
《数据科学家100天精进计划》Day7:数据科学家常用R包
《数据科学家100天精进计划》,分享我作为数据科学家的所学、所想和所做,希望帮助更多人了解数据科学家或者成为数据科学家。
《数据科学家100天精进计划》Day1:数据科学家黄金圈法则
《数据科学家100天精进计划》Day2:数据科学工作流 《数据科学家100天精进计划》Day3:数据科学家技能修炼 《数据科学家100天精进计划》Day4:我的数据科学高效工具分享 《数据科学家100天精进计划》Day5:数据科学家的SQL技术清单 《数据科学家100天精进计划》Day6:数据科学家R语言学习指南
Day7:数据科学家常用R包
R语言功能强大,R包功不可没。
有许多R包可供数据科学家在不同领域进行数据处理、分析、可视化和建模。本文包括3个内容。
1)R包管理知识
2)数据科学常用R包
3)我学习和使用R包的心得
1 R包管理知识
R包管理知识,我们需要掌握如何正确安装和卸载R包。
我使用过的R包安装方法
1)直接从CRAN上面安装,选择离自己最近的镜像,使用install.packages()安装R包。举例说明
# 安装数据科学套件包
install.packages('tidyverse')
2)从Github上面安装,可以在线安装或者下载源码后,经过编译后,再安装。举例说明
install.packages("devtools")
library(devtools)
# 安装github上的R包
devtools::install_github('lchiffon/REmap')
3)生物信息的一些R包,可以从Bioconductor包安装,Bioconductor可以简单理解为基于R语言专门做生物信息学分析的众多工具包的集合。举例说明
# 安装limma包
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install("limma")
卸载R包,直接使用remove.packages()函数操作。
2 数据科学家常用R包
数据科学家们,经常使用的R语言包,简单说明如下,更详细地介绍,可以查看对应包的帮助文档和使用范例。我的亲身经验,要用好一个R包,一定要利用好帮助文档和范例,还有基于这个R包的做项目的他人的代码,这些都是很好的学习素材,值得你去阅读和迁移。
1) dplyr:这是一个功能强大的数据操作包,使数据清洗和操纵任务变得容易。dplyr提供了一系列函数,用于进行基本的数据操作,如筛选、聚合、排序、重命名变量等。这个包的一个显著优势在于其符合直觉的语法。
2)tidyr:tidyr是一个用于整理数据的包,目的是将数据整理为“长格式”或“宽格式”。这有助于分组操作、存储数据以及与ggplot2进行集成。
3) lubridate:lubridate是一个处理日期和时间数据的包,提供了一系列易于使用的函数,用于解析、操作和格式化日期和时间数据。它简化了跨时间格式的工作,包括转换为不同的时区,处理闰年等。
4) ggplot2:这是一个优秀的数据可视化包,使用图形语法(Grammar of Graphics)创建精美且信息丰富的图表。ggplot2提供了一套灵活且统一的界面来构建复杂的定制图形。
5) randomForest:这个包实现了随机森林算法,用于分类和回归任务。随机森林是一种强大的集成学习技术,通过构造多个决策树来提高预测精度。
6) xgboost:Extreme Gradient Boosting(xgboost)包提供了一个优化梯度增强算法的实现。它在大量机器学习竞赛中取得了优异成绩,被认为是一种非常强大且实用的预测模型。
7) caret:Classification And REgression Training(Caret)是一个流行的机器学习框架,用于构建和评估各种预测模型。Caret包含大量常用的机器学习算法,并提供了一个简单的界面来进行数据预处理、特征选择、模型训练和评估等步骤。
8)rmarkdown:rmarkdown包用于R Markdown文档的编辑,R Markdown文档(可以包含富文本和R代码)方便写数据报告,支持生成多种格式,例如html、PDF等。
9)shiny:shiny是一个构建交互式web应用程序的框架,用于实时发布、共享和探索数据。可视化和R代码可以轻松地整合在一起,不需要任何web开发经验即可发布到Web上。
3 我学习和使用R包的心得
我在使用R语言做数据科学工作时,离不开R包。我简洁分享下自己学习和使用R包的心得。
1)学习R包这块
第一步:明确问题和目标,例如我要学习R语言做数据可视化分析,我会检索R语言做可视化的包,确定所要学习的R包
第二步:R包管理,对需要学习的R包进行正确安装,便于后续学习和使用。
第三步:查看R包帮助文档和范例。
# 数据可视化包ggplot2
help(package="ggplot2")
结果如下
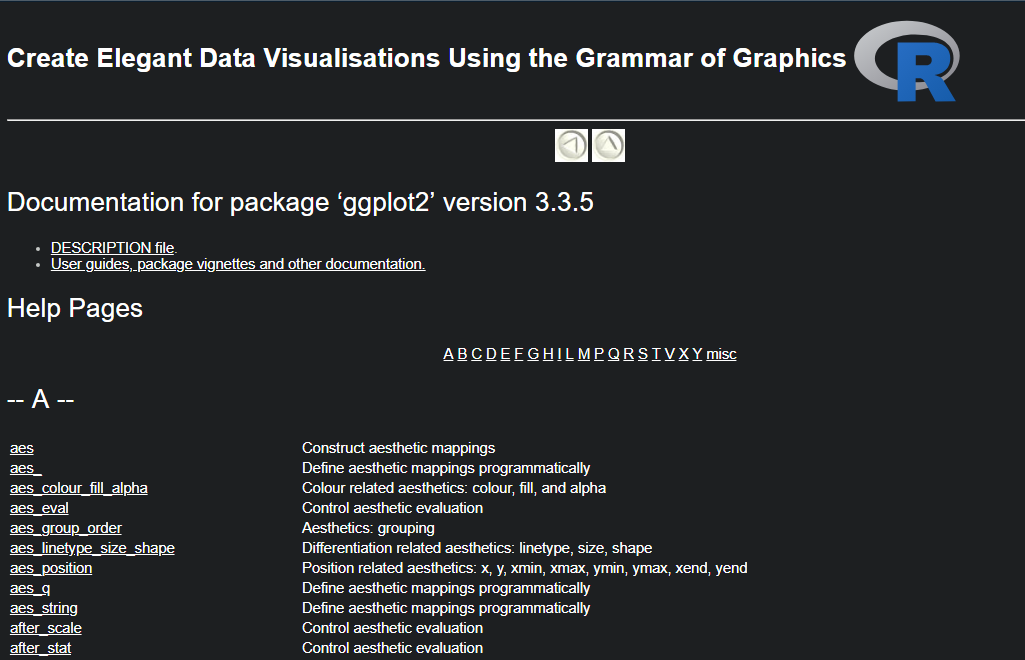
这份结果提供这些重要信息
1)这个R包介绍和用途
2)这个R包按着字幕排序的函数集和内嵌数据集
第四步:多阅读这个R包使用的案例和代码,我会基于我关注的问题或者要学习的内容从Github上面寻找代码,并从代码中学习。
2)使用R包这块,根据自己要解决的问题,选择合适的R包,然后就是安装和加载R包,利用R包提供的函数集,解决自己的问题或者做自己想做的事情。
总之,作为一名数据科学家,学习和熟练上述R包,一来可以提升数据科学工作的水平,二来数据科学工作流各个环节都有了合理的解决方案。
我的微信二维码,欢迎你添加,大家多交流。