
PyTorch 1.8炼丹:不必NVIDIA,支持AMD GPU !
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
1.8版本中,官方终于加入了对AMD ROCm的支持,可以方便的在原生环境下运行,不用去配置Docker了。
AMD ROCm只支持Linux操作系统
1.8版本集合了自2020年10月1.7发布以来的超过3000次GitHub提交。此外,本次更新还有诸多亮点:
优化代码,更新编译器
Python内函数转换
增强分布式训练
新的移动端教程与演示
新的性能检测工具
相关的库TorchCSPRNG, TorchVision, TorchText和TorchAudio也会随之更新。要注意的是,自1.6起,Pytorch新特性将分为Stable、Beta、Prototype三种版本。其中Prototype不会包含到稳定发行版中,需要从Nightly版本自行编译。
Python to Python函数转换
新增的Beta特性torch.fx可以实现Python到Python的函数转换,可以方便的加入任何工作流程。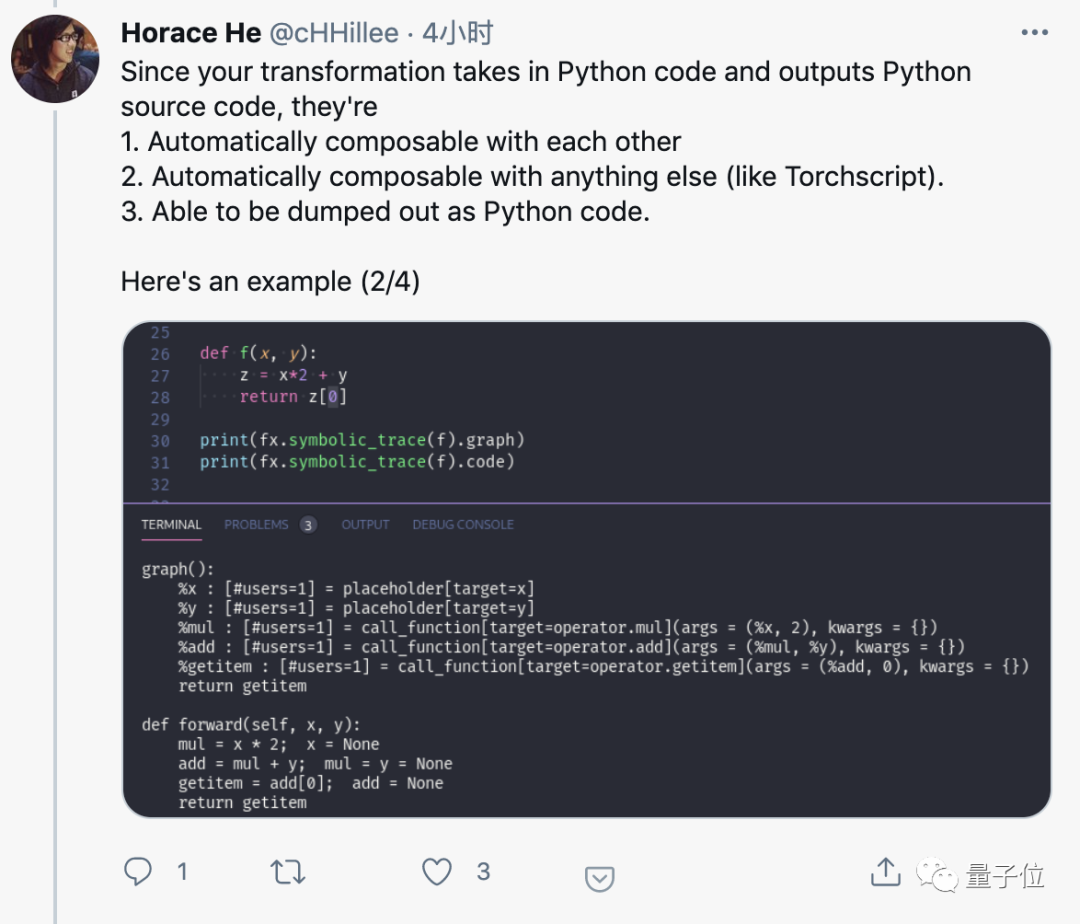
新的API,向NumPy学习!
1.7版本中增加的Beta特性torch.fft已成为正式特性。实现了与Numpy中的np.fft类似的快速傅立叶变换,还增加了硬件加速支持与自动求导,以更好的支持科学计算。还增加了Beta版NumPy风格的线性代数模块torch.linalg,支持Cholesky分解、行列式、特征值等功能。
增强分布式训练
增加了稳定的异步错误与超时处理,增加NCCL的可靠性。增加了Beta版的流水线并行功能*(Pipeline Parallelism)*,可将数据拆解成更小的块以提高并行计算效率。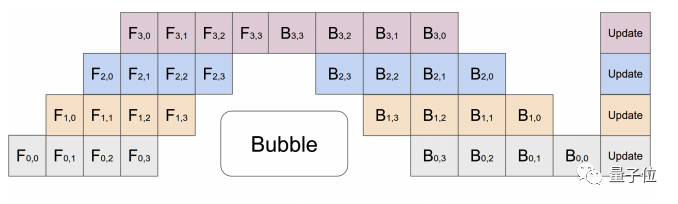
Pipeline Parallelism使用4个GPU时的工作示意图
增加Beta版的DDP通讯钩子,用于控制如何在workers之间同步梯度。
另外还有一些Prototype版的分布式训练新特性。
ZeroRedundancyOptimizer:用于减少所有参与进程的内存占用。
Process Group NCCL Send/Recv:让用户可在Python而不是C++上进行集合运算。
CUDA-support in RPC using TensorPipe:增加对N卡多卡运算的效率。
Remote Module:让用户像操作本地模块一样操作远程模块。
移动端新教程
随本次更新发布了图像分割模型DeepLabV3在安卓和IOS上的详细教程。以及图像分割、目标检测、神经机器翻译等在安卓和IOS上的演示程序,方便大家更快上手。

 另外还有PyTorch Mobile Lite Interpreter解释器,可以减少运行时文件的大小。
另外还有PyTorch Mobile Lite Interpreter解释器,可以减少运行时文件的大小。
性能检测工具
增加Beta版的Benchmark utils,用户可以进行精确的性能测试。以及Prototype版的FX Graph Mode Quantization,实现了量化过程的自动化。更多新版本详情,见下方链接👇。
参考链接:
[1]https://pytorch.org/blog/pytorch-1.8-released/
[2]https://twitter.com/cHHillee/status/1367621538791317504
猜您喜欢: