Kafka 原理,不就这么回事嘛
在看|星标|留言, 真爱

作者:臧远慧
原文链接:https://juejin.im/post/5e217c3fe51d450200787f23

解耦:允许我们独立的扩展或修改队列两边的处理过程。
可恢复性:即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
缓冲:有助于解决生产消息和消费消息的处理速度不一致的情况。
灵活性&峰值处理能力:不会因为突发的超负荷的请求而完全崩溃,消息队列能够使关键组件顶住突发的访问压力。
异步通信:消息队列允许用户把消息放入队列但不立即处理它。
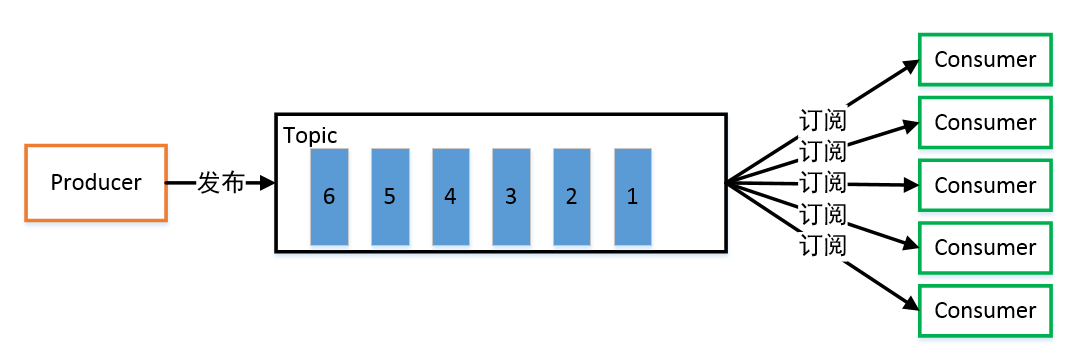
Producer:消息生产者,向 Kafka Broker 发消息的客户端。
Consumer:消息消费者,从 Kafka Broker 取消息的客户端。
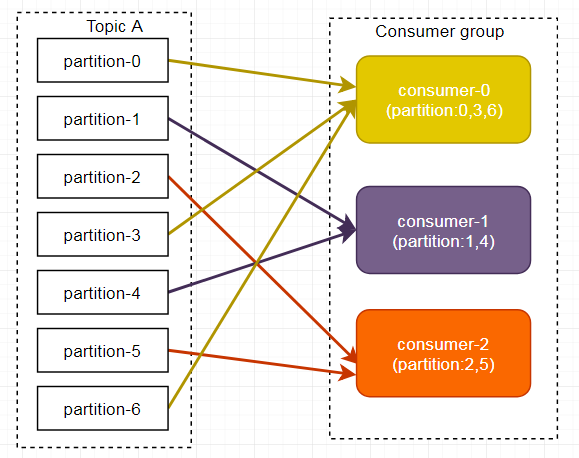
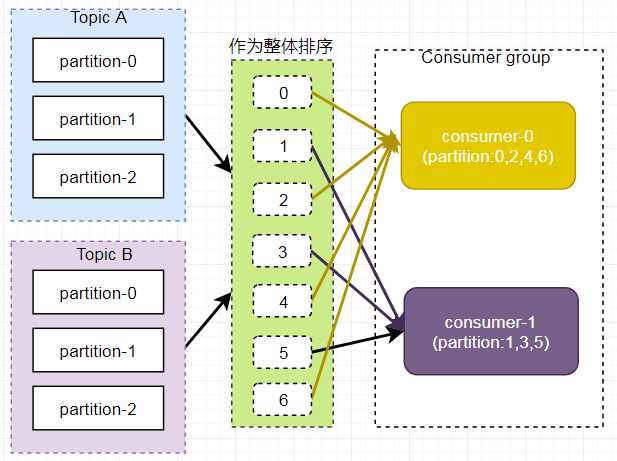
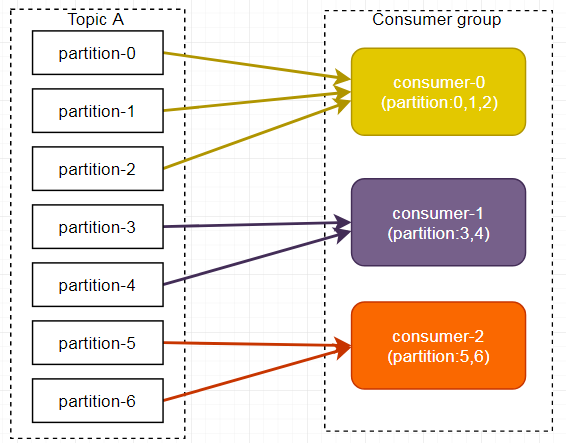
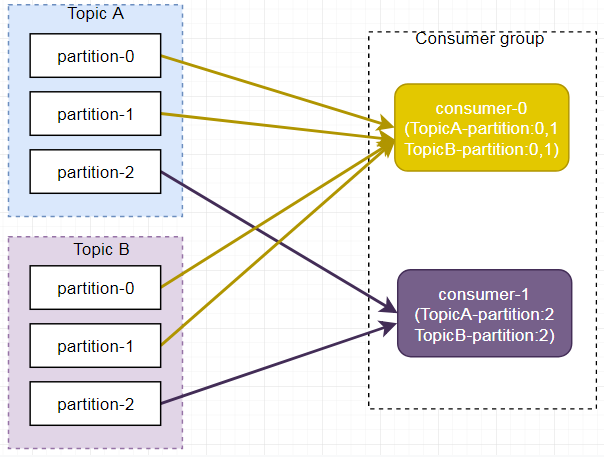
Consumer Group:消费者组(CG),消费者组内每个消费者负责消费不同分区的数据,提高消费能力。一个分区只能由组内一个消费者消费,消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
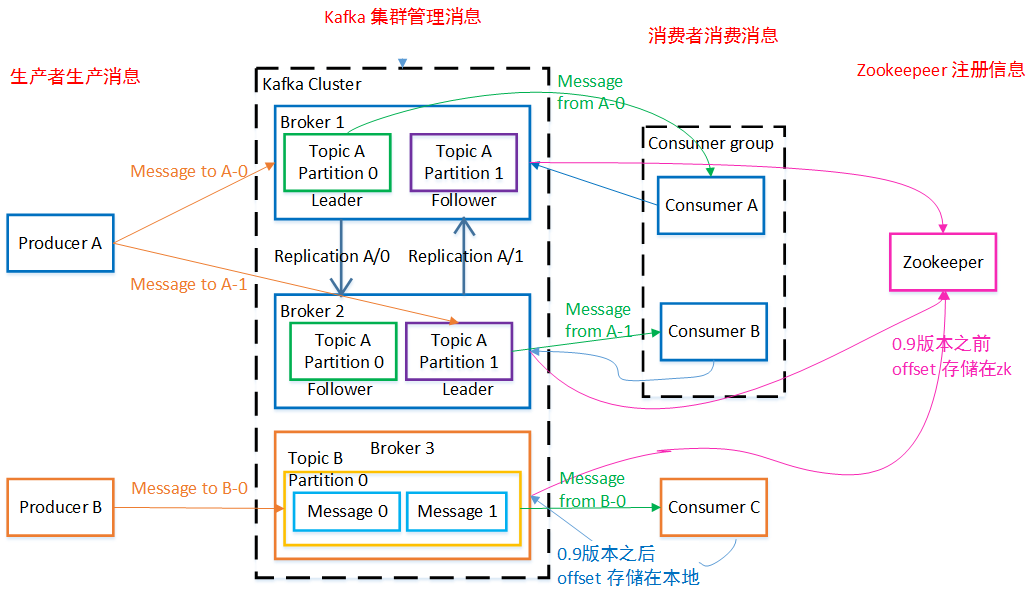
Broker:一台 Kafka 机器就是一个 Broker。一个集群由多个 Broker 组成。一个 Broker 可以容纳多个 Topic。
Topic:可以理解为一个队列,Topic 将消息分类,生产者和消费者面向的是同一个 Topic。
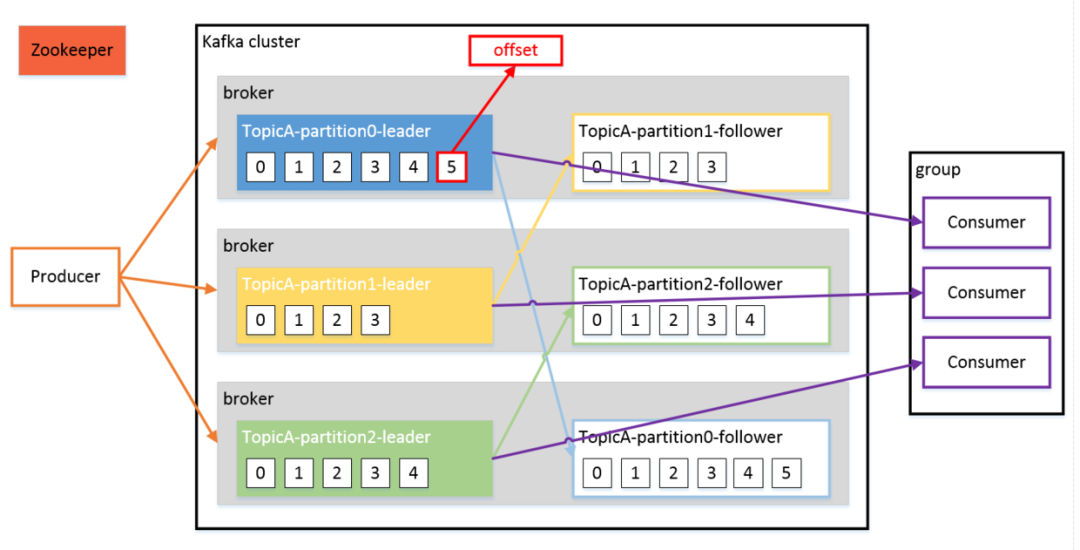
Partition:为了实现扩展性,提高并发能力,一个非常大的 Topic 可以分布到多个 Broker (即服务器)上,一个 Topic 可以分为多个 Partition,每个 Partition 是一个 有序的队列。
Replica:副本,为实现备份的功能,保证集群中的某个节点发生故障时,该节点上的 Partition 数据不丢失,且 Kafka 仍然能够继续工作,Kafka 提供了副本机制,一个 Topic 的每个分区都有若干个副本,一个 Leader 和若干个 Follower。
Leader:每个分区多个副本的“主”副本,生产者发送数据的对象,以及消费者消费数据的对象,都是 Leader。
Follower:每个分区多个副本的“从”副本,实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发生故障时,某个 Follower 还会成为新的 Leader。
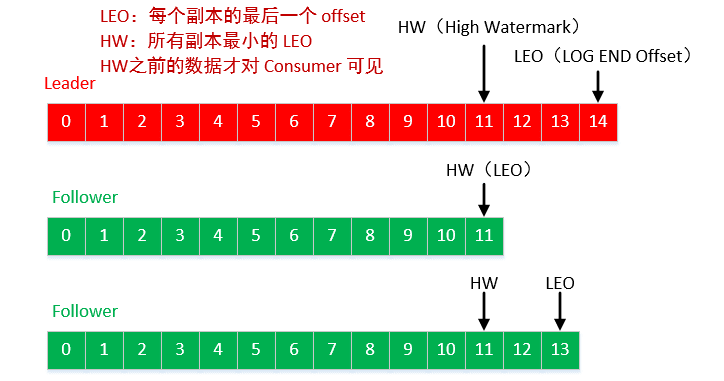
Offset:消费者消费的位置信息,监控数据消费到什么位置,当消费者挂掉再重新恢复的时候,可以从消费位置继续消费。
ZooKeeper:Kafka 集群能够正常工作,需要依赖于 ZooKeeper,ZooKeeper 帮助 Kafka 存储和管理集群信息。
发布和订阅记录流,类似于消息队列或企业消息传递系统。
以容错的持久方式存储记录流。
处理记录流。
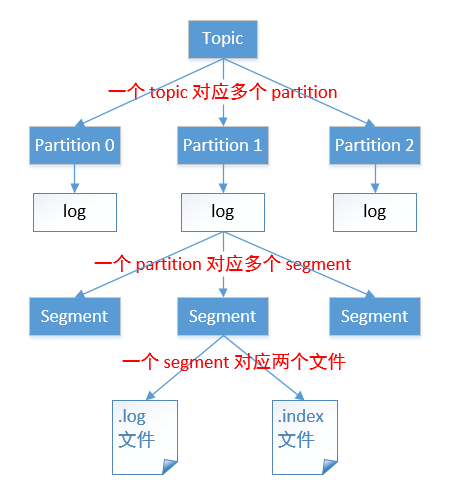
# ls /root/data/kafka/first-0
00000000000000009014.index
00000000000000009014.log
00000000000000009014.timeindex
00000000000000009014.snapshot
leader-epoch-checkpoint
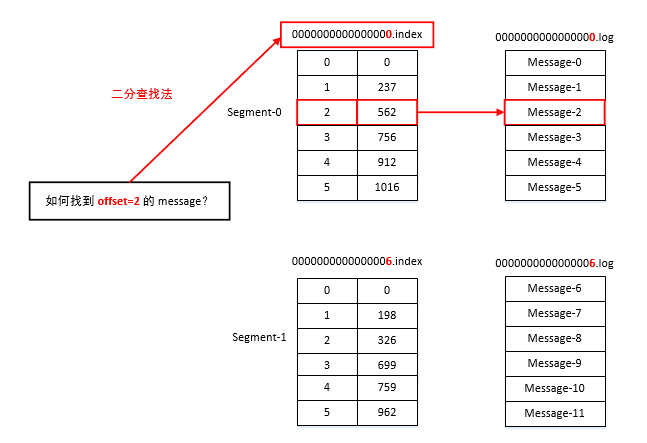
方便在集群中扩展,每个 Partition 可以通过调整以适应它所在的机器,而一个 Topic 又可以有多个 Partition 组成,因此可以以 Partition 为单位读写了。
可以提高并发,因此可以以 Partition 为单位读写了。
topic:string 类型,NotNull。
partition:int 类型,可选。
timestamp:long 类型,可选。
key:string 类型,可选。
value:string 类型,可选。
headers:array 类型,Nullable。
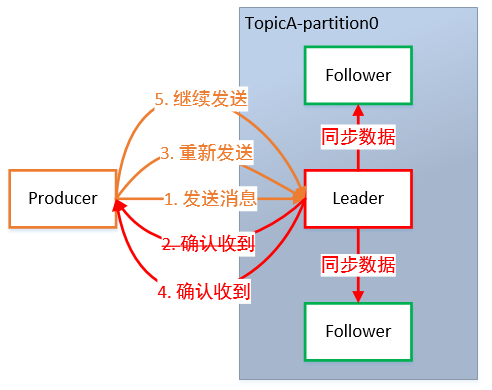
0:Producer 不等待 Broker 的 ACK,这提供了最低延迟,Broker 一收到数据还没有写入磁盘就已经返回,当 Broker 故障时有可能丢失数据。
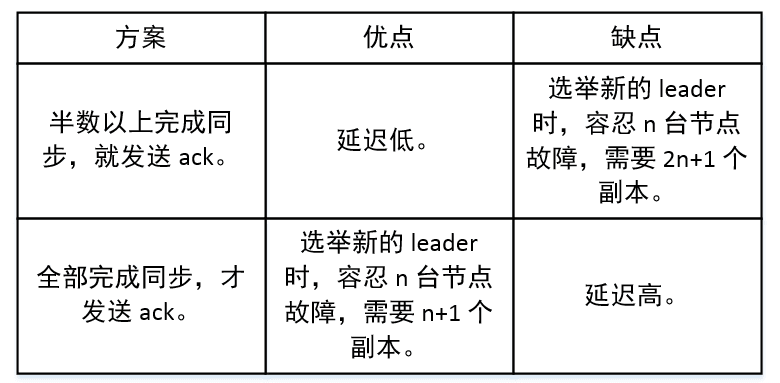
1:Producer 等待 Broker 的 ACK,Partition 的 Leader 落盘成功后返回 ACK,如果在 Follower 同步成功之前 Leader 故障,那么将会丢失数据。
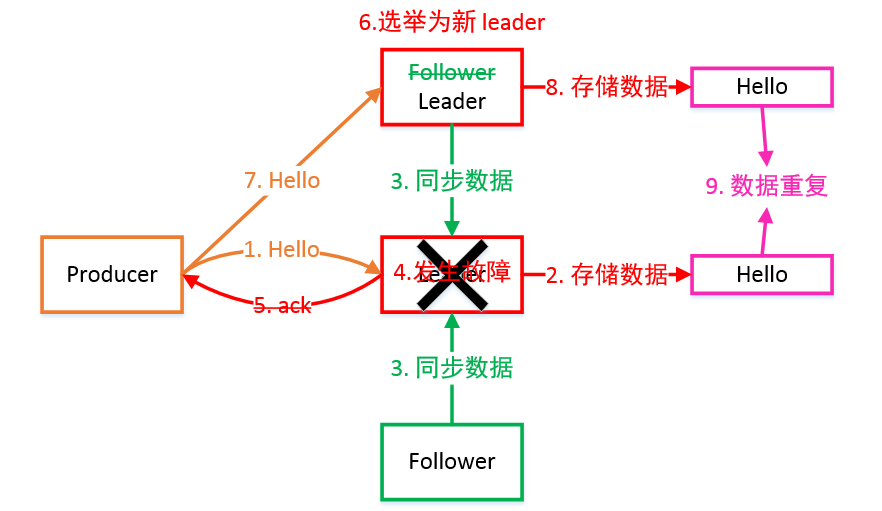
-1(all):Producer 等待 Broker 的 ACK,Partition 的 Leader 和 Follower 全部落盘成功后才返回 ACK。但是在 Broker 发送 ACK 时,Leader 发生故障,则会造成数据重复。
AtLeastOnce+ 幂等性 = ExactlyOnce
扫码加我微信进群,大厂内推和技术交流,大佬们零距离
开发者技术前线 ,汇集技术前线快讯和关注行业趋势,大厂干货,是开发者经历和成长的优秀指南。