
最全总结 | 聊聊 Python 数据处理全家桶(Mysql 篇)
点击上方“AirPython”,选择“加为星标”
第一时间关注 Python 技术干货!

1. 前言
在爬虫、自动化、数据分析、软件测试、Web 等日常操作中,除 JSON、YAML、XML 外,还有一些数据经常会用到,比如:Mysql、Sqlite、Redis、MongoDB、Memchache 等
一般情况下,我们都会使用特定的客户端或命令行工具去操作;但是如果涉及到工程项目,将这部分数据操作集成到代码中使用才是王道
接下来,我将分几篇文章,和大家一起聊聊 Python 操作这些数据的 最优 方案
本篇从使用最为广泛的关系型数据库 - Mysql 开始讲起
2. 准备
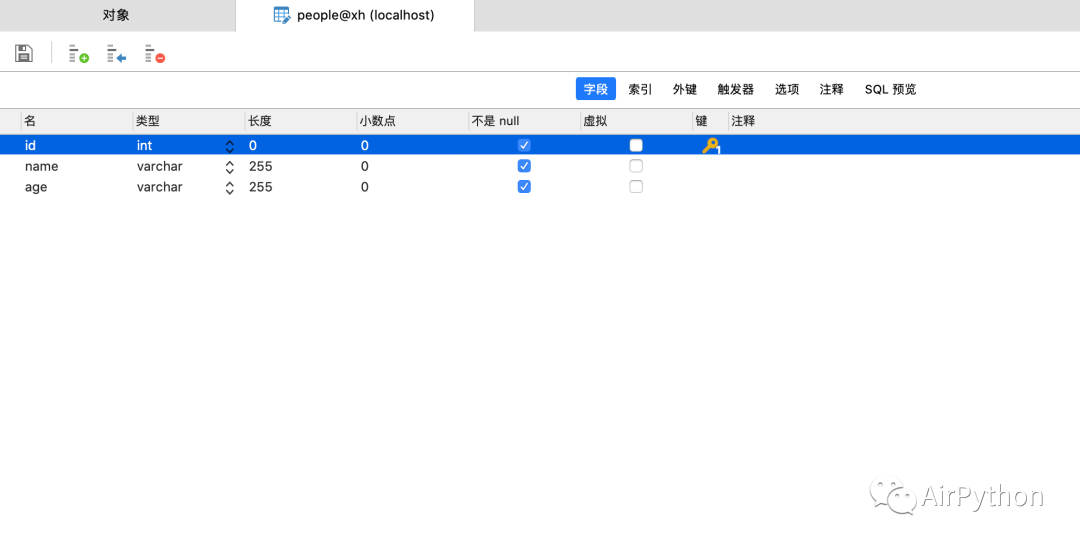
首先,我们通过 Mysql 客户端或命令行创建一个数据库 xh
然后,在这个数据库下建一张简单的表 people
为了便于演示,这里只创建了三个字段:id、name、age,其中 id 为主键
Python 操作 Mysql 主要包含下面 3 种方式:
Python-MySql
PyMysql
SQLAlchemy
其中,
Python-MySql 由 C 语法打造,接口精炼,性能最棒;但是由于环境依赖多,安装复杂,已停止更新,仅支持 Python2
PyMysql 为替代 Python-Mysql 而生,纯 Python 语言编写的 Mysql 操作客户端,安装方便,支持 Python3
SQLAlchemy 是一个非常强大的 ORM 框架,不提供底层的数据库操作,主要是通过定义模型对应数据表结构,在 Python Web 编程领域应用广泛
由于 Python-MySql 不支持 Python3,所以本文只谈后 2 种操作方式
3. PyMysql
首先,使用 pip 安装依赖
# 安装依赖
pip3 install pymysql
连接数据库,获取数据库连接对象及游标对象
使用 pymysql 中的 connect() 方法,传入数据库的 HOST 地址、端口号、用户名、密码、待操作数据库的名称,即可以获取 数据库的连接对象
然后,再通过数据库连接对象,获取执行数据库具体操作的 游标对象
import pymysql
# 数据库连接
self.db = pymysql.connect(host='localhost',
port=3306,
user='root',
password='**',
database='xh')
# 获取游标
self.cursor = self.db.cursor()
接着,我们来实现增删改查操作
1、新增
新增包含新增单条数据和多条数据
对于单条数据的插入,只需要编写一条插入的 SQL 语句,然后作为参数执行上面游标对象的 execute(sql) 方法,最后使用数据库连接对象的 commit() 方法将数据提交到数据库中
# 插入一条数据
SQL_INSERT_A_ITEM = "INSERT INTO PEOPLE(name,age) VALUES('xag',23);"
def insert_a_item(self):
"""
插入一条数据
:return:
"""
try:
self.cursor.execute(SQL_INSERT_A_ITEM)
self.db.commit()
except Exception as e:
print('插入数据失败')
print(e)
self.db.rollback()
使用执行游标对象的 executemany() 方法,传入插入的 SQL 语句及 位置变量列表,可以实现一次插入多条数据
# 插入多条数据SQL,name和age是变量,对应列表
SQL_INSERT_MANY_ITEMS = "INSERT INTO PEOPLE (name, age) VALUES(%s, %s)"
# 待插入的数据
self.datas = [("张三", 23), ("李四", 24), ("王五", 25)]
def insert_items(self):
"""
插入多条记录
:return:
"""
try:
self.cursor.executemany(SQL_INSERT_MANY_ITEMS, self.datas)
self.db.commit()
except Exception as e:
print("插入数据异常")
self.db.rollback()
需要注意的是,PyMysql 会将 SQL 语句中的所有字段当做字符串进行处理,所以这里的 age 字段在 SQL 中被当做字符串处理
2、查询
查询分为三步,分别是:
通过游标对象执行具体的 SQL 语句
通过游标对象,获取到元组数据
遍历元组数据,查看结果
比如:查看数据表中所有的记录
# 查询所有记录
SQL_QUERY_ALL = "SELECT * FROM PEOPLE;"
def query(self):
"""查询数据"""
# 查询所有数据
self.cursor.execute(SQL_QUERY_ALL)
# 元组数据
rows = self.cursor.fetchall()
# 打印结果
for row in rows:
id = row[0]
name = row[1]
age = row[2]
print('id:', id, ',name:', name, 'age:', age)
如果需要按条件查询某一条记录,只需要修改 SQL 语句即可实现
# 按id查询
SQL_QUERY_WITH_CONDITION = "SELECT * FROM PEOPLE WHERE id={};"
# 查询id为5的记录
self.cursor.execute(SQL_QUERY_WITH_CONDITION.format(5))
3、更新
和 新增操作 类似,更新操作也是通过游标对象去执行更新的 SQL 语句,最后利用数据库连接对象将数据真实更新到数据库中
# 更新(通过id去更新)
SQL_UPDATE = "UPDATE PEOPLE SET name='%s',age=%s WHERE id=%s"
def update(self):
"""
更新数据
:return:
"""
sql_update = SQL_UPDATE % ("王五五", 30, 5)
print(sql_update)
try:
self.cursor.execute(sql_update)
self.db.commit()
except Exception as e:
self.db.rollback()
print('更新数据异常')
print(e)
4、删除
删除操作同查询、新增操作类似,只需要变更 SQL 语句即可
# 删除(通过id去删除数据)
SQL_DELETE = "DELETE FROM PEOPLE WHERE id=%d"
def delete(self):
"""
删除记录
:return:
"""
try:
# 删除的完整sql
sql_del = SQL_DELETE % (5)
self.cursor.execute(sql_del)
self.db.commit()
except Exception as e:
# 发生错误时回滚
self.db.rollback()
print(e)
最后,我们需要将游标对象和数据库连接对象资源释放掉
def teardown(self):
# 释放资源
self.cursor.close()
self.db.close()
4. SQLAlchemy
首先,使用 SQLAlchemy 操作 Mysql 数据库同样先需要安装依赖库
# 安装依赖包
pip3 install sqlalchemy
通过 SQLAlchemy 的内置方法 declarative_base() 创建一个基础类 Base
然后,自定义一个 Base 类的子类,内部定义静态变量,和上面数据表 people 中的字段一一对应
from sqlalchemy import Column, Integer, String, create_engine
from sqlalchemy.ext.declarative import declarative_base
# 基础类
Base = declarative_base()
# 自定义的表
class People(Base):
# 表名
__tablename__ = 'people'
# 定义字段
id = Column(Integer, primary_key=True)
name = Column(String(255))
age = Column(Integer)
def __repr__(self):
"""
便于打印结果
:return:
"""
return ".format(self.id, self.name, self.age)
接着,通过数据库名、用户名、密码及 Host 组装一个数据库连接地址,作为参数传入到 SQLAlchemy 的 create_engine() 方法中,以创建一个数据库引擎实例对象
# 创建数据库的引擎实例对象
# 数据库名称:xh
engine = create_engine("mysql+pymysql://root:数据库密码@localhost:3306/xh",
encoding="utf-8",
echo=True)最后,通过数据库引擎在数据库中创建表结构,并实例化一个 会话对象
需要注意的是,create_all() 方法中的 checkfirst 参数如果传入 True,则会判断数据表是否存在,如果表存在,则不会重新创建
# 创建表结构
# checkfirst:判断表是否存在,如果存在,就不重复创建
Base.metadata.create_all(engine, checkfirst=True)
# 实例化会话
self.session = sessionmaker(bind=engine)()
这样所有的准备工作已经完成,接下来可以进行增删改查操作了
1、新增
新增操作同样包含插入一条记录和多条记录,分别对应会话对象的 add()、add_all() 方法
对于一条记录的新增操作,只需要实例化一个 People 对象,执行上面的会话对象的 add(instance) 和 commit() 两个方法,即可以将数据插入到数据表中
def add_item(self):
"""
新增
:return:
"""
# 实例化一个对象
people = People(name='xag', age=23)
self.session.add(people)
# 提交数据才会生效
self.session.comit()
如果需要一次插入多条数据,只需要调用 add_all(列表数据) 即可
def add_items(self):
"""
新增多条记录
:return:
"""
datas = [
People(name='张三', age=20),
People(name='李四', age=21),
People(name='王五', age=22),
]
self.session.add_all(datas)
self.session.commit()
2、查询
查询数据表的操作对应会话对象的 query(可变参数)
方法中的参数指定要查询的字段值,还可以通过 all()、first() 级联方法限制要查询的数据
def query(self):
"""
查询
:return:
"""
# 查询所有记录
# result = self.session.query(People).all()
# 查询name/age两个字段
result = self.session.query(People.name, People.age).all()
print(result)
当然,也可以利用 filter_by(条件),按条件进行过滤
# 条件查询
resp = self.session.query(People).filter_by(name='xag').first()
print(resp)
3、更新
更新操作一般做法是:
query 查询出待更新的对象
直接更新对象中的数据
使用会话对象提交修改,完成更新操作
def update1(self, id):
"""
更新数据1
:return:
"""
# 获取数据
temp_people = self.session.query(People).filter_by(id=id).first()
# 更新数据
temp_people.name = "星安果"
temp_people.age = 18
# 提交修改
self.session.commit()
需要指出的是,这里可以使用 update() 方法进行简写
def update2(self, id):
"""
更新数据2
:param id:
:return:
"""
# 使用update()方法直接更新字段值
self.session.query(People).filter(People.id == id).update({People.name: "xag", People.age: 1})
self.session.commit()
4、删除
删除操作对应 delete() 方法,同样是先查询,后删除,最后提交会话完成删除操作
以按照 id 删除某一条记录为例:
def del_by_id(self, id):
"""
通过id删除一条记录
:param id:
:return:
"""
del_count = self.session.query(People).filter(People.id == id).delete()
print('删除数目:', del_count)
self.session.commit()5.最后
本篇文章通过一张表的增删改查,详细讲解了 Python 操作 Mysql 的两种使用方式
在实际项目中,如果仅仅是简单的爬虫或者自动化,建议使用 PyMysql;否则建议直接上 SQLAlchemy,它更强大方便
我已经将文中全部源码上传到后台,关注公众号后回复「 dball 」即可获得全部源码
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!