卷积神经网络(CNN)数学原理解析
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
原标题 | Gentle Dive into Math Behind Convolutional Neural Networks
翻 译 | 通夜(中山大学)、had_in(电子科技大学) 来源 | 图灵人工智能
介绍

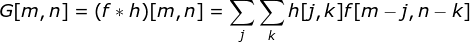
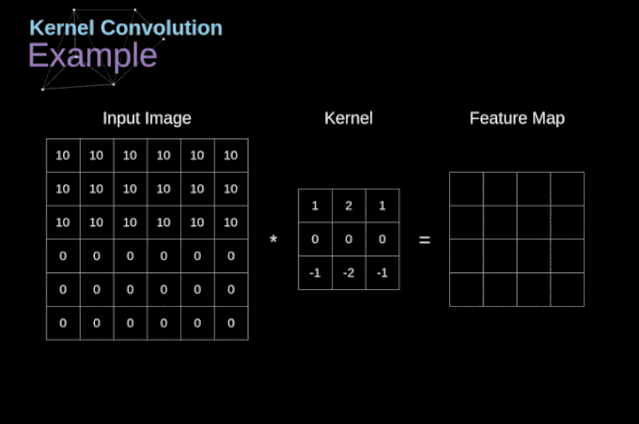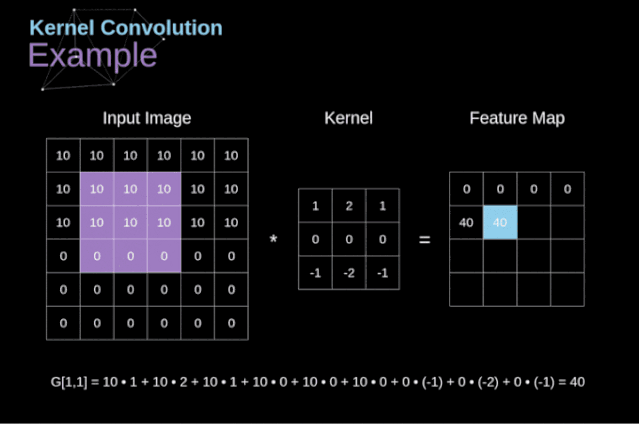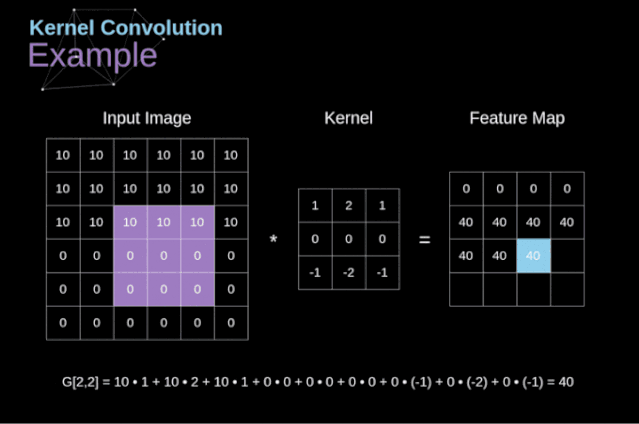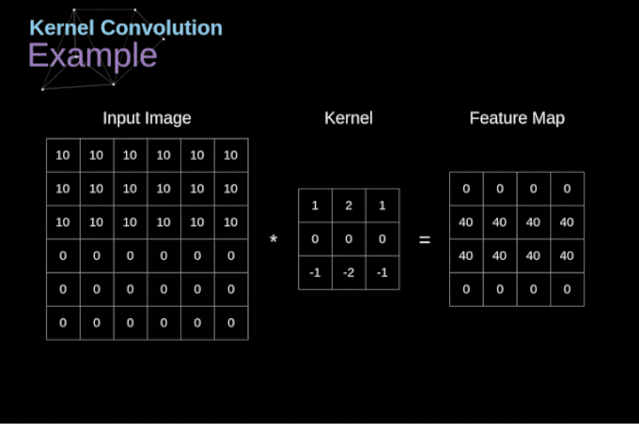

有效卷积和相同卷积
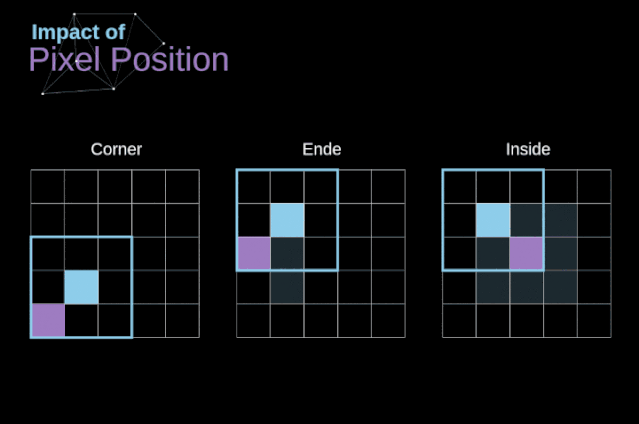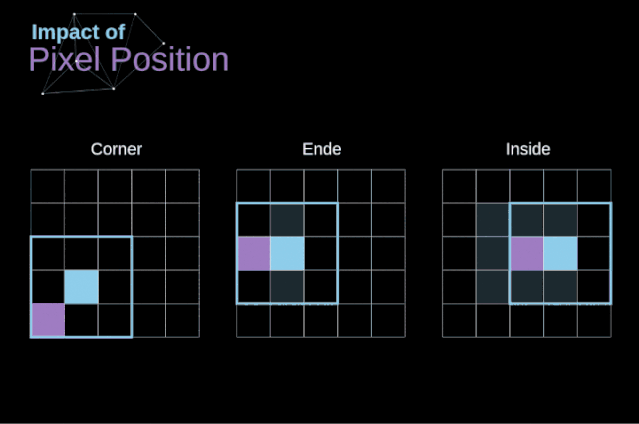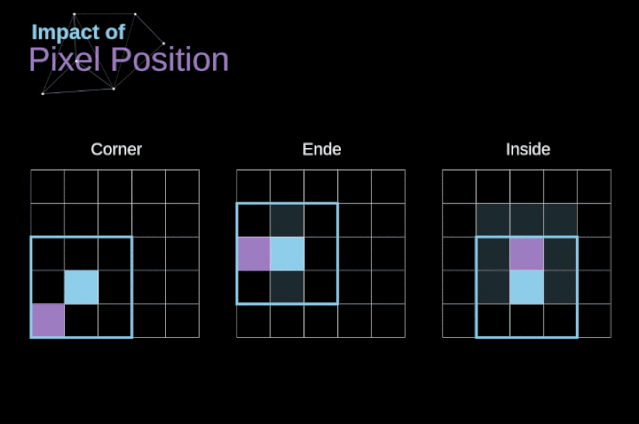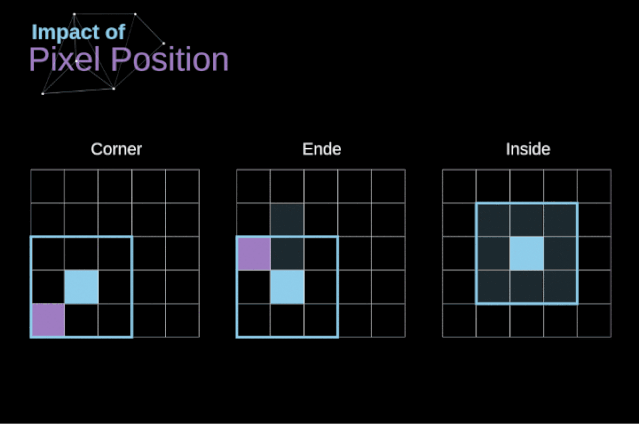
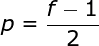
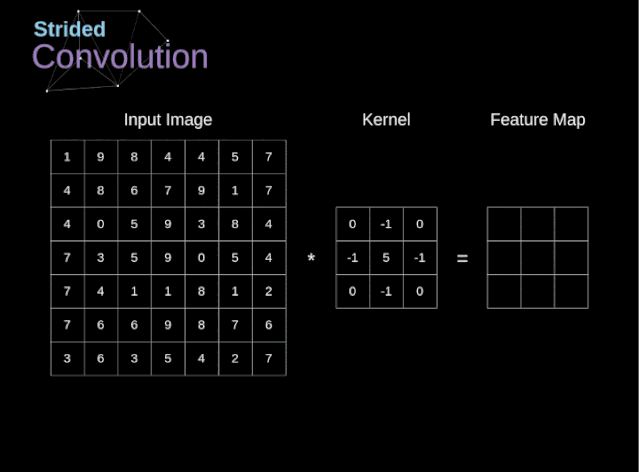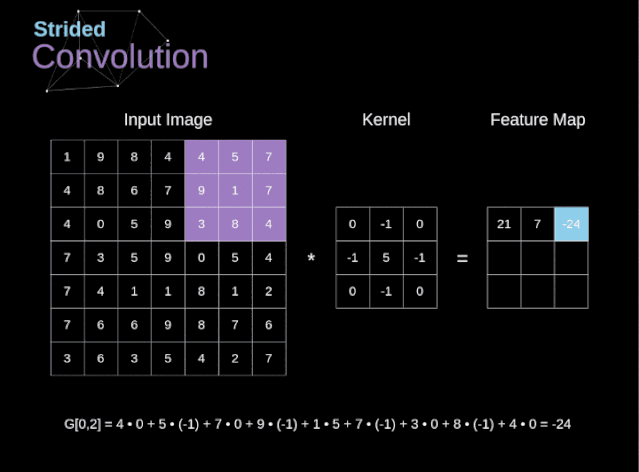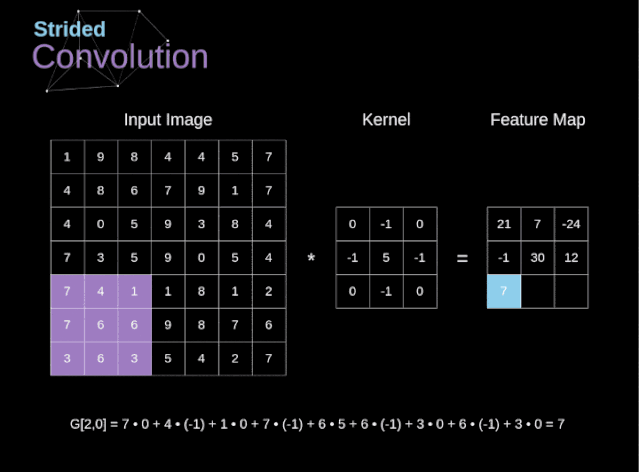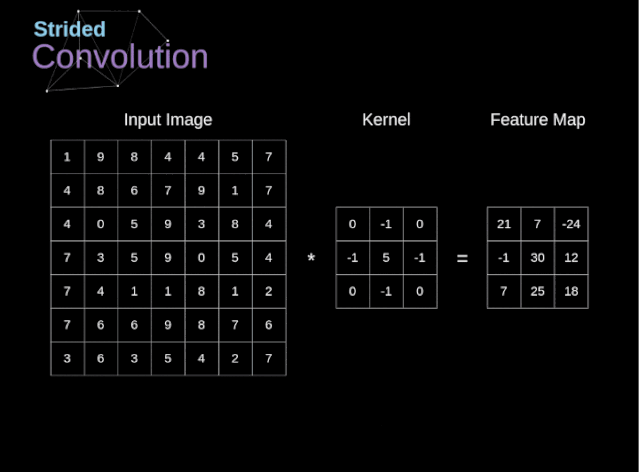
步幅卷积

过渡到三维
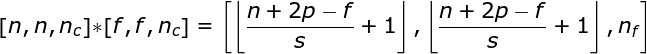
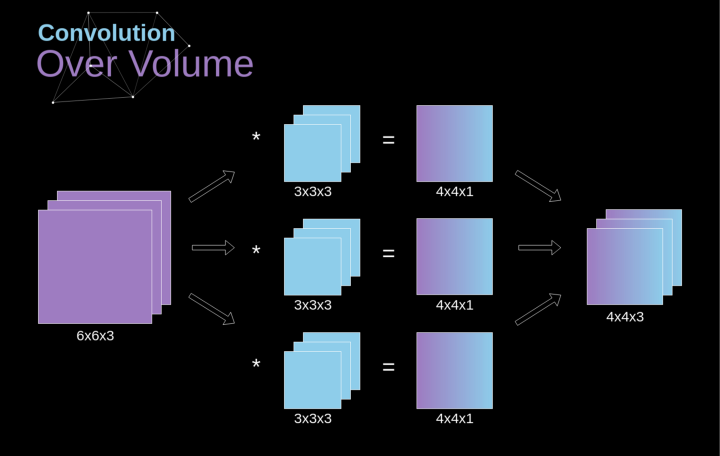
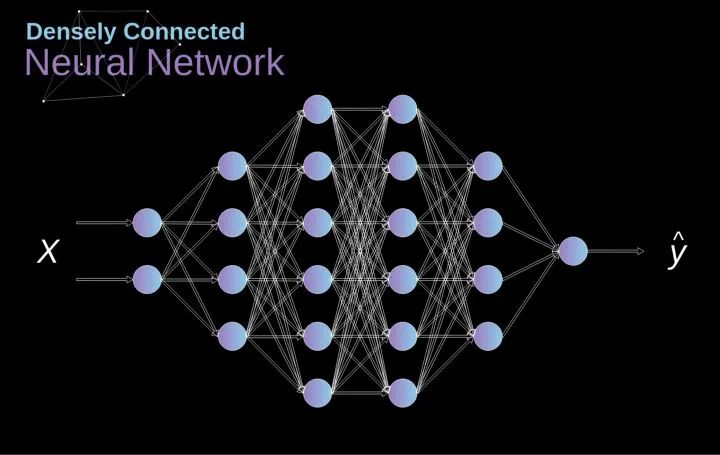
卷积层
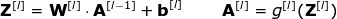
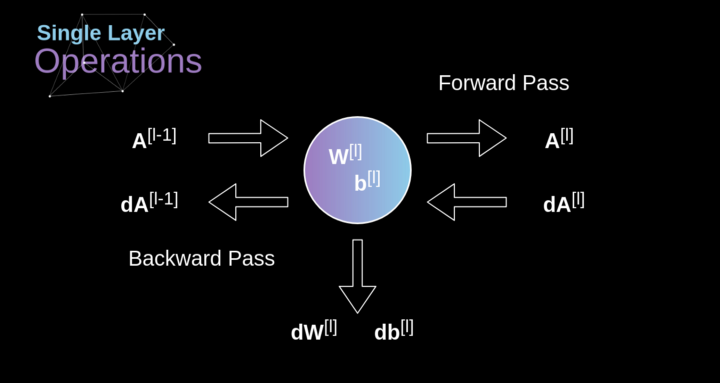
连接剪枝和参数共享

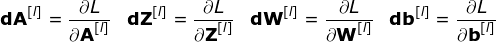
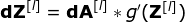
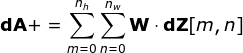

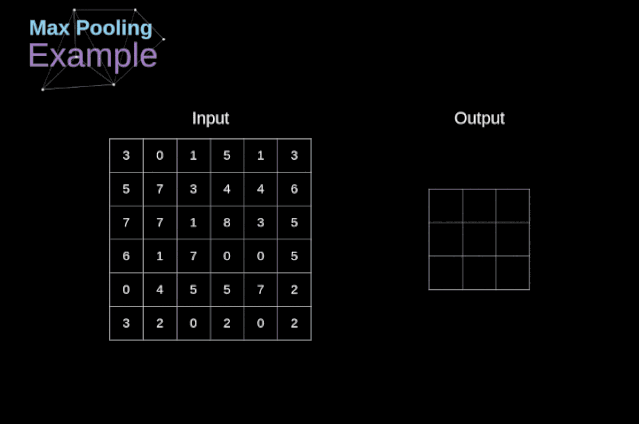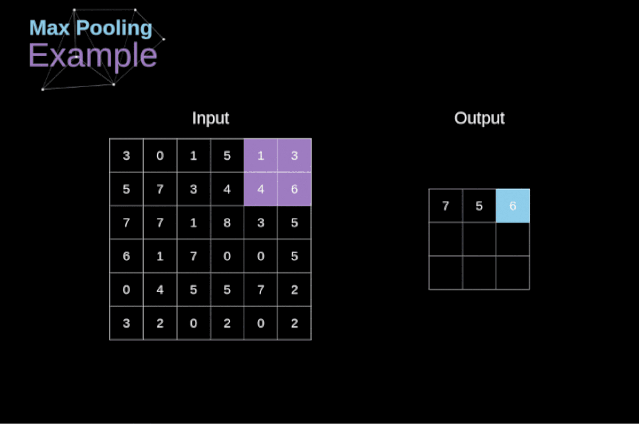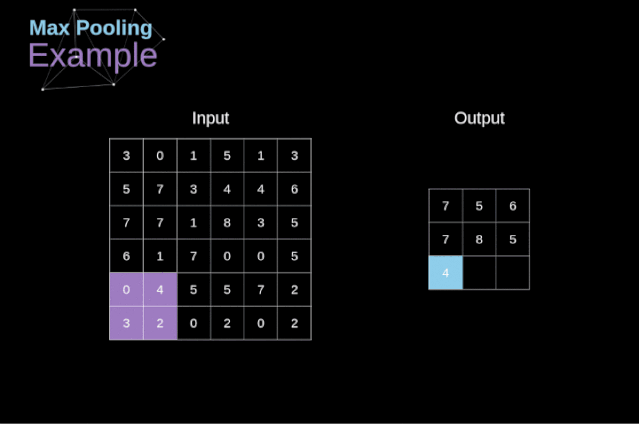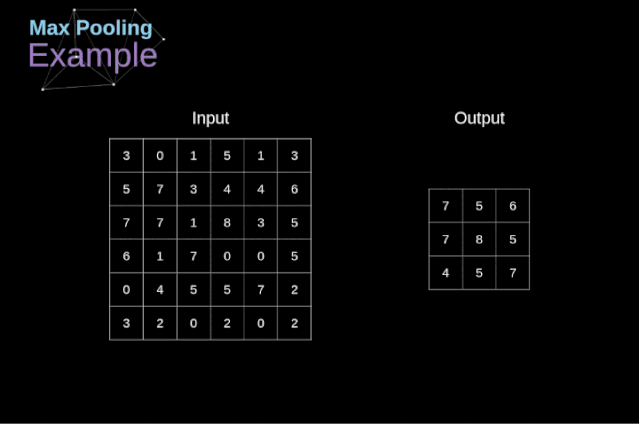

评论

点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
原标题 | Gentle Dive into Math Behind Convolutional Neural Networks
翻 译 | 通夜(中山大学)、had_in(电子科技大学) 来源 | 图灵人工智能