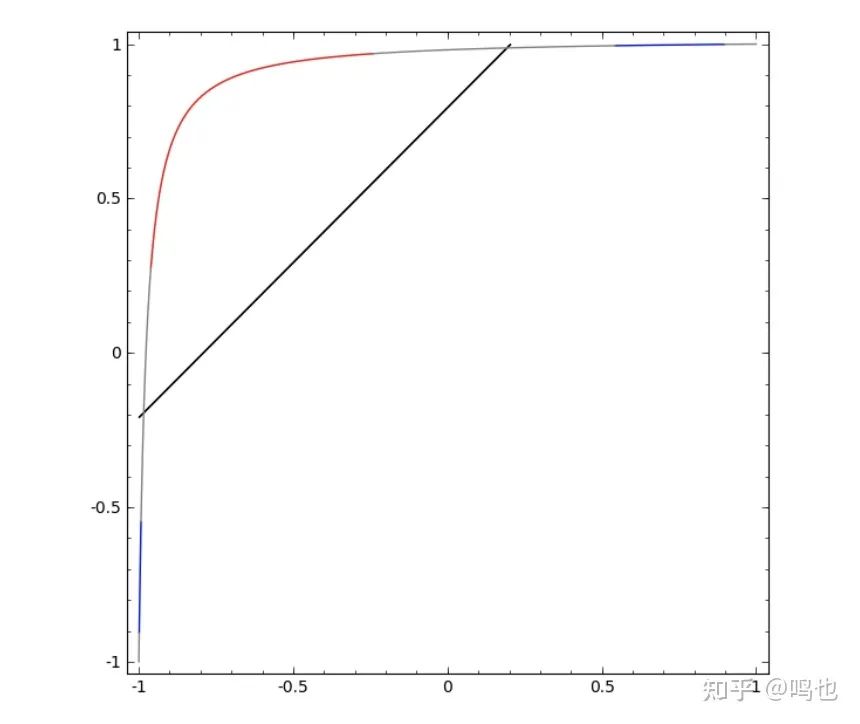
如果不使用由两个或更多隐藏单元组成的层,我们就无法对该数据集进行分类。但是如果我们用一个单位和两个单位,我们就学会了用一条漂亮的曲线来表示数据,这样我们就可以用一条线来分隔类:
流形假说
这是否与真实世界的数据集相关,比如图像数据?如果你真的认真对待流形假设,我认为这是值得考虑的。
流形假设是自然数据在其嵌入空间中形成低维流形。有理论和实验作为理由相信这是真的。如果你相信这一点,那么分类算法的任务就是从根本上分离一组纠缠在一起的流形。
在前面的示例中,一个类完全包围了另一个类。然而,狗的图像流形似乎并不很可能被猫图像流形完全包围。但是还有其他更合理的拓扑情况,仍然可能会引发问题,我们将在下一节中看到。
连接和同伦
一个有趣的数据集是两个链接的圆环面(tori),A 和 B。

这与我们之前考虑的数据集非常相似,如果不使用n+1维度,这个数据集就不能被分离,这里即为第4维度。
连接是在结理论中被研究的,这是拓扑学的一个领域。有时,当我们看到一个连接时,它是否是一个断开的链接(一堆东西纠缠在一起,但可以通过连续变形来分开)并不是很明显。

如果一个只有3个单位的层的神经网络可以对它进行分类,那么它就是一个断开的连接。(问题:从理论上讲,一个只有3个单元的网络是否可以对所有未链接进行分类?)
从结的角度来看,我们对神经网络产生的表示的连续可视化不仅仅是一个很好的动画,它是一个解开链接的过程。在拓扑学中,我们称之为原始连接和分离之间的ambient isotopy。
一个简单的方法
对于神经网络来说,最简单的方法就是尝试将流形拉开,并尽可能地拉伸那些缠结在一起的部分。虽然这不会接近真正的解决方案,但它可以实现相对较高的分类精度,并且是一个较为诱人的局部最小值。
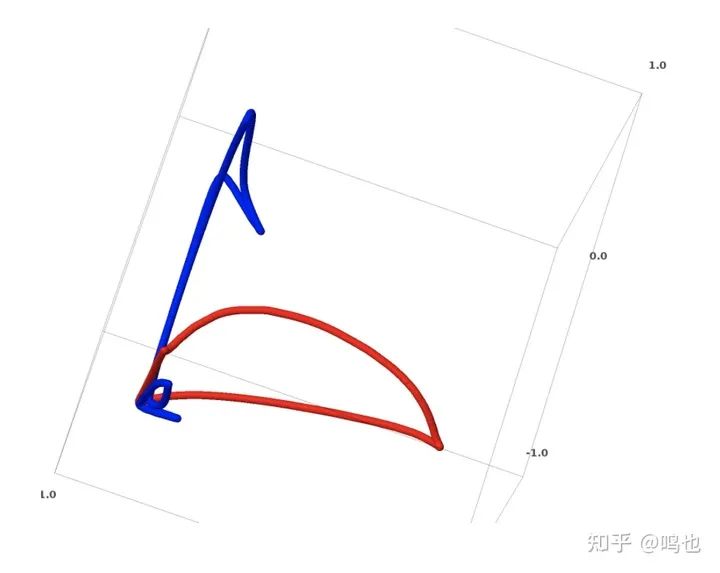
它会在它试图拉伸的区域上呈现出非常高的导数,并且在不连续点附近较尖锐。我们知道这些事情发生了。收缩惩罚,惩罚数据点的层的导数,是应对这一点的自然方法。
由于这些局部极小值从解决拓扑问题的角度来说是完全无用的,拓扑问题可能为探索解决这些问题提供了一个很好的动力。
另一方面,如果我们只关心取得好的分类结果,我们似乎不在乎。如果一小部分数据流形被另一个流形所缠绕,那对我们来说是个问题吗?尽管存在这个问题,我们似乎应该能够得到任意好的分类结果。
(我的直觉是,像这样试图欺骗问题是个坏主意:很难想象这不会是一个死胡同。特别是,在局部极小值是一个大问题的优化问题中,选择一个不能真正解决问题的体系结构似乎会导致糟糕的性能。)
操纵流形的更好层次?
我越是想到标准的神经网络层——也就是说,用仿射变换和逐点激活函数——我就越感到不抱幻想。很难想象它们真的非常适合操纵流形。
也许有一种完全不同的层次,我们可以在构图中使用更传统的层次是有意义的?
我觉得很自然的一件事是学习一个向量场,它的方向是我们想要移动流形的方向:
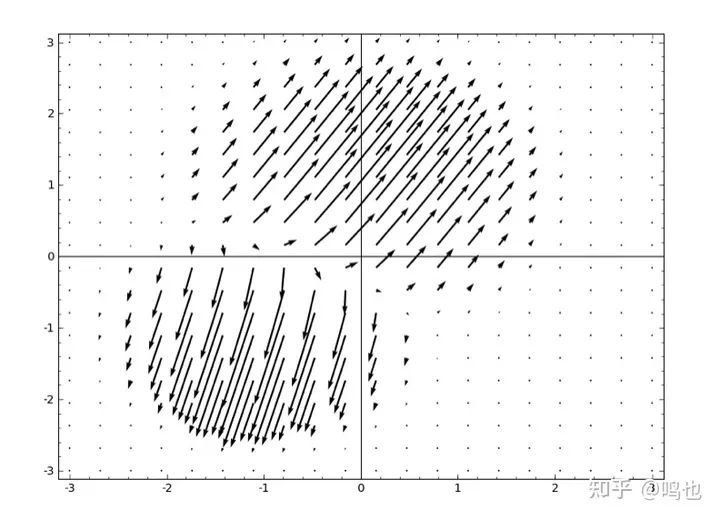
然后在此基础上变形空间:
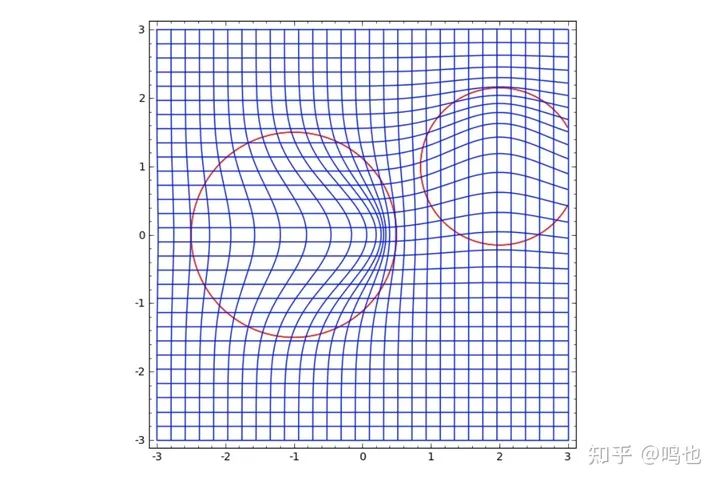
我们可以在固定点学习向量场(只需从训练集中选取一些固定点作为锚),并以某种方式进行插值。上面的向量场的形式如下:
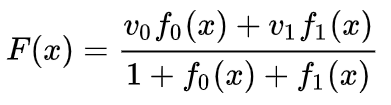
其中和是向量和和是n维高斯函数。这是受到径向基函数的启发。
K-近邻层
我也开始认为,线性可分性可能对神经网络是一个巨大的,可能是很不合理的的要求。在某些方面,使用k近邻(k-NN)是一件很自然的事情。然而,k-NN它的成功在很大程度上依赖于它对数据进行分类的表示,因此在k-NN能够正常工作之前需要一个良好的表示。
作为第一个实验,我训练了一些MNIST网络(两层CNN,无dropout),达到∼1%,测试错误。然后,我放弃了最后的softmax层,并使用了k-NN算法。我能够实现测试误差降低0.1-0.2%。
不过,这感觉不太合适。网络仍然在尝试进行线性分类,但是由于我们在测试时使用k-NN,它能够从它犯的错误中恢复一点。
由于(1/distance)的加权,k-NN相对于它所作用的表示是可微的。因此,我们可以直接训练网络进行k-NN分类。这可以看作是一种“最近邻”层,作为softmax的替代品。
我们不想为每个小批量反馈整个训练集,因为这在计算上非常昂贵。我认为一个很好的方法是根据小批量中其他元素的类别对小批量中的每个元素进行分类,给每个元素赋予(1/(与分类目标的距离))的权重,遗憾的是,即使使用复杂的体系结构,使用k-NN也只能得到5-4%的测试错误,而使用更简单的体系结构会得到更糟糕的结果。不过,我在使用超参数方面投入的精力很少。
不过,我还是很喜欢这种方法,因为我们“要求”网络做的似乎更合理。我们希望同一流形的点比其他流形的点更接近,而不是流形被超平面分开。这应该对应于膨胀不同类别的流形之间的空间和收缩单个流形。这感觉很简单。
总结
数据的拓扑特性可能使得使用低维网络来线性划分类是不可能的(在不考虑深度的前提下)。即使在技术上可行的情况下,例如螺旋,这样做也是非常具有挑战性的。
为了用神经网络对数据进行精确分类,有时需要宽层。此外,传统的神经网络层似乎不太擅长表示流形的重要操作;即使我们用手巧妙地设置权重,也很难紧凑地表示我们想要的变换。新设计的层,特别是由机器学习的多方面观点推动的,可能是有用的。
原文链接:http://colah.github.io/posts/2014-03-NN-Manifolds-Topology/
推荐阅读
分享
收藏
点赞
在看