
两个使用 Pandas 读取异常数据结构 Excel 的方法,拿走不谢!
通常情况下,我们使用 Pandas 来读取 Excel 数据,可以很方便的把数据转化为 DataFrame 类型。但是现实情况往往很骨干,当我们遇到结构不是特别良好的 Excel 的时候,常规的 Pandas 读取操作就不怎么好用了,今天我们就来看两个读取非常规结构 Excel 数据的例子
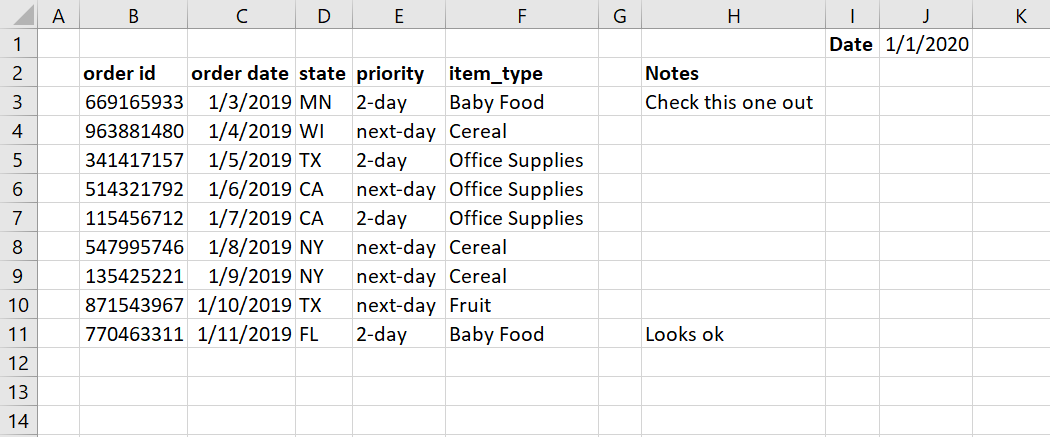
本文使用的测试 Excel 内容如下
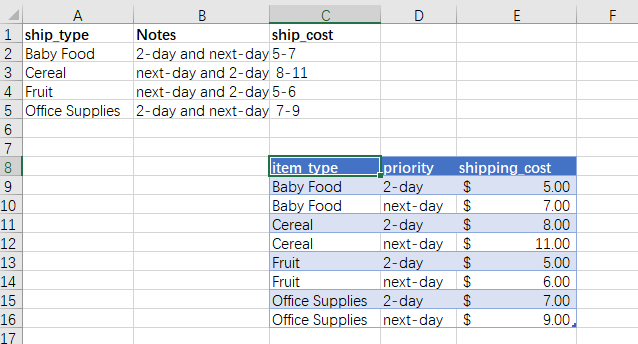
文末可以获取到该文件
指定列读取
一般情况下,我们使用 read_excel 函数读取 Excel 数据时,都是默认从第 A 列开始读取的,但是对于某些 Excel 数据,往往不是从第 A 列就有数据的,此时我们需要参数 usecols 来进行规避处理
比如上面的 Excel 数据,如果我们直接使用 read_excel(src_file) 读取,会得到如下结果
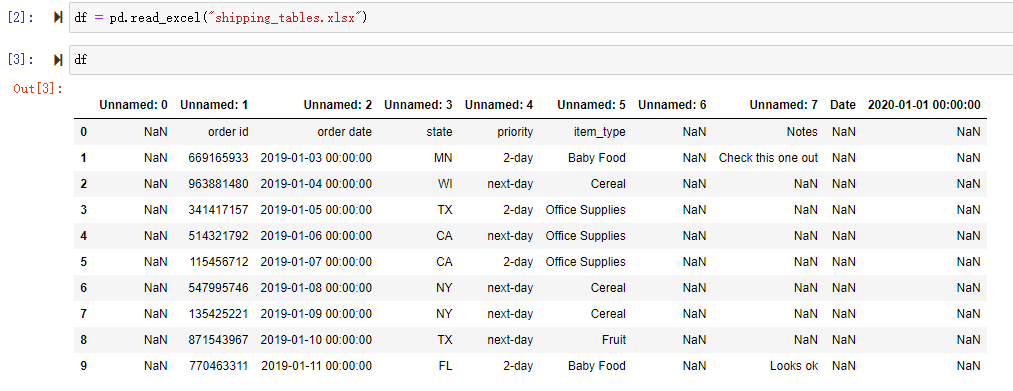
我们得到了很多未命名的列以及很多我们根本不需要的列数据
此时我们可以通过 usecols 来指定读取哪些列数据
from pathlib import Path
src_file = Path.cwd() / 'shipping_tables.xlsx'
df = pd.read_excel(src_file, header=1, usecols='B:F')
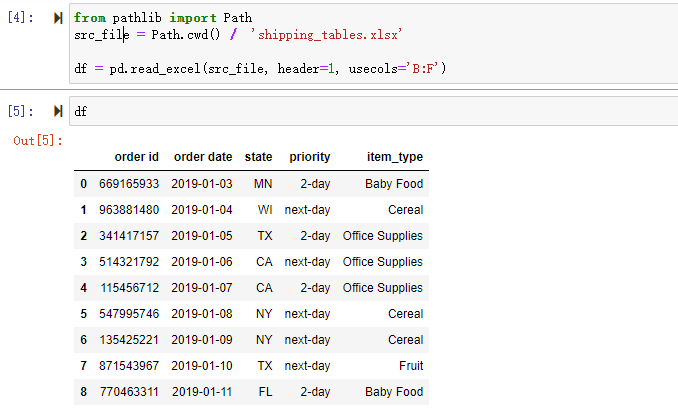
可以看到生成的 DataFrame 中只包含我们需要的数据,特意排除了 notes 列和 date 字段
usecols 可以接受一个 Excel 列的范围,例如 B:F 并仅读取这些列,header 参数需要一个定义标题列的整数,它的索引从0开始,所以我们传入 1,也就是 Excel 中的第 2 行
我们也可以将列定义为数字列表
df = pd.read_excel(src_file, header=1, usecols=[1,2,3,4,5])
也可以通过列名称来选择所需的列数据
df = pd.read_excel(
src_file,
header=1,
usecols=['item_type', 'order id', 'order date', 'state', 'priority'])
这种做法在列的顺序改变但是列的名称不变的时候非常有用
最后,usecols 还可以接受一个可调用的函数
def column_check(x):
if 'unnamed' in x.lower():
return False
if 'priority' in x.lower():
return False
if 'order' in x.lower():
return True
return True
df = pd.read_excel(src_file, header=1, usecols=column_check)
该函数将按名称解析每一列,并且必须为每一列返回 True 或 False
当然也可以使用 lambda 表达式
cols_to_use = ['item_type', 'order id', 'order date', 'state', 'priority']
df = pd.read_excel(src_file,
header=1,
usecols=lambda x: x.lower() in cols_to_use)
范围和表格
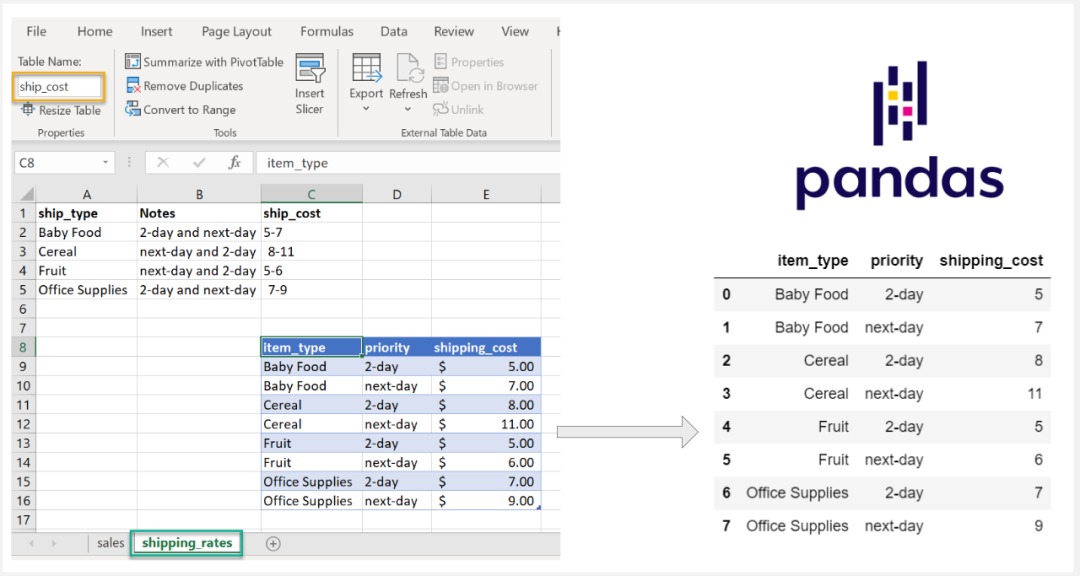
在某些情况下,Excel 中的数据可能会更加不确定,在我们的 Excel 数据中,我们有一个想要读取的名为 ship_cost 的表,这该怎么获取呢
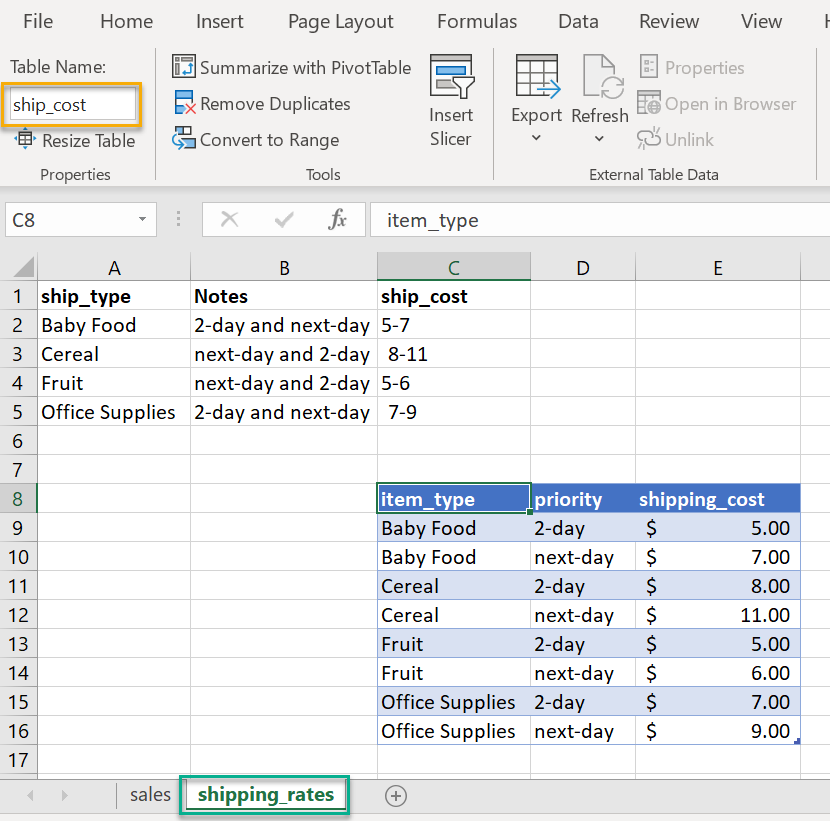
在这种情况下,我们可以直接使用 openpyxl 来解析 Excel 文件并将数据转换为 pandas DataFrame
以下是使用 openpyxl(安装后)读取 Excel 文件的方法:
from openpyxl import load_workbook
import pandas as pd
from pathlib import Path
src_file = src_file = Path.cwd() / 'shipping_tables.xlsx'
wb = load_workbook(filename = src_file)
查看所有的 sheet 页,获取某个 sheet 页,获取 Excel 范围数据
wb.sheetnames
sheet = wb['shipping_rates']
lookup_table = sheet.tables['ship_cost']
lookup_table.ref
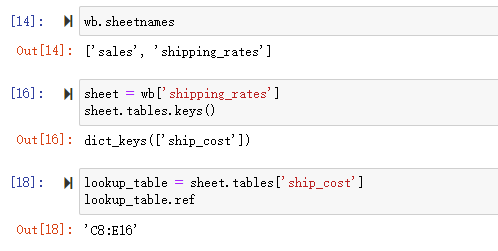
现在我们以及知道要加载的数据范围了, 接下来就是将该范围转换为 Pandas DataFrame
# 获取数据范围
data = sheet[lookup_table.ref]
rows_list = []
# 循环获取数据
for row in data:
cols = []
for col in row:
cols.append(col.value)
rows_list.append(cols)
df = pd.DataFrame(data=rows_list[1:], index=None, columns=rows_list[0])
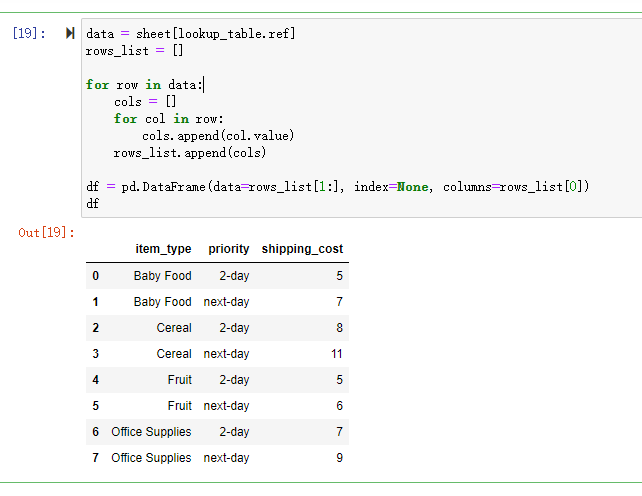
这样我们就获取到了干净的表数据了
好了,今天的两个小知识点就分享到这里了,我们下次再见!
需要完整代码和测试 Excel 数据,点点在看,微信私聊获取!
END
推荐阅读
Ps:从小程序直接获取下载如下福利