
我不做韭菜!用 python 分析基金中的股票信息

文 | 某某白米饭
来源:Python 技术「ID: pythonall」

大家都多多少少会买点基金或者去开个户买点股票。大家都是普通人也没有什么后台内幕消息,经常被割韭菜。不想被割就得去分析各种资料文档。本文就是在天天基金网上抓取基金购买的股票信息。
股票有风险,入市需谨慎。基金有风险,入市需谨慎。
模块
话不多说先上需要调用到的模块。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from lxml import etree
import requests
import re
import threading
import os
首页抓取
在天天基金中找到开放式基金,如下图,一共有 9340 支基金。
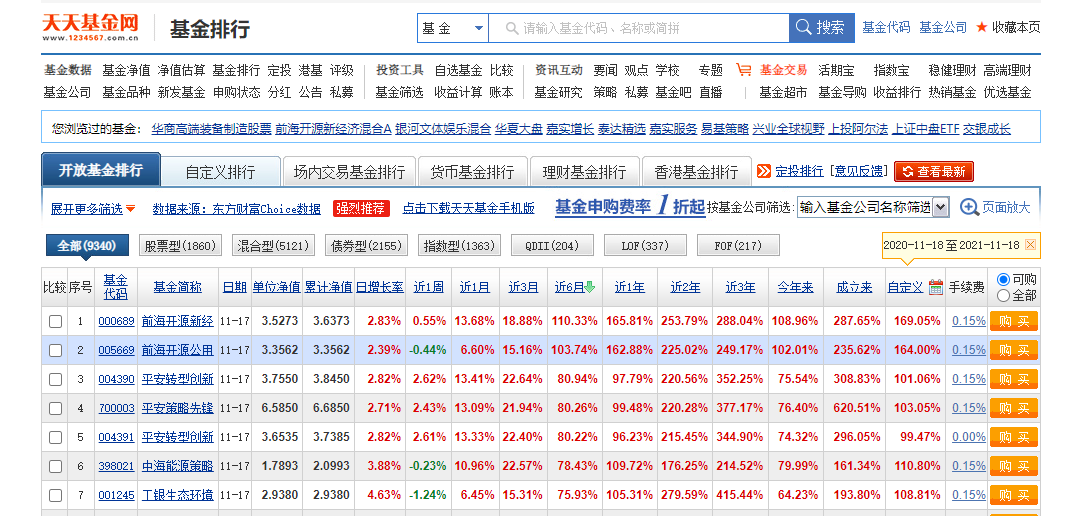
打开控制面板,找到 http://fund.eastmoney.com/data/rankhandler.aspx?op=ph&dt=kf&ft=all&rs=&gs=0&sc=6yzf&st=desc&sd=2020-11-18&... 的地址,这个地址返回的结果就是表格中的基金数据。

返回的数据类似于 json 串,根据观察基金代码似乎都是 6 位的数字,就可以使用正则表达式取到。
def crawler_front_page():
headers = {
'Referer': 'http://fund.eastmoney.com/data/fundranking.html',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36',
'Cookie': 'xxxx'
}
response = requests.get('http://fund.eastmoney.com/data/rankhandler.aspx?op=ph&dt=kf&ft=all&rs=&gs=0&sc=6yzf&st=desc&sd=2020-11-18&ed=2021-11-18&qdii=&tabSubtype=,,,,,&pi=1&pn=10000&dx=1&v=0.6791917206798068', headers=headers)
response.encoding = 'utf-8'
return response.text
def parse_front_page(html):
return re.findall(r"\d{6}",html)
股票持仓抓取
随便点开一个基金查看详情,然后往下拉到股票持仓的位置
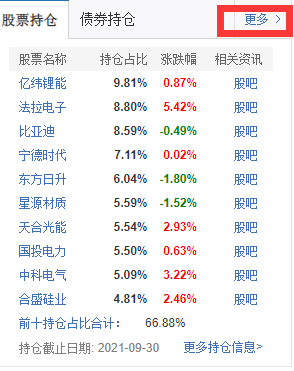
点开后,可以发现这个页面的网址是 http://fundf10.eastmoney.com/ccmx_ 加上 基金代码。
- 前海开源新经济混合A:http://fundf10.eastmoney.com/ccmx_000689.html
- 平安转型创新混合A: http://fundf10.eastmoney.com/ccmx_004390.html
所以只需要解析首页的基金代码,加上前面的 http://fundf10.eastmoney.com/ccmx_ 就可以得到最终的股票投资明细页面地址。一共是 9000 多条数据。
def get_stock_url(codes):
url = []
for code in codes:
url.append("http://fundf10.eastmoney.com/ccmx_{}.html".format(code))
return url
打开股票持仓页面就会发现这里面的数据是 js 加载的。这里需要抓取基金名称和股票名称。
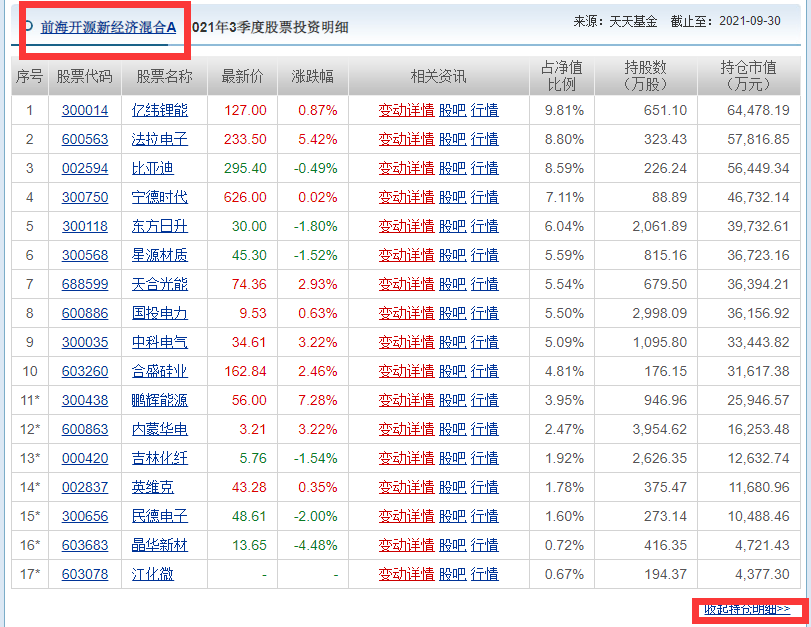
小编在这里采用了 selenium 方式抓取内容。用 xpath 解析页面。selenium 抓取速度比起 requests 方式是有点慢的,所以在这里开了多线程抓取。一共 10 个线程,每个线程抓取 1000 条数据。
def thread_test(*args):
threads = []
for crawler_count in ["0,1000", "1000,2000", "2000,3000", "3000,4000", "4000,5000", "5000,6000", "6000,7000", "7000,8000", "8000,9000", "9000,10000"]:
t = threading.Thread(target=crawler_stock_page, args=(crawler_count, args[0]))
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
抓取并解析页面后的内容是放在 text 文件中的,最后再读取处理数据。当然抓取的内容直接放在数据库是最好的,这样就不用再去解析一下文本文件。
def crawler_stock_page(c,stock_url_list):
count = c.split(",")
driver = webdriver.Chrome('D:\personal\gitpython\chromedriver.exe')
file = "D:/fund/fund_{}.txt".format(count[0])
for url in stock_url_list[int(count[0]):int(count[1])]:
stock_result = []
title = "没有数据"
try:
driver.get(url)
element_result = is_element(driver, By.CLASS_NAME, "tol")
if element_result:
wait = WebDriverWait(driver, 3)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'tol')))
if is_element(driver, By.XPATH, '//*[@id="cctable"]/div[1]/div/div[3]/font/a'):
driver.find_element_by_xpath('//*[@id="cctable"]/div[1]/div/div[3]/font/a').click()
wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'tol')))
stock_xpath = etree.HTML(driver.page_source )
stock_result = stock_xpath.xpath("//div[@id='cctable']//div[@class='box'][1]//td[3]//text()")
title = stock_xpath.xpath('//*[@id="cctable"]/div[1]/div/h4/label[1]/a')[0].text
with open(file, 'a+') as f:
f.write("{'name': '" + title + "', 'stock': ['"+'\',\''.join(stock_result) + "']}\n")
except:
continue
示例结果

解析文件
这步骤感觉有点多余,如果存在数据库中只需要一个查询语句就可以了。读取 fund 文件夹下的所有文件,并且一行一行用 eval() 转为字典。最终算出 9000 多基金中购买各个股票的有几家基金。
def parse_data():
result = {}
stock = {}
files= os.listdir('D:/fund/')
for file in files:
for line in open('D:/fund/' + file):
data = eval(line.strip())
key = data['name']
if key == '没有数据' or key in result:
continue
result[key] = data['stock']
for value in data['stock']:
if value in stock:
stock[value] = stock[value] + 1
else:
stock[value] = 1
with open('D:/fund_result/stock.csv', 'a+') as f:
for key in stock:
f.write(key + "," + str(stock[key]) + "\n")
with open('D:/fund_result/fund.csv', 'a+') as f:
for key in result:
values = []
for value in result[key]:
values.append('{}({})'.format(value, stock[value]))
f.write(key + ',' + ','.join(values) + '\n')
示例结果
stock.csv
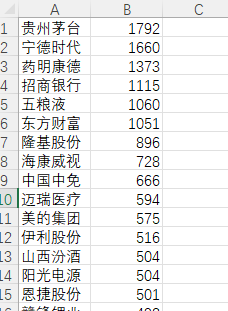
fund.csv

总结
股票有风险,入市需谨慎。基金有风险,入市需谨慎。
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!

【神秘礼包获取方式】
识别文末二维码,回复:1024