
ClickHouse到底牛逼在哪里?为什么比MySQL快831倍!
ClickHouse到底牛逼在哪里?为什么比MySQL快831倍!
这两年 ClickHouse 非常的火,尤其是在大数据领域。
刚好这两天也有群友在群里说起 ClickHouse,这款来自俄罗斯 Yandex 的开源数据库产品性能屌爆了,宣称比 MySQL 快 831 倍。今天我们就扯一扯 ClickHouse 到底好在哪里?
Yandex
在开始之前,我们先说一下 Yandex 这家公司,他是俄罗斯的一家互联网巨头公司,虽然在国际上没什么名气,但在俄罗斯,他就是老大,是俄罗斯排名第一的搜索引擎公司。是和谷歌、百度一样的存在。ClickHouse 诞生于 2016 年,就是来自于 Yandex 公司。
老毛子在国际互联网上,虽然没有像中美这样具有统治地位的互联网公司,但是老毛子的一些开源软件的性能还是杠杠的。比如,大名鼎鼎的 Nginx,再比如我们今天要讨论的 ClickHouse,所以,ClickHouse 还是非常值得一学的。
ClickHouse
ClickHouse 主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报告。
和我们常见的关系型数据库非常不同。比如,MySQL,Postgresql,SQL Server 等数据库采用的都是行式存储,而 ClickHouse 采用的确实列式存储。下面我们通过一个简单的例子,来比较它们的不同。
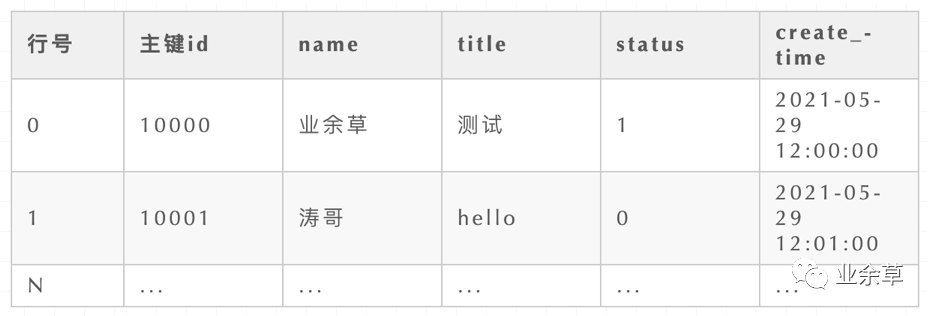
如上述表格所示,传统的 MySQL 数据库的每一行数据都是物理的存储在一起的。如果我要取 id 等于 10000 这一条数据的 name 列,那我就必须要把这一行数据读取出来,然后取 name 列。
再比如,下面的 SQL:
SELECT name FROM xttblog where id > 10000;
在众多的数据中,我只取一列,但我需要把每条数据都读取出来。
基于上面传统数据库的一些特点,ClickHouse 另辟蹊径,推出了列式存储。
| 行号 | 0 | 1 | N |
|---|---|---|---|
| 主键id | 10000 | 10001 | ... |
| name | 业余草 | 涛哥 | ... |
| title | 测试 | hello | ... |
| status | 1 | 0 | ... |
| create_time | 2021-05-29 | 2021-05-29 | ... |
看上图的列式存储示例,完全和 MySQL 等数据库不同。当我执行下面的 SQL 时,查询效率非常的高!
SELECT name FROM xttblog where id > 10000;
由于 name 列的数据都存储在一起,因此效率大大的超过了传统的数据库。
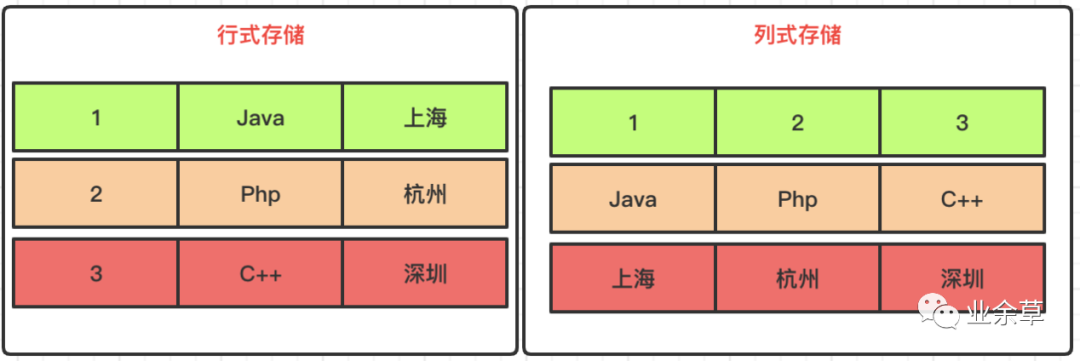
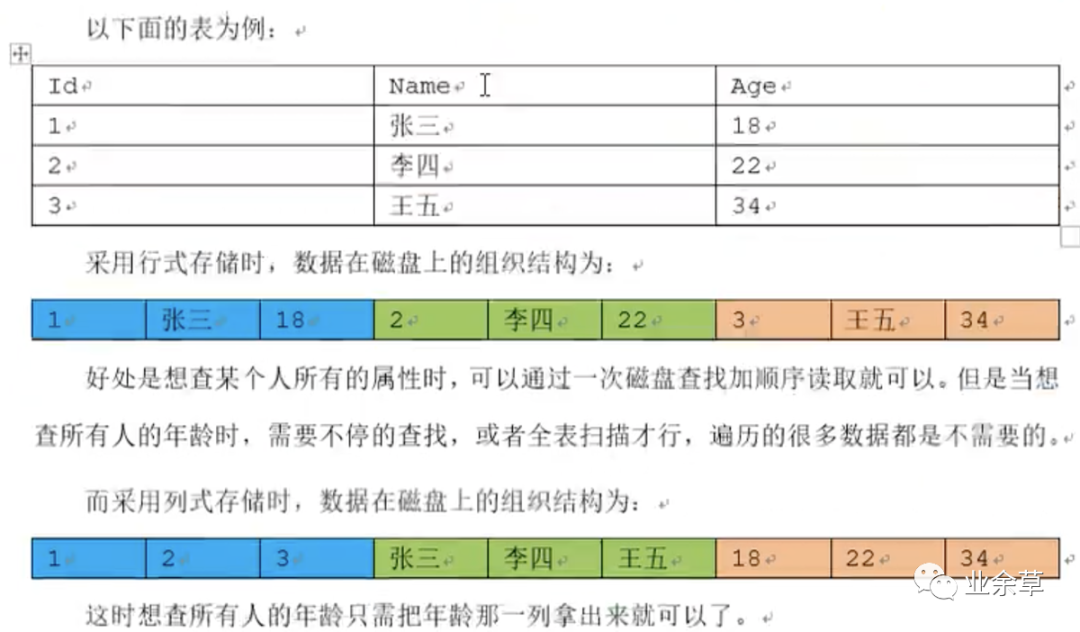
除了逻辑上的不同,磁盘上的组织结构也大不一样。
除了列式存储上的不同,ClickHouse 还有高效的数据压缩,默认使用LZ4算法,总体压缩比可达 8:1。ClickHouse 还采用了分布式多主架构提高并发性能,ClickHouse使读请求可以随机打到任意节点,均衡读压力,写请求也无需转发到master节点,不会产生单点压力。
ClickHouse 还有向量引擎,利用 SIMD 指令实现并行计算。对多个数据块来说,一次 SIMD 指令会同时操作多个块,大大减少了命令执行次数,缩短了计算时间。向量引擎在结合多核后会将 ClickHouse 的性能淋漓尽致的发挥出来。
ClickHouse 在索引上也有不同,采用了稀疏索引及跳数索引。同时还有很多 MergeTree,提供海量业务场景支持。
基于以上特点,ClickHouse 在包含 count、sum、group by、order by 等情况的查询对比,同等条件下,ClickHouse 的查询性能异常强悍,官网上的数据显示,是同等条件下 MySQL 的 831 倍。

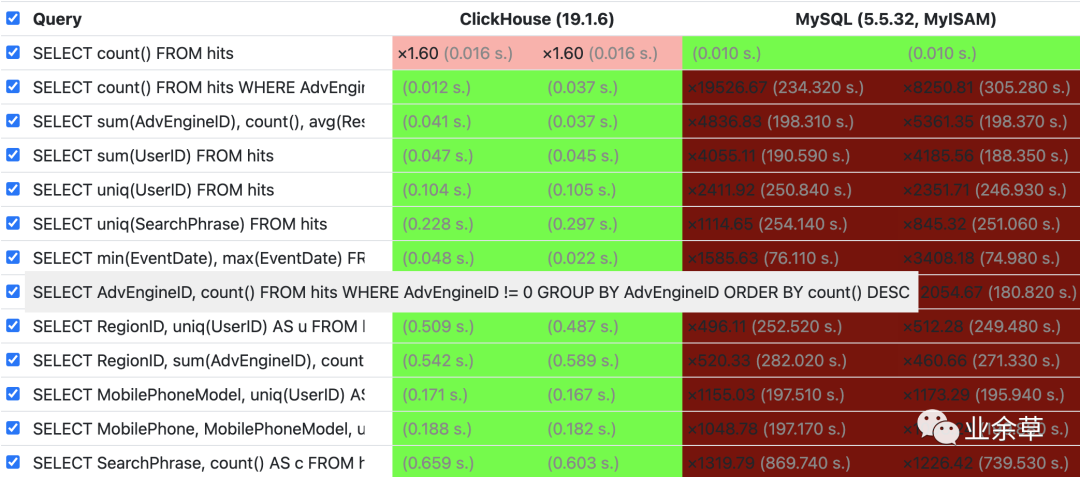
更多的对比数据,建议大家去官网上查看。
哎,又要内卷起来了。