
三维重建、特征匹配、视觉定位,一文详解滴滴AR实景导航技术
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达
导读:机场、商场、火车站等大型室内场所内GPS信号不稳定、室内面积大、路线复杂、用户判断方向难等问题,给在大型场所内发单的乘客找上车点带来了很大的挑战,用户急需一种操作简单、交互友好的引导功能。本文讲述了使用三维重建技术、传感器计算技术和增强现实(AR)技术所开发的滴滴AR实景导航产品,并对开发过程中遇到的难点、挑战和解决思路展开介绍。
相信很多人都有过这样的经历:来到一个自己不熟悉的场景,特别是在一些GPS信号不准确的室内场所,很难找到建筑物内部的一些特定地点。本文将以帮助用户在大型机场等场所中快速找到上车点为出发点,介绍滴滴AR实景导航产品研发过程中的挑战和关键技术。
1.

我们在用户调研中发现,在一些大型的机场、商场、火车站内部,滴滴乘客在下单成功之后,往往需要更多的时间才能找到上车点,其主要原因是在这些大型的室内场所中,GPS信号不准确,而这些建筑往往面积很大、内部路线复杂,当乘客对场景不熟悉时,找到上车点存在很大的困难。为了解决这个问题,地图团队提出了“图文引导”的方式来帮助用户,通过特定场景的图片和文字的方式相结合来引导用户找到上车点。与此同时,我们也在持续探索是否有更加直观、易理解的方式来帮助用户,受到增强现实(AR)技术在游戏中应用的启发,我们提出了使用AR的方式来帮助用户找到上车点,最终开发出了滴滴AR实景导航产品。
当乘客在支持AR导航的场站,使用滴滴出行App选择推荐上车点发单成功后,可以通过产品界面中的AR按钮进入导航界面,并按指引操作,体验在AR元素指引下到达上车点。如下图所示。
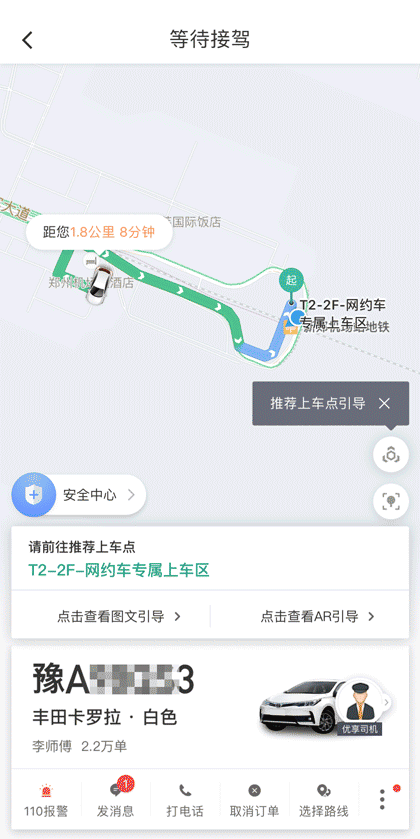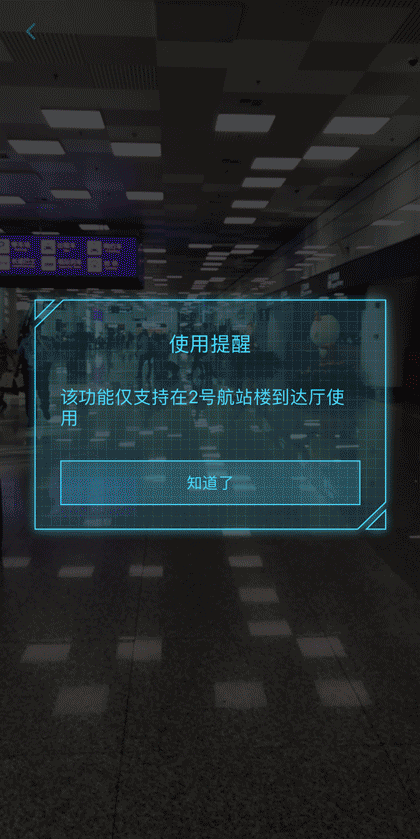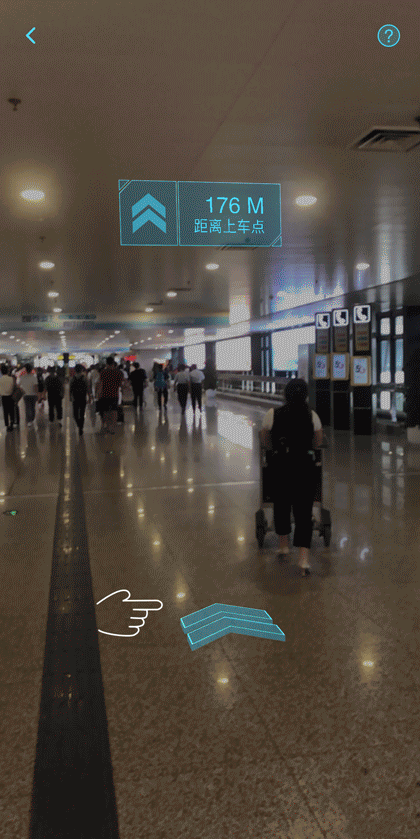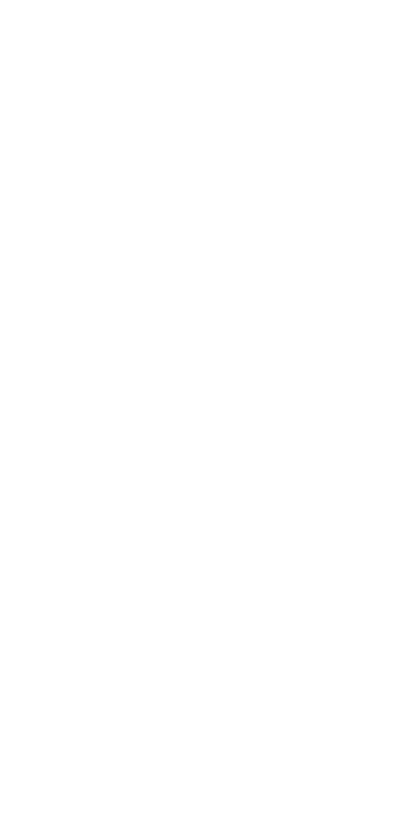
郑州机场
想要给用户提供一个良好的导航产品,需要解决几个关键问题:第一,场景所在的地图是怎么样的;第二,如何确定用户的位置;第三,如何使用更加直观的方式引导用户走到目的地。这些问题,在通常的室外场景来看,可能都不是"问题",因为可以直接使用现有的地图、GPS定位、规划路线和GPS实时位置引导到达目的地。但是这些能力在室内场景下,却变得很难。具体原因包括:在室内场景中,GPS信号受到建筑物遮挡往往定位不准确,而现有的Wi-Fi、基站等定位技术也因场景中基础设施情况的不同而表现出精度差异很大;同时,与室外相比,室内场景结构复杂度高、判断方向难,给用户引导也带来很大的挑战。
为了解决上述问题,给用户提供更加友好的室内导航服务,我们推出了滴滴AR实景导航产品,其主要方案是采用低成本的视觉定位技术来提升用户的定位精度,并结合增强现实技术来将引导信息显示到用户手机上,给用户提供所见即所得的交互体验。
3.
要想实现一个理想的AR导航系统,我们调研了很多技术方案,最终选择了基于视觉的三维重建技术来解决地图构建和路径计算的问题、视觉定位技术来提供更高精度的定位能力以及传感器位置推算与渲染技术来实现更加精确的AR交互显示。虽然上述技术在学术研究领域已经有了很多年的研究,并产出了一些相对成熟的方案,但是在实施过程中,也遇到了很多挑战:
1、在三维重建方面
基于视觉的三维重建技术依赖相机拍摄到的场景图像进行三维结构恢复,一般应用于办公室、公寓等几百平米的场景内。在机场、火车站、商场等超过几万平米的大型场景下,会存在人群密集、重复纹理多、光照变化大、场景空旷、狭长通道等不利于视觉重建的因素,这种超大现实室内场景三维重建是业界难题。
2、在视觉定位方面
室内环境复杂多样,室内空间布局、拓扑易受人为的影响,导致声、光、电等环境容易发生变化,对于以特征匹配为基本原理的定位方法,定位结果将受到较大影响。机场、火车站、商场内大量重复出现的指示牌、广告牌都极易产生误匹配,影响定位的精度。
3、在传感器位置推算方面
由于传感器噪声的存在,使得基于惯性传感器的位置推算存在累积误差。当长时间使用时,导致导航路线偏离正确路径,严重影响着用户体验。此外,用户行走行为和手机硬件的多样性,使得单一模型的惯性传感器位置推算很难解决所有场景遇到的问题。因此,亟需提出一种模型自适应机制来提升导航系统的准确度和鲁棒性。
4.
为了解决上述问题,结合具体的应用场景以及技术积累,我们分别针对每个关键模块进行了系列优化,现简要分享一下。
▍基于视觉的三维重建技术
三维重建解决的是室内地图构建的问题。三维重建一般需要借助运动恢复结构(Structure from Motion,SfM),其学术定义是「在未知的环境中,让一个机器人能进行环境的构建,并且估计自身的运动」。用通俗的语言讲,是利用相机拍摄到的图像或视频,恢复整个场景的三维结构。系统的输入是多张图像或视频流,输出是场景的三维结构和每张图像拍摄的位姿。相机位姿是6自由度,3个自由度表示位置,3个自由度表示姿态(相机朝向)。位置可以理解成三维空间当中的一个点,姿态就是这个相机的朝向,如果在二维上就是360度的朝向,扩展到三维就是一个球体的朝向。
首先我们了解下SfM的技术框架,一共四个主要步骤:①数据采集;②特征提取;③数据关联;④结构恢复。在恢复场景的三维结构时,并不是使用图像中的所有像素点,而仅从图像中提取稳定、显著的点,也就是特征点;数据关联是确定有共视区域的两张图像中哪些特征点是对应的;后续会借助几何的方法以及最优化技术(Bundle Adjustment)将这些图像中的点恢复为空间的三维点。整个问题最终被转化为大型非线性最优化问题求解,优化目标是重建的三维点重投影到图像中的位置与图像中的观测点位置差最小,也就是最小化重投影误差。
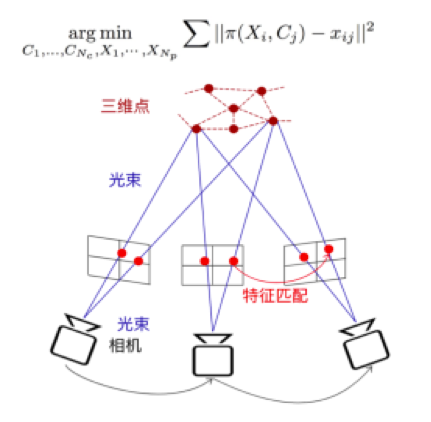
针对大型场站室内场景存在的人群密集、重复纹理多、场景有变化等挑战。我们设计了一种基于视觉的大型室内场景三维重建方案:针对大型机场、火车站存在的规模大、场景复杂(重复纹理、相似纹理、狭长通道、动态物体等),提出了一种基于视频的分块三维重建方案,首先构建图像间的关联图,问题可以建模成Graph Cut问题,可以自动进行数据分块;之后利用Pose Graph Optimization实现了块间合并与优化,并通过引入关键帧、点云选择等策略,实现了自动化建图,效率提升70%,构建的超过6万平米的室内场站三维模型是业界已知的最大单体模型之一,下图是郑州机场的三维模型可视化效果。
郑州机场三维模型
▍视觉定位技术
在AR导航的使用场景中,定位的目的就是确定用户的位置。手机的定位源主要包含3大类:①导航卫星接收机:包括中国的北斗,美国的GPS,欧洲的Galileo、俄罗斯的GLONASS等;②内置传感器:包括加速度计、陀螺仪、磁力计、气压计、光线传感器、相机等;③射频信号:包括Wi-Fi、蓝牙、蜂窝无线通信信号等。除了卫星导航接收机外,这些传感器和射频信号都不是为定位而设置的,尽管如此,这些传感器还是为我们提供了很多的室内定位源。主流的全球卫星导航系统(Global Navigation Satellite System,GNSS)目前虽然已经被大规模商业应用,在室外开阔环境下定位精度已能解决大部分定位需求,但该类信号无法覆盖室内,难以形成定位。室内环境复杂,无线电波通常会受到障碍物的遮挡,发生反射、折射或散射,改变传播路径到达接收机,形成非视距(non line-of-sight,NLOS)传播。NLOS传播会使定位结果产生较大的偏差,严重影响定位精度。
经过充分的调研与对比,考虑到Wi-Fi指纹匹配方式定位精度2~5米,而蓝牙iBeacon作用距离短且布设成本较高等问题,最终我们采用了视觉定位的方式。该方法基于相机交互的方法,定位精度可达亚米级,鲁棒性较好,且只需利用手机摄像头、成本较低,无需布设额外设备,而且随着近年视觉定位技术的不断优化迭代,其精度与鲁棒性已完全能满足室内定位的需求。
(1)基于传感器融合的图像检索重排序技术
通常情况下,用户手机获取一张查询图后,首先对图像进行特征提取,然后采用特征描述子对特征点进行描述,根据图中提取的大量2D特征点,会在当前场景三维模型中检索相似的top N张图像,根据最相似的图像进一步寻找2D点与模型中3D点的匹配,最后利用RANSAC+PnP求解,计算查询图的位置与姿态[R|t]。
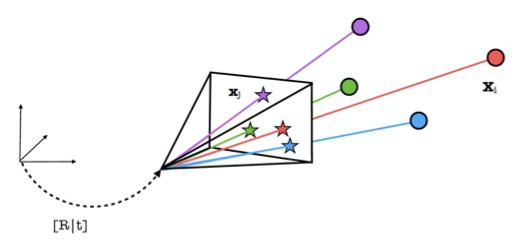
但是由于室内场景存在大量人造物体,例如机场、火车站中大量出现的指示牌,商场中大量出现的广告牌,都很容易因为局部特征相似,导致错误的匹配。考虑到手机本身集成了磁力计和GNSS传感器,虽然这些低成本的传感器精度有限,但作为定位初值还是可以加以利用,我们根据磁力计获取的大致方位,以及GNSS获取的大致位置作为先验知识,根据传感器的精度指标,对候选图像进行聚类,并将参数加权带入图像重排序(rerank)的计算公式,可以剔除具有明显方向差异或者位置差异显著的候选图像。在降低误匹配概率的同时,也显著提高了计算的效率,保证了定位结果的精度。
(2)基于上下文信息的位姿校正技术
由于室内人造结构的特殊性,很多场景都是对称修建或者呈规则排列的几何布局,导致在视觉定位的时候,不仅是局部特征几乎一致,甚至大范围场景内的全局特征也是非常相似的,这就导致初始定位存在一定概率的误匹配情况。当用户刚好位于此类区域的时候,很有可能会得到错误的引导信息。不过在实际情况中,这些容易混淆的区域不会完全一模一样,当用户移动一小段距离或者视角发生变化的时候,往往会出现具有显著区分度的地物特征,依赖这些信息可以对用户当前的位姿进行校正,重新生成一条正确的引导路线。但是同样是特征匹配,当前后两帧信息都满足定位条件,但定位结果存在较大差异的时候,如何分辨究竟哪个是正确的结果呢。这时就需要利用到上下文的信息,即我们在定位的时候并不完全依赖于一次的定位结果,而是一片区域或者一段轨迹中的多个定位结果,当这些结果呈现出较好的一致性的时候,通常有更大的概率是正确的定位,相反,那些局部特征相似的区域,由于匹配到了错误的参考图像,其结果往往呈现出孤立的跳变,与前后帧并不能平滑过渡,行走轨迹也是不光滑的。利用这种定位结果的上下文信息,可以有效检测出错误的定位结果,对其进行过滤,或者及时发现当前已经处于错误的引导路线上,根据正确的结果进行校正。

▍传感器位置推算技术
在完成视觉定位后,需要根据手机的位置进行实时的路线指引和渲染,这里我们使用了基于传感器的位置推算技术,通过读取手机上的传感器信息并结合人体运动模型等方法,推算出对应的位置。
惯性传感器包括加速度计和陀螺仪,通常还会与磁力计组合使用。每个传感器均具有三个自由度。加速度计测量施加给移动设备的加速度读数,陀螺仪测量移动设备的旋转运动,磁力计通过感知磁场的变化,推理出用户当前的朝向。这些传感器可以在没有外部数据的情况下确定移动设备的位置,而不需要基础设施的辅助。基于惯性传感器的位置推算由于以下优点逐渐成为研究的热点:①低能耗全天24小时运行;②不受外界环境干扰;③内置于每一部移动智能终端。
现有的基于积分的惯性导航算法主要利用线性加速度计读数(加速度计读数减去重力数据)进行二次积分得到位移和陀螺仪读数积分得到姿态,继而解算当前位置。然而,惯性传感器具有噪声,导致惯性积分算法估计的位置很快飘移。因此,当前惯性积分算法主要应用于高精度惯性器件中,例如航天级别的惯性传感器。为了解决在低端手机中惯性传感器的迅速飘移问题,研究者们提出了PDR (Pedestrian Dead Reckoning) 算法。
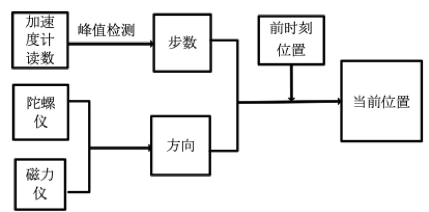
PDR (Pedestrian Dead Reckoning) 算法是一种基于相对位置的位置推算方法,主要思想是给定初始位置和朝向,根据行走的位移推算出下一步的位置。主要包括计步、步长估计和朝向估计模块,如下图所示。计步主要是通过检测加速度计读数的峰值点实现步子识别;步长估计利用一步之内的加速度计读数,根据人的身高、体重、步频等特征拟合当前一步的步长;朝向估计利用加速度计和陀螺仪读数,通过滤波或者优化技术实现设备的姿态估计,继而获取当前一步的行走朝向。由于上述每一个模块都会有误差,且对不同的人群和设备的多样性比较敏感,随着时间的推移,误差累积增大,直至导航系统不可用,为AR引导带来了技术挑战。
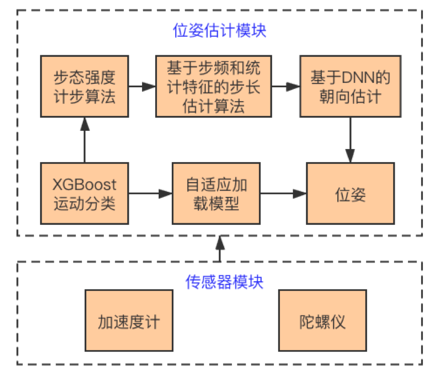
为了解决上述技术挑战,我们提出了鲁棒的位置推算算法,该方法发表在机器人领域顶级会议International Conference on Intelligent Robots and Systems (IROS) 2020上。
所提出的方法主要包括基于步态强度的计步算法,基于步频和统计特征的步长估计算法,基于深度模型的朝向回归算法和基于机器学习的运动分类算法。下面介绍一下相关算法。
(1)基于步态强度的计步算法
给定三轴加速度计读数,首先对每一帧加速度计读数求取幅值。利用当前帧加速度计的幅值和其邻近数据,检测加速度计读数波形的峰值,每一个峰值对应着候选步子,如下公式所述:
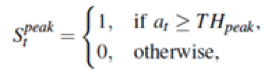
其中,S表示当前加速度计读数的状态,即是否为候选步子,如果为1,则表示当前时刻检测到候选步子。
其次,根据长短窗内的加速度计读数的均值来判断当前时刻是否为候选步子,其下公式所述:
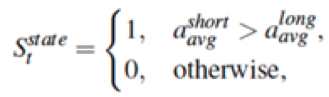
其中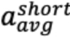 表示短窗口内的加速度计读数的均值,
表示短窗口内的加速度计读数的均值, 表示长窗口内的加速度计读数的均值。
表示长窗口内的加速度计读数的均值。
再次,根据加速度计数据计算步态强度,它描述了一步之内加速度的变化情况。当步态强度超过一定阙值后,我们认为当前时刻是候选步子:
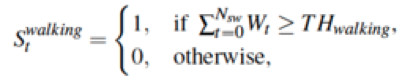
其中,
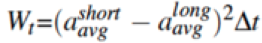
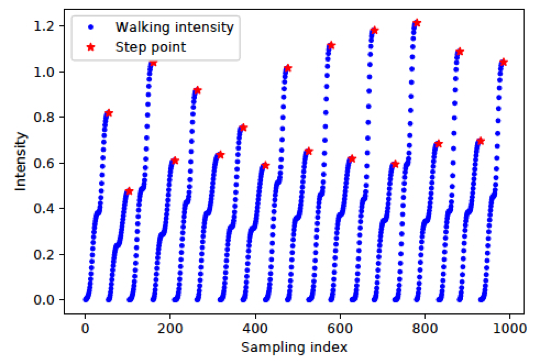
下图展示了真实行走状态下步态强度的变化情况,其中蓝色点表示步态强度,红色点表示步点。
最后,当上述状态均取得1时,认为当前时刻为检测到一步,计算公式如下:

计步算法示意图如下图所示,其中蓝色曲线表示加速度计读数,红色三角形表示识别到一步。

(2) 步长估计算法
我们提出了一种基于统计特征的步长估计算法,其中统计特征包括步频、一步内的加速度计读数的方差、极差的n次开方,计算公式如下所述:
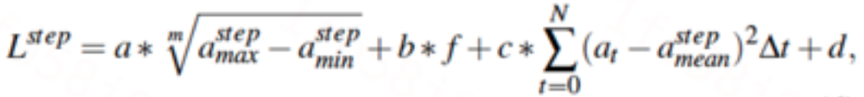
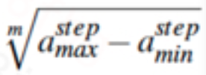 表示加速度计读数极差的m次开方,
表示加速度计读数极差的m次开方,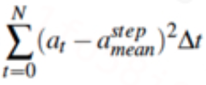 表示加速度计读数的方差。
表示加速度计读数的方差。现有的朝向估计算法利用互补滤波和卡尔曼滤波实现设备朝向的估计,而设备朝向和人员行走朝向之间存在变化的偏差角会导致PDR的位姿估计累积飘移。为了解决该问题,我们利用深度学习算法来回归用户行走的朝向。具体而言,我们提出了一种heading-confidence模型,采用LSTM和ResNet作为深度网络框架。LSTM主要负责行走朝向的回归,ResNet主要负责行走速度的回归,最后,我们设计了置信度函数来进行朝向的融合。
(4) 运动分类
为了提升PDR系统对运动类别的鲁棒性,我们设计了一种基于梯度提升决策树算法的运动分类模型。主要包括行走、随意行走、静止和手持设备摇摆四种姿态。通过识别不同的行走姿态,我们自适应的加载对应的模型参数,继而提高了PDR算法的精度。实验结果如下图所示。其中,黑色曲线表示参考真值,蓝色曲线表示没有运动分类的PDR算法轨迹,红色曲线表示引入了运动分类的PDR轨迹。可以看到,红色轨迹更加接近于参考真值。

5.
大型机场、商场、火车站内部的上车点引导能力对用户体验影响很大,为了解决这个问题,地图团队做出了很多努力,推出了“图文引导”方案来使用图像和文字的方式帮助用户。同时,为了给用户提供更好的体验,我们也推出了滴滴AR实景导航产品,使用人工智能算法等科技手段,为用户提供准确的、易用的导航产品,来帮助用户更快的找到上车点。目前在郑州、深圳以及日本东京等24个机场、商场或者火车站上线了AR导航服务,数据显示,它能帮助用户节省近四分之一的时间,让他们更便捷地到达上车点。与此同时,在南京火车站等大型场站,我们正在进一步探索基于AR导航的技术来帮助乘客快速抵达公交站点。后续我们将持续优化和打磨我们的算法,为乘客和司机创造更多的价值。欢迎大家体验我们的产品,并对我们提出宝贵的意见,希望通过我们的努力可以为大家提供更好的出行体验。


▲长按关注我们
整理不易,请给CVer点赞和在看!![]()