
分库分表的常见问题和示例
分库分表
网上分库分表的资料很多,这里主要是重新整理和梳理一下。如有和其他文章类似片段或解决方案,纯属前人总结或者业内标准。
为什么要分表分库分表分库一般会在以下情况下出现:
一、数据库本身的性能瓶颈
单机数据库的存储容量限制
单机数据库的连接数限制
单张表的性能瓶颈
单张表性能瓶颈;
单个数据库性能瓶颈;
二、特殊场景需求
SasS 特定场景下的数据隔离需要;
数据库瓶颈
不管是 IO 瓶颈,还是 CPU 瓶颈,最终都会导致数据库的查询缓慢甚至无法查询。进而导致业务服务的难以提高并发量、吞吐量。数据库瓶颈也会导致查询缓慢、大量的超时情况进而导致程序无法使用或者崩溃的情况
IO 瓶颈
第一种:磁盘读 IO 瓶颈,数据太多,数据库缓存放不下,每次查询时会产生大量的 IO,降低查询速度 -> 分库和垂直分表
第二种:网络 IO 瓶颈,请求的数据太多,网络带宽不够 -> 分库
CPU 瓶颈
第一种:SQL 问题,如 SQL 中包含 join,group by,order by,非索引字段条件查询等,增加 CPU 运算的操作 -> SQL 优化,建立合适的索引,在业务 Service 层进行业务计算。
第二种:单表数据量太大,查询时扫描的行太多,SQL 效率低,CPU 率先出现瓶颈 -> 水平分表。
网上也流传着一些更通俗具体的说法比如:当单表的数据量达到1000W或100G以后。更通俗的说话就是数据库已经无法满足性能需求了。至于什么情况不能满足性能需求,还是要根据具体的场景来确定的,并没有什么金科玉律。
特殊场景需求
这个就没有办法了,直接接受吧 😏🤣😂😅😢😥😪😓😰😭
分表分库前我们可以做哪些尝试里面涉及的具体实现以 Java 为主,其他语言使用者自行脑补
数据库本身的性能瓶颈是无法避免,但我们可以想法减轻数据库的压力,减轻数据库瓶颈本身带来的影响。
缓存
缓存可以称的上提供性能减少数据库查询的一个万金油方案,其虽然不能完美的,但一定是最先想到的。
一般可以使用进程内缓存和分布式缓存两种方案相结合的方案。对于一致性要求不高,甚至允许一定时间内可以有数据差异的功能,可以直接采用进程内缓存来实现,这种方案更高效,不过其和程序本身占用同一个进程,需要考虑进程内缓存的容量问题,具体方案可以使用 Google Guava、Caffeine 以及 Spring Cache 等;如果对于一致性要求高,并且不想缓存占用更多的进程内存,则可以使用分布式缓存,其通过一个高性能外部的 Server 来存储一些需要缓存的数据,服务通过网络通信来获取外部 Server 的缓存数据,其增加了一部分网络开销,但不用再占用业务服务的进程内存。
| 方案对比 | 进程内缓存(本地缓存) | 分布式缓存 |
|---|---|---|
| 容量对比 | 缓存数据和服务进程共用内存,受单机内存限制 | 缓存数据单独在高性能服务上,与服务进行无关,其受具体的高性能服务器限制。可以通过集群的方式提高容量 |
| 性能对比 | 本地进程内存查找,性能高效 | 存在网络开销,受网络环境的影响 |
| 具体技术方案 | Map、Ehcache、Google Guava、Caffeine 以及 Spring Cache 等 | Memcached、Redis、Spring Cache |
| 空间损耗 | 损耗大,因为缓存数据和服务进程内存一起存储,无法共享。则每个服务进行都会有一份,可能包换多份重复数据。 | 损耗小 |
数据库读写分离
读写分离也是一种有效降低数据库压力的方案,通过数据库主从结构,主节点负责读写,从节点负责读。这样我们可以通过将一些读请求分散到从节点,来减轻主节点的压力。比如一些报表、分析、统计的功能模块只允许其访问从库,可以在一定的条件下提升整体性能
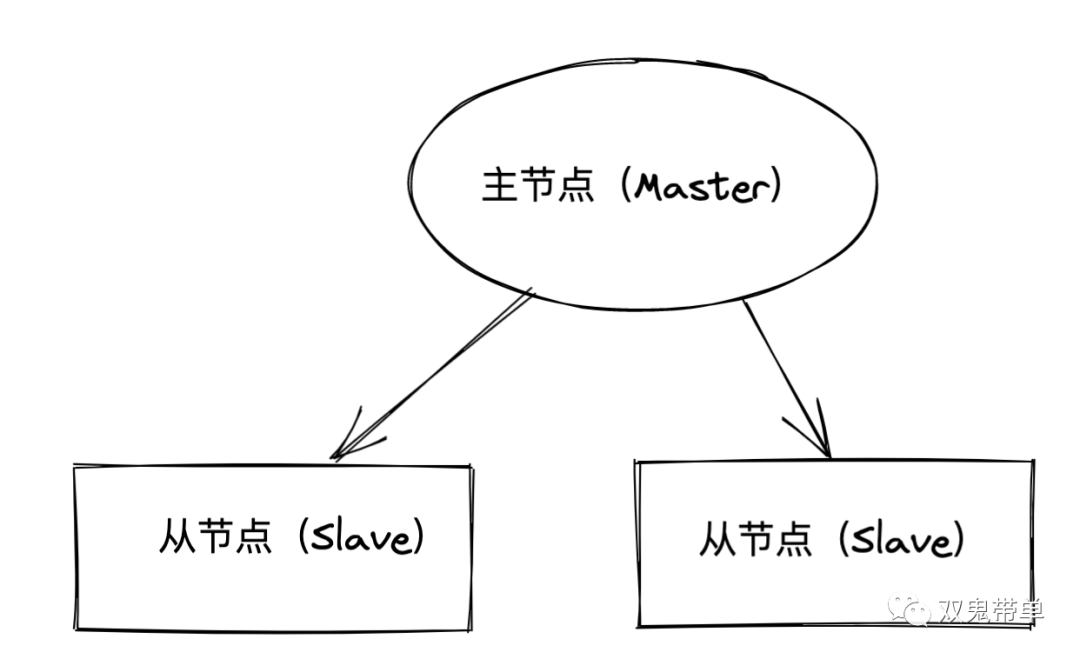 image-20211113220904299
image-20211113220904299关于一些常见的数据库架构的模式,这里不在叙述,这和本文无关,具体模式以后可能会再写一篇进行补充。
优化数据库结构和查询语句
对一些查询条件加索引
对一个表中不经常被查询的数据切割到一个子表中,保证主表的查询性能
适当的优化表结构等等
当然 SQL 优化不是本文的重点,但这也是一个优化的方向,好的 SQL 和表结构对应性能还是有很大影响的。
其他混合方案
我们也可以通过混合其他存储方案来减轻数据库的压力,比如 MongoDB、ElasticSearch。通过混合使用一些更高性能的技术方案来提高整体性能。
分表分库的常见方案和局限性既然到了这里,那么肯定就要分库分表,我第一次接触分表的时候是 16 年大三的时候,到现在已有 4 年多,但记忆犹新。接下来简单的说一下当时的情况。
第一次分表的经历
当时还在上大三,当时有个一个项目,里面有个 2 个模块,一个是订单,一个是用户的操作记录,这两个都是数据量比较大的模块,因为订单的实时性比较高,无法做缓存处理,用户的操作记录数据量比较大,做缓存也没有太大的必要,同时公司采用的云数据库,还算比较贵,又因为其他表的数据量都比较小,没必要为了这两个大表来增加数据库,这里就考虑了直接不增加数据库实例的情况下,只做分表操作。
针对用户操作记录的处理
用户操作记录是记录用户在我们项目中的一系列行为,本身不能在通过拆分子表的形式降低表的大小,这里使用水平分表。根据查询情况,用户一般是查询最近几天的记录,对几个月前的历史记录很少查询,所以这里按月份对日志表进行水平拆分。
原数据表名称:user_action_record_log
新数据表名称:user_action_record_log_201607、user_action_record_log_201608、user_action_record_log_201609、user_action_record_log_201610 …
将行为日志按月份拆分,表名增加对应的月份后缀
对插入的影响: 插入数据时,需要根据时间动态拼接表名
对查询的影响: 因为按照时间进行拆分,在查询的时候需要要求用户指定时间段,当然这个本身影响不大,如果用户不选择时间,则默认只查当前月,各种情况如下:
用户不输入时间段,默认只查当前月,通过时间计算得到当前月的表名进行查询,例如:
select * from user_action_record_log_201610用户输入了时间段,则计算时间段跨过的具体的月列表,然后通过
union all进行连接查询,例如select * from user_action_record_log_201609 union all select * from user_action_record_log_201610,当然月份跨度越大 union 越多.
通过这种方式将一个大表,按月份变成了多个小表。
针对订单表的处理
订单表本身字段还是挺多的,包含买家信息、卖家信息、商品信息等,在做查询时,有很多字段既不进行显示又不参与查询条件,这样可以先进行垂直拆分,将订单表这个大表拆分成一个主表一个子表,主表负责存储一个主要的既参与查询又参与大部分业务展示逻辑的字段,子表负责存储大部分业务都不需要用到的字段,一般只有点到详情也才需要的数据。
原数据表名称:order
新数据库名称:order_pri, order_sub
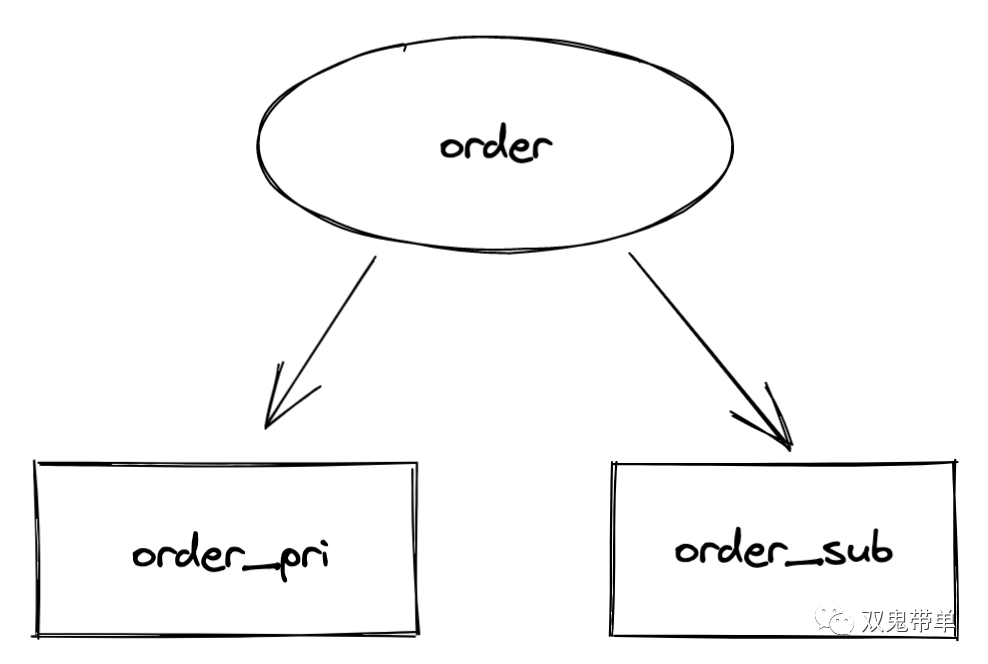 image-20211113232738118
image-20211113232738118这样大部分查询可以通过 select * from order_pri where ... 来完成,小部分通过 select op.*, os.* from order_pri op join order_sub os on os.parent_id = op.id where ... 来完成,这样系统也稳定运行了一段时间。因为订单表本身增长还是挺快的,这种方案过了一段时间就不行了。这时候想了一下能不能使用日志的方案呢,因为商家更多关注的是近期的订单,而不是历史的订单,再对这里面进行水平分表,按照创建时间分!说干就干。
原数据表名称:order_pri, order_sub
新数据库名称:order_pri_201607, order_pri_201608, order_sub_201607, order_sub_201608
对插入的影响: 插入数据时,需要根据时间动态拼接表名
对查询的影响: 因为按照创建时间进行拆分,在查询的时候需要要求用户指定时间段,当然这个本身影响不大,如果用户不选择时间,则默认只查当前月,各种情况如下:
用户不输入时间段,默认只查当前月,通过时间计算得到当前月的表名进行查询,例如:
select * from order_pri_201608用户输入了时间段,则计算时间段跨过的具体的月列表,然后通过
union all进行连接查询,例如select * from order_pri_201608 union all select * from order_pri_201609,当然月份跨度越大 union 越多.
通过这种方式将一个大表,按月份变成了多个小表。
对修改的影响:前端在修改某条记录时既要传入id, 又要传入这个订单的创建时间,主要为了定位到是哪个月份的表,当然也可以做个映射表来解决这个问题,我们没做
这样的系统其实已经可以使用了,查询的速度也提高了很多,基本上可以很好的运行了。难道这就完了,可不是这样的,我们可是一个精益求精的团队。
首先看一下订单的状态和各种状态的含义:
订单状态主要有待付款、待发货、待收货、待评价、已关闭、以及退款中。
待付款:代表买家下单了但是还没有付款;
待发货:代表买家付款了卖家还没有发货;
已发货(同待收货):代表卖家已经发货并寄出商品了;
已完成(同待评价):代表买家已经确认收到货了;
已关闭:代表订单过期了买家也没付款、或者卖家关闭了订单;
退款中:代表用户已申请退款。
因为我们做的是阿里巴巴的第三方应用,所以我们的订单结构和阿里巴巴的惊人的相似,我们项目主要服务于阿里巴巴上的商家而不是用户,在我们的系统中商家更关心的是待付款、待发货的订单,待付款的需要进行催单、待发货的需要商家赶紧发货、其余状态的订单更多的是做统计,而不是实时操作,针对我们的这种业务场景,我们发现如果根据订单的状态进行分表而不是根据创建时间分表,似乎更加的合理,同时我们将系统的功能进行优化,将非 待付款、待发货 的订单单独做个页面专门做数据查询,对 待付款、待发货 的订单进行优化处理,因为这种状态的订单一般很快就会被商家处理,变成其他状态,这样这种状态的数据本身就不多,更适合实时查询,对非待付款、待发货状态的订单进行月份切割,保证热点数据的查询简便,有保证非热点数据的查询快速,这样做显然更好。
首先将待付款、待发货、待收货、待评价、已关闭、以及退款中分为 3 组大状态
| 大分类 | 未完成(uncompleted) | 已完成(completed) | 退款(refund) |
|---|---|---|---|
| 包含小分类 | 待付款、待发货、待收货 | 待收货、待评价、已关闭 | 退款中 |
| 数据量 | 最多 7 天内数据,量小 | 所有的数据,量大 | 退款本身概率小,量小 |
根据业务情况未完成分类的数据比较少,一般为 7 天内数据,不需要进一步拆分;已完成分类的数据较多,需要进一步拆分,这里继续根据月份进行拆分;退款分类的数据也比较少,大部分用户都不会退款,不需要进一步拆分。
根据情况最终的分表情况如下:
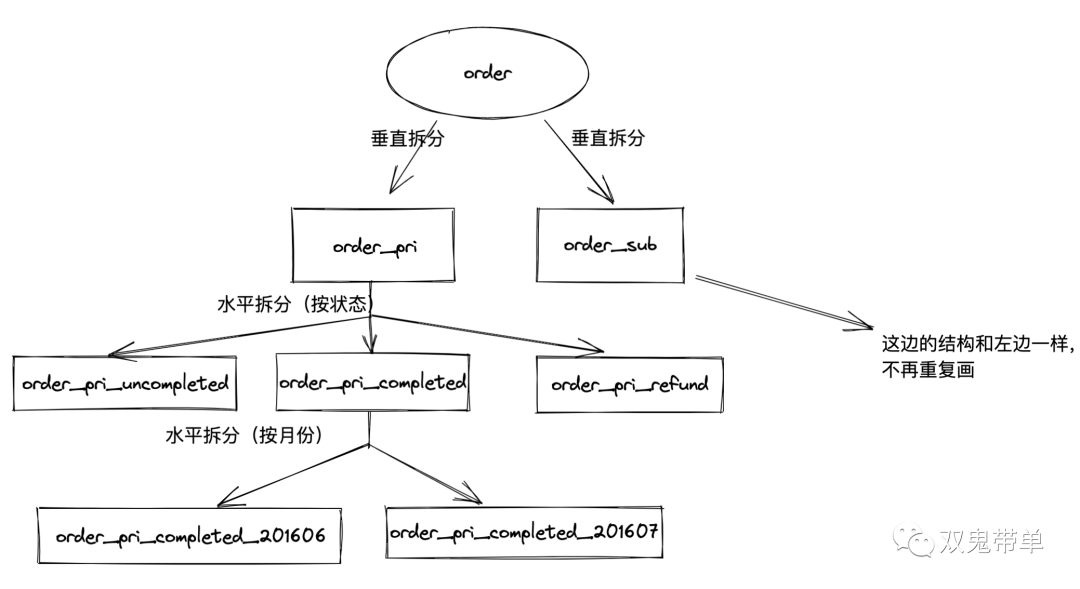 image-20211114001909316
image-20211114001909316最终需要根据不同的状态使用不同的查询方式,因为热点数据都在 order_pri_uncompleted 表中,则可以使用正常的查询语句,同时因为量相对少,也不会产生瓶颈;对于所有的数据已完成(completed)因为本身量大,还需跨表查询。通过不同状态,不同月份的控制最终达到了对于业务来说相对优化的方案。
在上面的表拆分中也需要注意以下几种情况:
id 的生成,需要考虑一下数据表自增 id 在跨表查询时是否存在重复的情况,根据情况考虑全局 id 方案
拆分的表是否适合查询,毕竟我们拆分主要就是为了查询
拆分前后性能的对比
拆分后的 SQL 更加复杂了,对于统计分析来说,是否需要引入新的的技术
常见的几种概念
水平分表
以字段为依据,按照一定策略(hash、range 等),将一个表中的数据拆分到多个表中。
在这种分表策略中:
每个表的结构都一样;
每个表的数据都不一样,没有交集;
所有表的并集是全量数据;
所有的数据还在同一个数据库实例中。
在上面的例子中,将 user_action_record_log 按照月份进行拆分就属于水平分表。
垂直分表
以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
在这种分表策略中:
每个表的结构都不一样;
每个表的数据也不一样,扩展表保存主表的一个唯一标识,用于关联数据;
所有表的并集是全量数据;
所有的数据还在同一个数据库实例中。
在上面的例子中,将 order 表分为 order_pri, order_sub 就属于垂直分表
分表是针对于单个数据库实例还没到瓶颈的情况下,只是单表因为数据量大已经达到瓶颈
水平分库
以字段为依据,按照一定策略(hash、range 等),将一个表中的数据拆分到多个表中。
在这种拆分策略中:
每个库的结构都一样;
每个库的数据都不一样,没有交集;
所有库的并集是全量数据;
这个是看上去和水平分表很像,只不过是通过策略分到了不同的库。
垂直分库
以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
在这种拆分策略中:
每个库的结构都不一样;
每个库的数据也不一样,没有交集;
所有库的并集是全量数据;
在分库是一个比较麻烦的操作,因为分库会导致事务处理麻烦、跨库聚合数据麻烦、无法跨库 join 问题,在选择分库策略的时候一定要考虑实际需要。如果可以分表解决的,那就先尝试分表,而不是直接分库。当然如果不需要考虑事务、join 等问题,选什么方案都是可以的。
分区步骤
预估容量:这里的容量包括当前容量和可能的增长量;
评估分区个数:根据预估的容量来确定分区的个数是多少合适;
确定分区键 partition key:在确定分区键的时候,既要考虑能够均匀的散落到不同的表中,也要考虑适合查询和修改;
分表规则:一般可以通过对分区键进行 hash 或者 range 来确定归属哪个分区,也可以直接做个固定情况的分区规则,比如上面订单例子中,直接使用状态进行分片;
扩容计划:不管怎么评估容量和分区个数,都有一定的概率再次出现瓶颈,也要考虑一下再次出现瓶颈的时候,如何进行扩容。如果可以停机清洗数据的话,这方便也可以不考虑,或者少考虑,对于不能停机清洗数据的业务,需要多考虑一下;
分区键的选取和方法示例
唯一 ID
最简单的方法是对唯一id 进行 hash 取模计算,比如我们要分 2 个表,就可以直接 hash(id) % 2, 这样就可以把数据分成 2 份。
建议:使用这种取模的方式,推荐将表分为 2 的次方个,方便后续的扩容
查询和修改都可以通过 hash 取模的方法查到对应的表或者库。
扩容方式:
比如计划分 2 个表,但因为后续数量激增,2 个表不在满足,可以直接将分区个数翻倍,变成 4 个表,则现在逻辑为 hash(id) % 4, 从图中可以看出如果分区数是 2 的次方,则每次扩容,只需要对上一次表在进行对应 hash 取模,就能再次平均分配,在重新分配的过程中,冗余的数据为 1/2
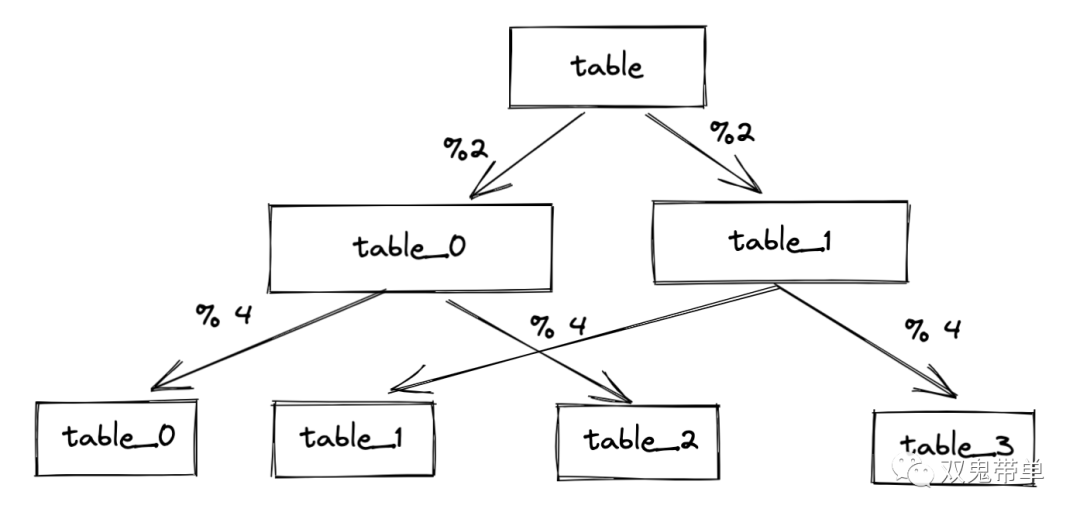 image-20211114121623328
image-20211114121623328时间分表
根据某个时间段来分表也是一种可行的方案,时间分表不存在扩容时需要清洗数据的问题,但是需要每隔一段时间增加一个分区
使用固定的路由表
可以制定一个固定的路由表进行分区
比如手机号可以根据前 3 位分表,这种每个表最大量为 1 亿
身份证号可以根据前 6 位划分区域存储
订单可以根据不同的状态
不管使用何种方式去分库分表,数据如何归档、数据归档后如何保证用户能查询到、如何保证一致性等等都需要去考虑解决。
ID 问题
因为将数据切分到了不同的表和库中,MySQL 本身的自增 id 就不能保证唯一性了,这时候需要其他方案来保证。
UUID
数据库自增 ID
雪花算法
美团 Leaf
百度 uid-generator
方案很多,自行参考,保证唯一即可
分布式事务
将数据拆分到不同的数据库实例的情况,就会出现分布式事务问题,分布式事务的出现也会影响性能。常见的分布式事务的方案有:
数据库本身的 XA 协议
TCC 事务
2PC/3PC 方案
最终一致性性方案
其中可以使用 Alibaba Seata 等
跨节点查询问题
join 问题
跨数据库节点 join 本身就比较麻烦,甚至不支持,可以通过冗余数据的方式来减少和避免 join 的情况,或者通过业务逻辑来进行join 操作而不是数据库 join
排序和分页
因为数据本身分布在不同的节点上,所有的节点数据才是全集,对数据进行排序和分页也是一个难点问题,数据量少的情况下可以进行业务服务进行内存分页,数据量大的时候就没办法使用了。
统计函数
一些数据难以统计,可能需要其他的三方统计方式,或者通过一些分析引擎来做。
min
max
sum
count
concat
非分片键上的查询
因为数据分区是根据分片键来区分的,如果查询条件中存在分片键则很容易的定位到指定的分片,如果查询条件中不存在分片的键,就需要其他方式查询:
查询所有的数据:这个方案本身就不可取,一是查询缓慢,二是分区数量变化还得更新对应的 SQL
做个映射表:将可能用到的查询条件单独在存一个映射表中,对应上分区,查询通过这个映射表先查到分区,在去指定分区查具体的数据,这种方案适用于查询条件字段只占用总字段的很小一部分的情况下,如果占用一大部分,那映射表本身就会很大。映射表不一定非要存在数据库中,也可以进行混合存储,比如 MongoDB
数据迁移和扩容
上面的例子中也有提到,如果预估的分区不够的情况,还要进行扩容操作,方案中也要将这部分考虑进去。
支持分库分表中间件目前分库分表一些成熟的开源解决方案:
Apache Shardingsphere
Alibaba Cobar 仅供参考
MyCAT(Base Cobar)
58同城 Oceanus 仅供参考
Google Vitess