
.NET 微服务实战之必须得面对的分布式问题
共 5030字,需浏览 11分钟
·
2021-02-04 21:45

转自:陈珙 cnblogs.com/skychen1218/p/14346459.html
前言
不少小伙伴看了我的博客的后跟我探讨问题时都离不开数据一致性、数据关联、数据重复创建的问题,只要大家做的分布式系统无论是否微服务化,或多或少都会遇到上述问题,而上述的问题的本质其实就是分布式事务、分布式数据关联与幂等性。
这三个问题也是很多面试官在面试的时候检验应聘者是否有实践过分布式系统的经验的标准之一,而微服务作为分布式系统的架构风格,在实施过程中也无法幸免以上问题。
源码:https://github.com/SkyChenSky/Sikiro
分布式基础概念
用微服务架构风格设计出来的系统是典型的分布式系统。
分布式计算是指系统的工作方式,主要分为数据分布式和任务分布式:
数据分布式也称为数据并行,把数据拆分后,利用多台计算机并行执行多个相同任务。优点是缩短所有任务总体执行时间,缺点是无法减少单个任务的执行时间。
任务分布式也称为任务并行,单个串行的任务拆分成多个可并行子任务。优点是提高性能、可扩展性、可维护性,缺点是增加设计复杂性。

分布式系统必须面临的哪些问题?
我们日常工作的时候 ,接触到任务分布式的情况相对比较多例如:第三方支付请求,API编排数据关联。从场景划分主要分为单服务多数据库,多服务多数据库,多服务单数据库,以上三种场景都会存在多台服务器之间跨网络调用的情况,由原单进程单数据库内的简单实现的原子性、一致性变得不得不去面对因为跨网络请求得幂等性和数据一致性。
数据库一致性又分读和写,读对应着数据库跨库跨服务器的数据关联,写对应着分布式事务的数据最终一致性的处理。
数据关联的复杂度场景主要体现在分库分服务器与多接口数据关联的场景应该怎么解决?
分布式事务如果在单服务多数据库的场景下想必大家都会想出像Sql Sever的MSDTC的XA协议事务。如果是在多服务多数据库该选用怎样的分布式事务方案?
在分布式场景下幂等性的保证是无法避免的,网络是存在不确定性的,一个请求可能会成功,但也会因为客观因素导致失败,那么重新发起请求就无发避免的了,那么如何保证我不会重复创建数据与数据被覆盖呢?
下文我将从数据关联,分布式事务和幂等性三个角度进行叙述方案。
数据关联
数据关联的主要方案有三种,应用层数据聚合、冗余设计(反范式)、数据库从库集成。

举个常见的例子:分布式情况下,比如现在有两个服务,分别是用户,订单。每个服务都是自己独立的数据库。用户数据库有用户信息表,订单数据都有关联用户的唯一id。
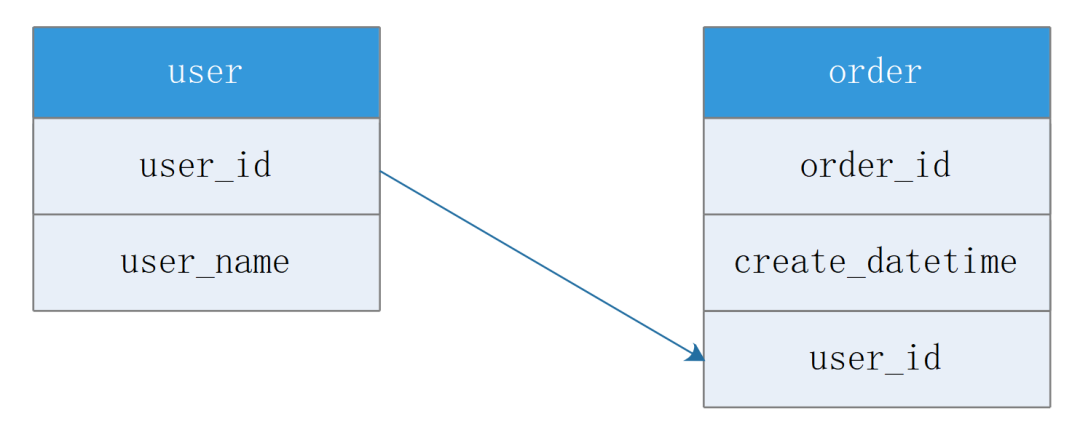
应用层数据聚合
先调用订单服务得到订单列表后,再根据订单列表的用户ID集合调一次用户服务查询出用户列表。再通过内存遍历把订单列表与用户列表在业务层整合。
优点,实现简单;缺点,也是简单,该方案只能适合简单的查询过滤,以主表为驱动的关联。
public async Task> GetOrder()
{
//订单集合
var orderList = await _order.GetList();
//userId集合
var userIds = orderList.Select(a => a.UserId).ToList();
//关联用户集合
var users = await _user.GetByIds(userIds);
//应用层数据聚合关联
orderList.ForEach(order =>
{
order.Name = users.FirstOrDefault(a => a.UserId == order.UserId)?.Name;
});
return orderList;
} 冗余设计(反范式)
在订单表增加和用户有关信息的字段。
优点,实现简单,以应用层数据聚合方案有更多的过滤条件;缺点,冗余的字段如果更新存在同步问题,该方案适用于更新频繁少的递增日志类数据。

数据库从库集成
通过主从同步技术,把相关的业务表同步到同一台服务器我们称为ReportDB,再通过在代码层面把数据源连接指向从库做跨库联表查询处理。
优点,通过强大的SQL解决复杂的报表类查询;缺点,拥有技术复杂度,需要数据库主从处理。

分布式事务
分布式事务分刚性事务与柔性事务,刚性事务对应ACID理论,而柔性事务也就是最终一致性,对应BASE理论。最终一致性指如果数据再一段时间内没有被另外的数据操作所更改,那它最终会达到与强一致性过程相同的结果。
分布式系统场景下很少使用xa事务,主要原因是xa事务是基于基础设施层面的强一致性事务,场景主要在一个服务多个数据源,追求强一致性,复杂度高,吞吐量低。
而最终一致性方案更多是基于服务应用层的弱一致性事务,场景主要是多服务多数据源与多服务单数据源,满足了BASE理论的三个特点:基本可用、软状态、最终一致性
以订单支付为例讲述下BASE理论,客户在A平台发起了订单支付,订单支付时状态为支付中,完成后支付后,等待支付系统的回调,但是这个时候,A平台的回调API接口异常了,订单状态无法同步为已支付状态,这个时候客户看到订单的金额支付出去了,但是去搜索订单模块的时候发现还是未支付,于是反馈给了客服,开发部经过一段时间的问题定位与排查,发现是回调API挂了于是重启后,数分钟订单状态就同步成已完成了。

从上面的例子来看,支付中就是软状态,回调API服务虽然挂了,但是前台系统还是可以提供给客户端查询使用就是基本可用,只不过订单状态不对,当然最后服务也恢复后达成数据最终一致性。
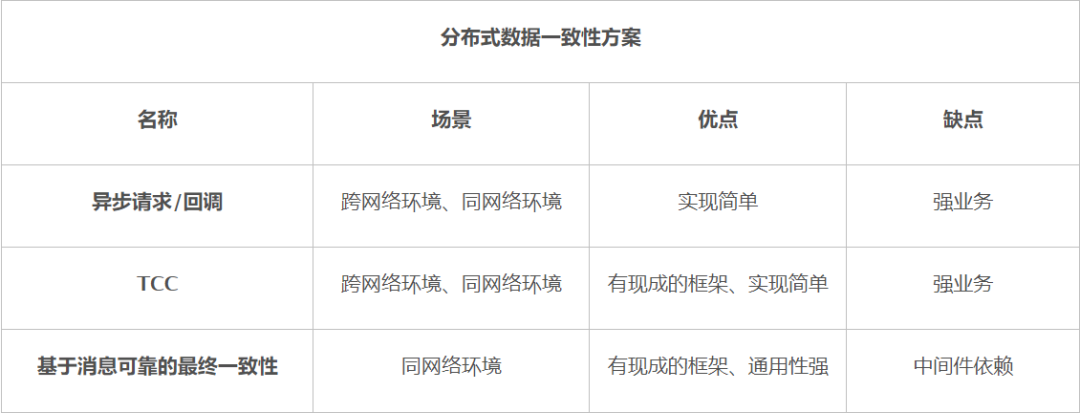
分布式事务方案常见的主要有这几种:异步请求/回调、TCC、基于消息可靠的最终一致性,TCC与基于消息可靠的最终一致性在Java和.Net都是有现成的框架,而异步请求/回调更多是与支付机构对接的场景会比较多,实现简单、通用性强,如果团队技术能力不足也可以使用该方案代替。
异步请求/回调更多是应对并发处理的异步解决方案,查过相关资料并没有纳入相关分布式事务方案中,但是在我的实际工作经验中该方案也是可以达成最终一致性。
异步请求/回调
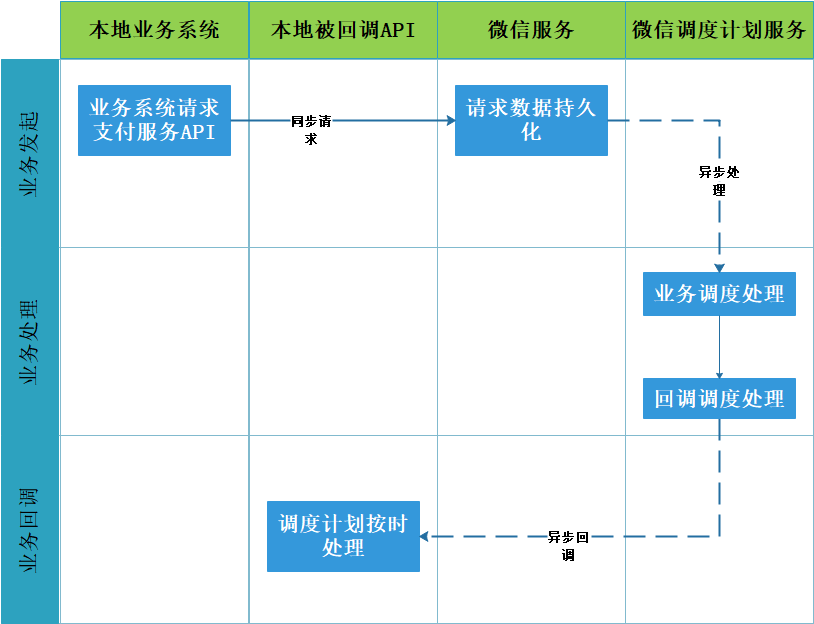
该方案在与支付机构对接的场景比较常见,其核心以业务发起请求,被调用端以数据优先入库,稍后异步处理,处理完成后则回调请求业务端提供的API。
这种异步处理方式一般获取结果的方式推拉结合,外部系统主动回调给本地称之为推,本地系统每隔一段时间主动查询外部系统结果称为拉,两者可以按照业务的时效性结合策略使用。
公司内部系统之间也可以这么做,业务系统请求对接系统,被请求后数据库直接入库,然后通过定时调度任务异步做业务处理,业务处理成功还是失败都修改状态,最后由回调调度任务把业务处理的状态、处理信息回调给业务系统的回调API,为了避免回调调度任务因故障无法回调,可以设置策略由业务系统主动查询对接系统提供的查询API,推拉结合保证了系统可用性和数据时效性。
TCC
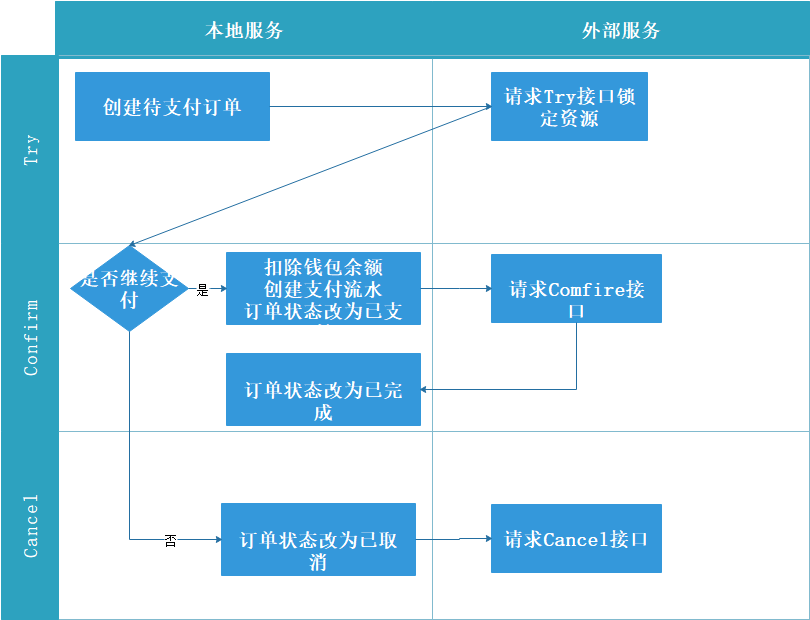
TCC是Try、Comfirm、Cancel三个单词的缩写,Try是资源预留、锁定,Comfirm是确认提交,Cancel是指撤销。一个资源的处理需要提供三个接口,从业务侵入性来看是比较强的。
TCC的执行步骤与2PC有点相似,先进入预提交阶段,对A、B、C三个资源的分别进行try处理,如果try请求成功,相应的资源就会被修改成中间状态,可以理解成被冻结。接下来就会根据每个资源try后的情况判断如何执行。如果全部try成功,则会进入Comfirm处理,只要能try成功就能Comfirm成功。如果其中一个资源try失败了,则会对所有进行Cancel处理。
TCC与2PC看起来相似,但还是有区别的,TCC是应用服务层面的,而2PC则是基础设施层,而2PC因为是强一致性基于遵守ACID,在事务未提交时处于阻塞状态,如果失败则会事务回滚,而TCC是没有事务回滚的,每个阶段处理都穿透到数据库都是Commit操作。
基于消息的最终一致性
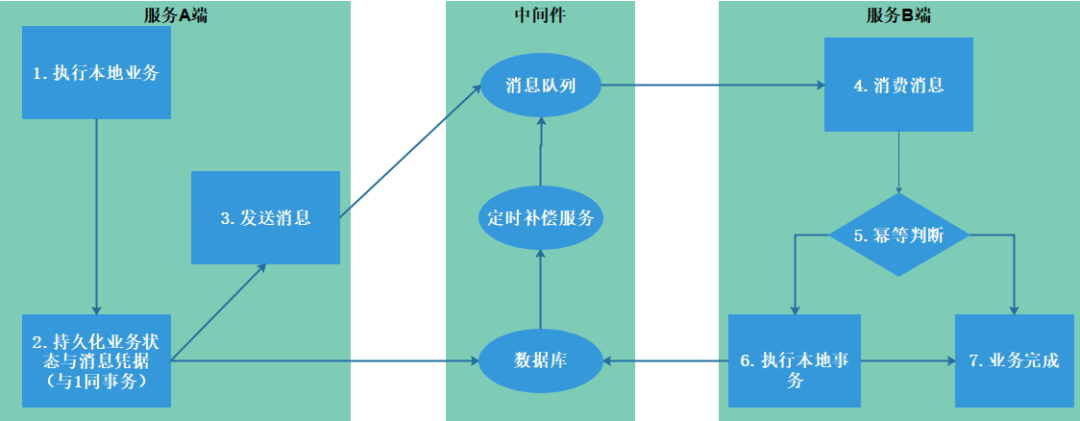
该方案其实是ebay多年前提出的本地消息表的解决方案,该方案的核心点在于,执行本地事务后再提交队列消息,这两步骤操作因为非原子性的跨进程操作,因为需要保证发送到消息队列的消息能正常发布与正常的消费,这就是我们常说的保证消息可靠,那么在执行本地事务的时候,本地业务表与消息凭据表会作为一个原子性事务提交到数据库,消息凭据表会记录着消息队列的消息序列化数据,如果本地事务提交成功了,但是发送消息队列的时候失败了,就会通过后台线程(进程)查询消息凭据表,把未发送成功的消息反序列化出来重新发起。
无论再消息发布端还是消息消费端都会因为与消息队列交互后,修改消息凭据表状态的情况,如果与消息队列交互是正常的,但是修改消息凭据状态失败了,补偿服务仍然会进行不必要的重发,那么这个场景容易导致数据重复创建与覆盖,因此需要关注幂等性的处理了。
该方案在.Net有CAP这个分布式事务框架,无需开发人员自己自己实现。
幂等性
幂等性的定义,相同的参数在同一个方法里,无论执行一次还是多次都会响应相同的结果
举个例子银行转行,A银行账户扣了100元,B银行账户加100元,这样数据一致的。但是在给B账户加100元的时候,B银行系统处理超时,但是其实这个时候B银行是已经处理成功了,只不过没响应回去,那么A银行系统就会重发,如果没有幂等性处理的话,A重试了3次,B账户就会加3次100。一边扣100,一边加300,那么数据就不一致了。
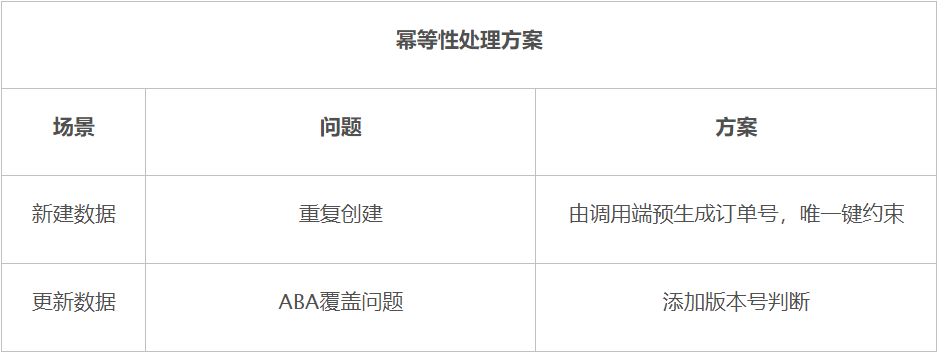
对于查询和删除数据的场景都有天然的幂等性,那么我们考虑幂等性处理更多是关注于新建数据与更新数据。
新建数据的场景,如果没有处理好幂等性,那么就会导致数据重复创建,原因有可能是用户连续点击后发起请求,也有可能是API网关的retry请求。解决方案也相对比较简单,API提供主键参数(流水号)传入,就是由调用端预生成主键(流水号)传入API进行请求,API端生成流水与余额扣减作为同一个事务处理。此时如果因为某个原因进行了两次调用,因为第一次创建成功了,第二次则会因为主键的唯一性抛出了异常,这里需要注意的是得捕获到的唯一键异常应处理成执行成功的响应。
更新数据的场景,如果没处理号幂等性,可能会因为RPC框架或者API网关的Retry机制导致重复请求,这样就会造成了ABA的数据覆盖问题,所谓的ABA就是,第一次请求A数据已经进行写处理了,接着到了第二次请求B数据进行对A数据进行了修改成功了,但是因为第一次请求因为某个原因导致客户端无法接收到响应,因此API网关或者RPC框架进行了重发,所以第三次把A数据又对已有的B数据进行修改覆盖。针对该问题解决方案主要是使用数据版本判断。
以上两种方法处理方式从数据库层面解决,相对比较简单直接,侵入性比较强,还有一种方案可以从Web框架层面解决,结合Web框架的AOP与Redis判断,每次请求都会附带一个requestID传入到接口,由Filter拦截后Add到Redis。此方案需要引入Redis,从实现上比前面两个相对复杂,但是通用性相对高一些。
结束
该篇到这里就结束了,主要总结了平常在分布式系统不得不去面对的问题,虽然大家会通过一些设计,尽可能去避免,但是唯一不变的是需求的变化,因此我们尽可能优先了解各种处理方案,如有遇到就可针对场景选择合适的方案。
.NET Core实战项目之CMS 第一章 入门篇-开篇及总体规划
【.NET Core微服务实战-统一身份认证】开篇及目录索引
Redis基本使用及百亿数据量中的使用技巧分享(附视频地址及观看指南)
.NET Core中的一个接口多种实现的依赖注入与动态选择看这篇就够了
用abp vNext快速开发Quartz.NET定时任务管理界面