
三个优秀的PyTorch实现语义分割框架

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
使用的VOC数据集链接开放在文章中,预训练模型已上传Github,环境我使用Colab pro,大家下载模型做预测即可。
代码链接: https://github.com/lixiang007666/segmentation-learning-experiment-pytorch
使用方法:
下载VOC数据集,将 JPEGImagesSegmentationClass两个文件夹放入到data文件夹下。终端切换到目标目录,运行 python train.py -h查看训练
(torch) qust116-jq@qustx-X299-WU8:~/语义分割$ python train.py -h
usage: train.py [-h] [-m {Unet,FCN,Deeplab}] [-g GPU]
choose the model
optional arguments:
-h, --help show this help message and exit
-m {Unet,FCN,Deeplab}, --model {Unet,FCN,Deeplab}
输入模型名字
-g GPU, --gpu GPU 输入所需GPU
选择模型和GPU编号进行训练,例如运行python train.py -m Unet -g 0
预测需要手动修改 predict.py中的模型
如果对FCN非常了解的,可以直接跳过d2l(动手学深度学习)的讲解到最后一部分。
2 数据集
VOC数据集一般是用来做目标检测,在2012版本中,加入了语义分割任务。
基础数据集中包括:含有1464张图片的训练集,1449的验证集和1456的测试集。一共有21类物体。
PASCAL VOC分割任务中,共有20个类别的对象,其他内容作为背景类,其中红色代表飞机类,黑色是背景,飞机边界部分用米黄色(看着像白色)线条描绘,表示分割模糊区。
其中,分割标签都是png格式的图像,该图像其实是单通道的颜色索引图像,该图像除了有一个单通道和图像大小一样的索引图像外,还存储了256个颜色值列表(调色板),每一个索引值对应调色板里一个RGB颜色值,因此,一个单通道的索引图+调色板就能表示彩色图。
原图:
标签:
挑选一张图像可以发现,单张图像分割类别不只两类,且每张图像类别不固定。

语义分割能对图像中的每个像素分类。全卷积网络 (fully convolutional network,FCN) 采用卷积神经网络实现了从图像像素到像素类别的变换 。与我们之前在图像分类或目标检测部分介绍的卷积神经网络不同,全卷积网络将中间层特征图的高和宽变换回输入图像的尺寸:这是通过中引入的转置卷积(transposed convolution)层实现的。因此,输出的类别预测与输入图像在像素级别上具有一一对应关系:给定空间维上的位置,通道维的输出即该位置对应像素的类别预测。
%matplotlib inline
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
3.1 网络结构
全卷积网络先使用卷积神经网络抽取图像特征,然后通过 卷积层将通道数变换为类别个数,最后再通过转置卷积层将特征图的高和宽变换为输入图像的尺寸。因此,模型输出与输入图像的高和宽相同,且最终输出的通道包含了该空间位置像素的类别预测。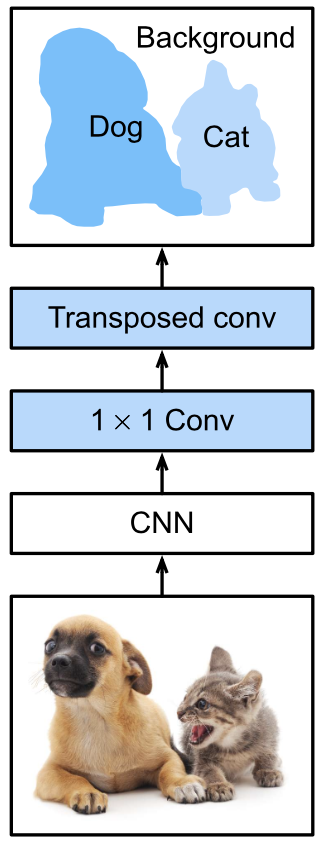
下面,我们使用在ImageNet数据集上预训练的ResNet-18模型来提取图像特征,并将该网络实例记为pretrained_net。该模型的最后几层包括全局平均汇聚层和全连接层,然而全卷积网络中不需要它们。
pretrained_net = torchvision.models.resnet18(pretrained=True)
list(pretrained_net.children())[-3:]
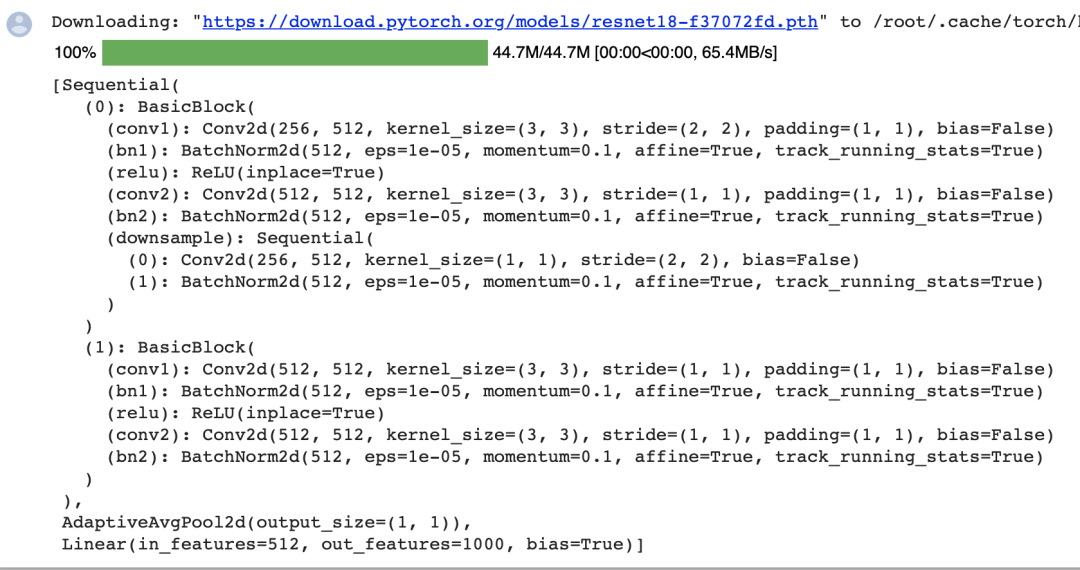 创建一个全卷积网络实例
创建一个全卷积网络实例net。它复制了Resnet-18中大部分的预训练层,但除去最终的全局平均汇聚层和最接近输出的全连接层。
net = nn.Sequential(*list(pretrained_net.children())[:-2])
给定高度和宽度分别为320和480的输入,net的前向计算将输入的高和宽减小至原来的,即10和15。
X = torch.rand(size=(1, 3, 320, 480))
net(X).shape
 使用卷积层将输出通道数转换为Pascal VOC2012数据集的类数(21类)。最后,我们需要将要素地图的高度和宽度增加32倍,从而将其变回输入图像的高和宽。
使用卷积层将输出通道数转换为Pascal VOC2012数据集的类数(21类)。最后,我们需要将要素地图的高度和宽度增加32倍,从而将其变回输入图像的高和宽。
回想一下卷积层输出形状的计算方法:
由于且,我们构造一个步幅为的转置卷积层,并将卷积核的高和宽设为,填充为。
我们可以看到如果步幅为,填充为(假设是整数)且卷积核的高和宽为,转置卷积核会将输入的高和宽分别放大倍。
num_classes = 21
net.add_module('final_conv', nn.Conv2d(512, num_classes, kernel_size=1))
net.add_module('transpose_conv', nn.ConvTranspose2d(num_classes, num_classes,
kernel_size=64, padding=16, stride=32))
3.2 初始化转置卷积层
将图像放大通常使用上采样(upsampling)方法。双线性插值(bilinear interpolation) 是常用的上采样方法之一,它也经常用于初始化转置卷积层。
为了解释双线性插值,假设给定输入图像,我们想要计算上采样输出图像上的每个像素。
首先,将输出图像的坐标 (𝑥,𝑦) 映射到输入图像的坐标 (𝑥′,𝑦′) 上。例如,根据输入与输出的尺寸之比来映射。请注意,映射后的 𝑥′ 和 𝑦′ 是实数。
然后,在输入图像上找到离坐标 (𝑥′,𝑦′) 最近的4个像素。
最后,输出图像在坐标 (𝑥,𝑦) 上的像素依据输入图像上这4个像素及其与 (𝑥′,𝑦′) 的相对距离来计算。
双线性插值的上采样可以通过转置卷积层实现,内核由以下bilinear_kernel函数构造。限于篇幅,我们只给出bilinear_kernel函数的实现,不讨论算法的原理。
def bilinear_kernel(in_channels, out_channels, kernel_size):
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = (torch.arange(kernel_size).reshape(-1, 1),
torch.arange(kernel_size).reshape(1, -1))
filt = (1 - torch.abs(og[0] - center) / factor) * \
(1 - torch.abs(og[1] - center) / factor)
weight = torch.zeros((in_channels, out_channels,
kernel_size, kernel_size))
weight[range(in_channels), range(out_channels), :, :] = filt
return weight
用双线性插值的上采样实验它由转置卷积层实现。我们构造一个将输入的高和宽放大2倍的转置卷积层,并将其卷积核用bilinear_kernel函数初始化。
conv_trans = nn.ConvTranspose2d(3, 3, kernel_size=4, padding=1, stride=2,
bias=False)
conv_trans.weight.data.copy_(bilinear_kernel(3, 3, 4));
在全卷积网络中,我们用双线性插值的上采样初始化转置卷积层。对于 1×1卷积层,我们使用Xavier初始化参数。
W = bilinear_kernel(num_classes, num_classes, 64)
net.transpose_conv.weight.data.copy_(W);
3.3 训练
损失函数和准确率计算与图像分类中的并没有本质上的不同,因为我们使用转置卷积层的通道来预测像素的类别,所以在损失计算中通道维是指定的。此外,模型基于每个像素的预测类别是否正确来计算准确率。
def loss(inputs, targets):
return F.cross_entropy(inputs, targets, reduction='none').mean(1).mean(1)
num_epochs, lr, wd, devices = 5, 0.001, 1e-3, d2l.try_all_gpus()
trainer = torch.optim.SGD(net.parameters(), lr=lr, weight_decay=wd)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)
4 开源代码和Dataset
数据集下载地址:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
输入样本:
输出样本:
运行Segmentat_pytorch.ipynp:
 训练:
训练:
!python3 train.py -m Unet -g 0
预测:
模型代码包括FCN、U-Net和Deeplab的实现,大家可以更方便的更换模型训练和预测。
DeeplabV3分割结果: FCN分割结果:
FCN分割结果:
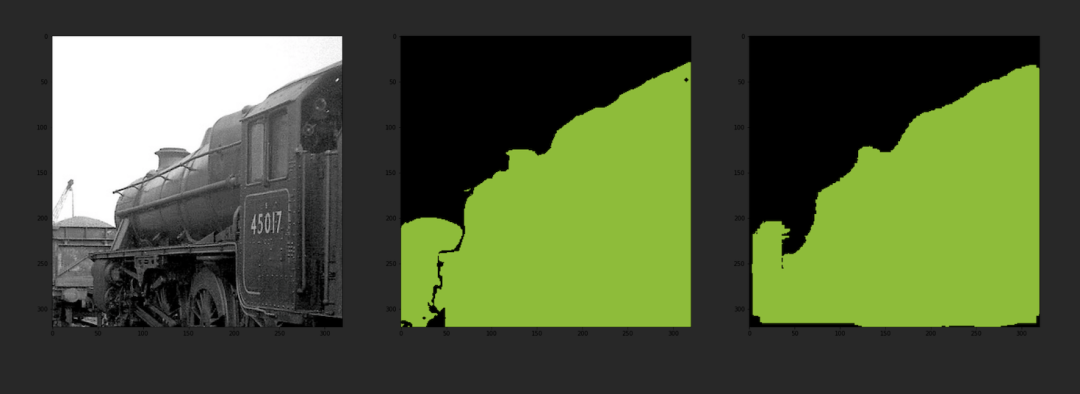
U-Net分割结果: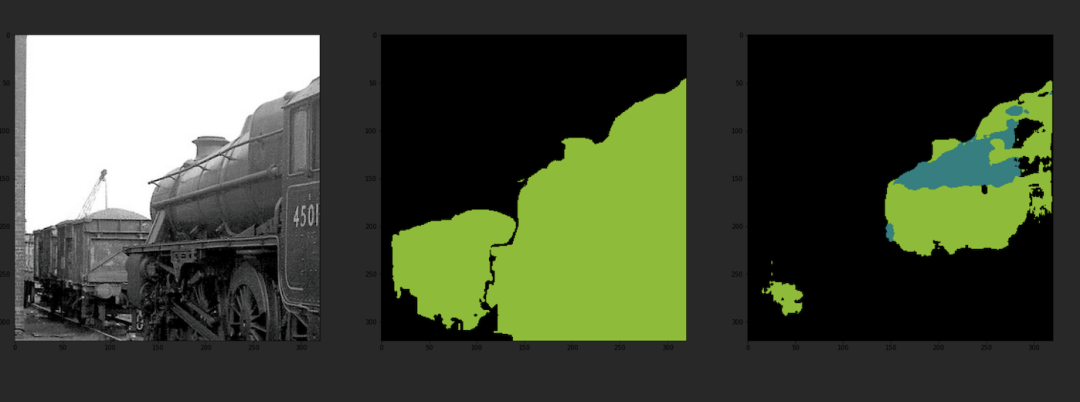
记得点个Star哦!
5 总结
通过与分割标准图像的对比,可以发现该模型的输出分割图像与分割标准图像几乎一致,同时模型的输出分割图像与原图也较好的融合,说明该模型具有较好的准确性。
此外,从输入图像大小来看,该模型可以输入任意大小的图像,并输出相同大小的已经标签好的分割图像。由于是针对PASCAL VOC数据集图像进行的分割,PASCAL VOC数据集中只支持20个类别(背景为第21个类别),所以在分割时,遇到不在20个类别中的事物都将其标为背景。
但总体来说,该模型对PASCAL VOC数据集的图像分割达到了较高准确率。
6 参考
[1].https://zh-v2.d2l.ai/index.html
个人简介:李响Superb,CSDN百万访问量博主,普普通通男大学生,深度学习算法、医学图像处理专攻,偶尔也搞全栈开发,没事就写文章。
博客地址:lixiang.blog.csdn.net
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx