
聊一聊 JIT 即时编译
良心公众号
关注不迷路
JIT 编译器,全称 Just In Time Compiler,被称作即时编译器。
01
JIT 的应用背景
只看定义,并不能很清楚地了解 JIT 编译器的真实面目。这一切还要从 Java 语言的自身特点说起。
Java 语言有一个重要的特性,“一次编译,到处运行”。该特性是依赖于“字节码”这样一种中间形式来实现的。具体来说,要想运行一段 Java 程序,首先需要利用 javac 将程序编译成字节码,但由于计算机并不认识字节码,只认识机器码,因此,还需要一个被称为“解释器”的翻译官,将字节码逐条解释为机器码,从而使代码最终得以执行。
按照上面的描述,Java 程序要想被计算机成功执行,就必须先经过编译和解释这两个步骤,因此,Java 又被称为“解释型”语言。而对于 C++ 这种语言来说,C++ 程序在执行之前会直接被编译器编译成机器码,而没有字节码这样的中间状态,也就没有了解释执行这一步骤。因此,曾经流行这样一种说法,C++ 的执行效率要高于 Java。不过,也正因为没有字节码这样的中间状态,C++ 也很难像 Java 一样做到“一次编译,到处运行”。
听起来有一种“鱼与熊掌不可兼得”的意味,但其实并非如此,或者说,这其间还是有优化空间的。而 JVM 在这方面的探索,就是引入了本文要讲述的 JIT 编译器。
02
JIT 的基本思路
JIT 编译器的基本思路是这样的,既然解释执行太慢,那就将字节码进一步编译成适用于本地计算机的机器码。按照这种思路,就可以既保证平台无关性,又能进一步提升效率。进一步考虑,将字节码编译成机器码也是需要时间的,因此,如果某些指令执行的频率相当低,此时编译成机器码对系统效率的提升可以说是收效甚微,甚至是负收益,此时就可以继续保持解释执行的方式,而对于那些执行频率较高的指令,编译成机器码的收益自然就十分明显了。
可以用下图来大致描述 JVM 中引入 JIT 的基本思路。
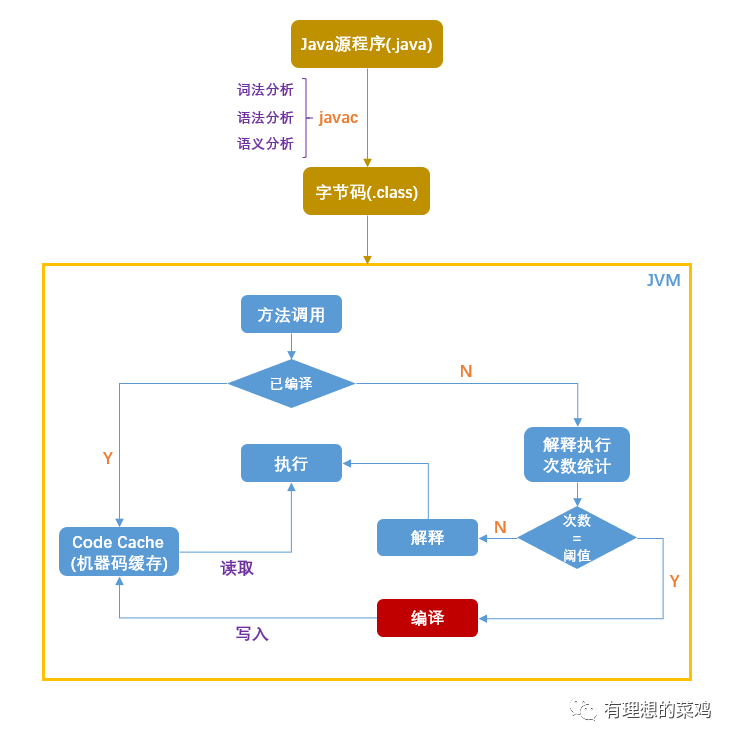
图中红色方块中的编译,其实就是文章开头提到的 JIT 编译器在发挥作用。
03
两大类 JIT 编译器
进一步来看,JVM 集成了两类编译器,分别称之为 Client Compiler 和 Server Compiler。它们的主要特点如下:
Client Compiler 注重启动速度和局部的可靠的优化。该类编译器是 GUI 应用程序的理想选择。
Server Compiler 注重全局优化,优化方式更加激进,因此,在一般情况下,它的整体性能会更好,但不可避免地是,全局优化需要进行更多的全局分析,这会导致启动速度变慢。该类编译器是长期运行的服务器端应用程序的理想选择。
可以看到,两类编译器有着不同的应用场景,在虚拟机中共同发挥作用。
以 HotSpot 虚拟机为例,它的 Client Compiler 被称作 C1 编译器,而 Server Compiler 主要有两种:C2 编译器和自 JDK10 开始引入的 Graal 编译器 (实验性)。
C1 编译器
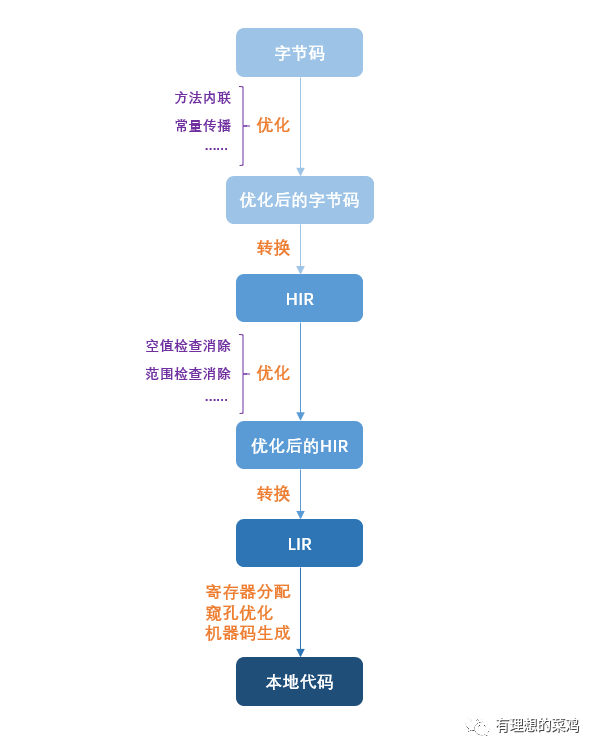
C1 编译器主要做以下工作:
对字节码进行基础优化,包括方法内联、常量传播等。
将字节码构造成一种与目标机器指令集无关的高级中间代码表示 (HIR),并对其进行一些优化,包括空值检查消除、范围检查消除等。
从 HIR 中产生与目标机器指令集相关的低级中间代码表示 (LIR),并在 LIR 的基础上进行寄存器分配、窥孔优化等操作,最终生成机器码。
对于 C1 编译器的大致工作流程可以用下图进行表示:
C2 编译器
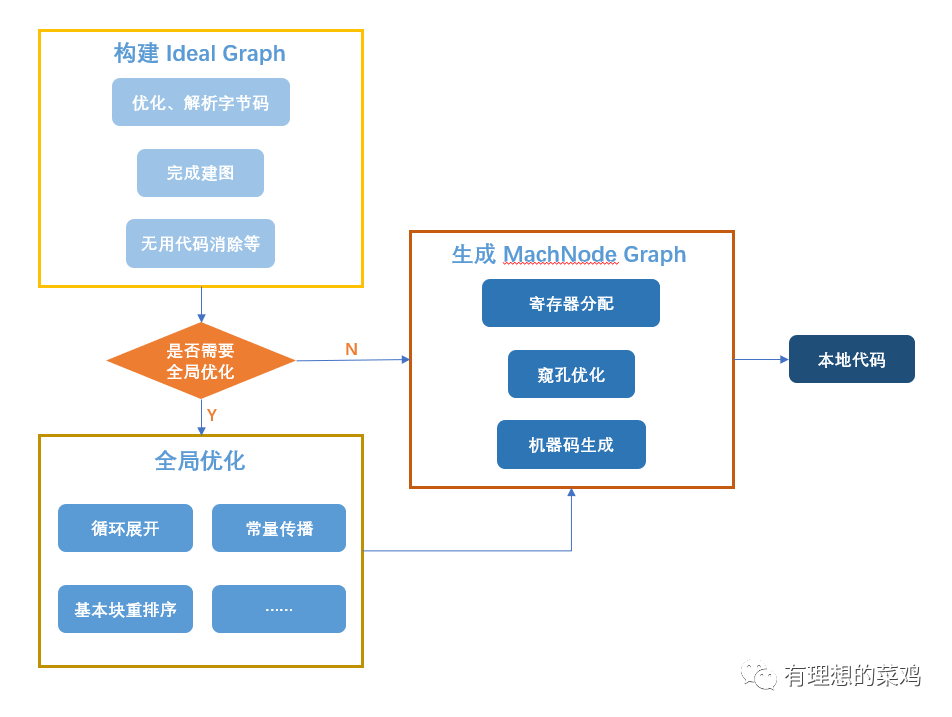
C2 编译器主要做以下工作:
对字节码进行解析,构建一种被称作 Ideal Graph 的图数据结构,用来表示程序的数据流向和指令之间的依赖关系。在解析字节码的过程中,JVM 会进行指令优化,包括 Global Value Numbering、常量折叠等,解析成功之后,会做一些包括死代码剔除等在内的优化工作。
JVM 判断是否需要进行全局优化,如果需要则进行全局优化,否则跳过。
生成 MachNode Graph,进行寄存器分配、窥孔优化等操作,并最终生成机器码。
对于 C2 编译器的大致工作流程可以用下图进行表示:
Graal 编译器
Graal 编译器是自 JDK10 开始引入的一种较新的 Server Compiler,目前仍处于实验阶段。同 C2 相比,它主要有以下特点:
对 JDK8 以来支持的 Lambda 和 Stream 等新特性更加友好。
优化更加激进,峰值性能更高。
支持逃逸分析等更加深层次的优化。
04
分层编译
不仅如此,JDK7 引入了分层编译的概念,综合了 C1 的启动性能优势和 C2 的峰值性能优势。
分层编译将 JVM 的执行状态分为了五个层次。分别为:
解释执行;
执行不带 profiling 的 C1 代码;
执行仅带方法调用次数以及循环回边执行次数 profiling 的 C1 代码;
执行带所有 profiling 的 C1 代码;
执行 C2 代码。
如下图所示:
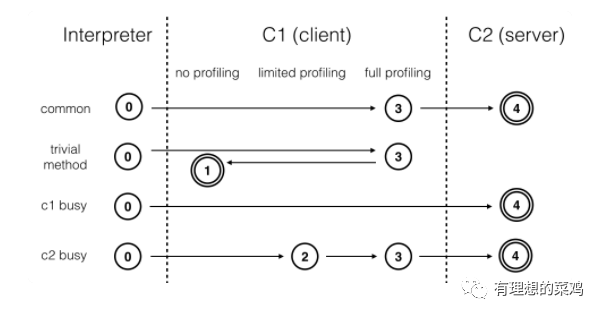
通常情况下,C2 代码的执行效率要比 C1 代码的高 30% 以上。而对于 C1 代码的三层来说,执行效率是递减的。这是因为 profiling 越多,额外的性能开销越大。
另外,可以看到,第 1 层和第 4 层处于终止状态。当一个方法被终止状态编译过后,在编译后的代码没有失效的前提下,JVM 不会再次发出该方法的编译请求。
本文关于 JIT 即时编译的基本知识总结就到这里了,文章部分内容参考自《深入理解Java虚拟机》,其中还有很多优化细节值得深挖,继续探索吧。
欢迎关注【有理想的菜鸡】公众号,大家一起讨论技术,共同成长!

学习 | 工作 | 分享
👆长按关注“有理想的菜鸡”
只有你想不到,没有你学不到