
一文概览神经网络模型
一、神经网络类别
一般的,神经网络模型基本结构按信息输入是否反馈,可以分为两种:前馈神经网络和反馈神经网络。
1.1 前馈神经网络
前馈神经网络(Feedforward Neural Network)中,信息从输入层开始输入,每层的神经元接收前一级输入,并输出到下一级,直至输出层。整个网络信息输入传输中无反馈(循环)。即任何层的输出都不会影响同级层,可用一个有向无环图表示。
常见的前馈神经网络包括卷积神经网络(CNN)、全连接神经网络(FCN)、生成对抗网络(GAN)等。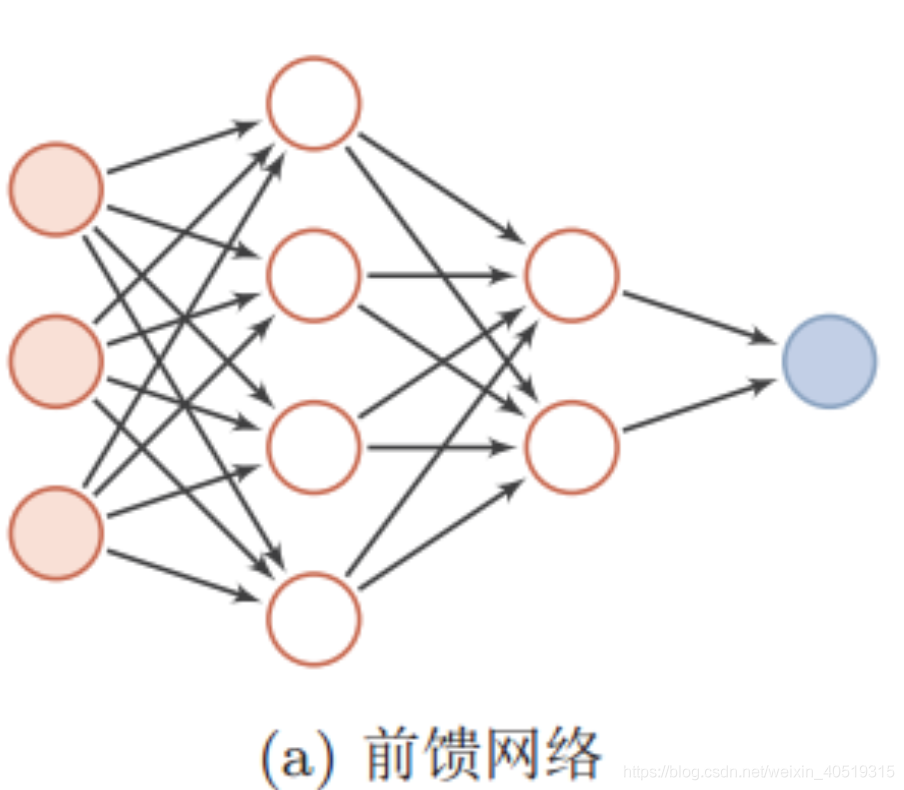
1.2 反馈神经网络
反馈神经网络(Feedback Neural Network)中,神经元不但可以接收其他神经元的信号,而且可以接收自己的反馈信号。和前馈神经网络相比,反馈神经网络中的神经元具有记忆功能,在不同时刻具有不同的状态。反馈神经网络中的信息传播可以是单向也可以是双向传播,因此可以用一个有向循环图或者无向图来表示。
常见的反馈神经网络包括循环神经网络(RNN)、长短期记忆网络(LSTM)、Hopfield网络和玻尔兹曼机。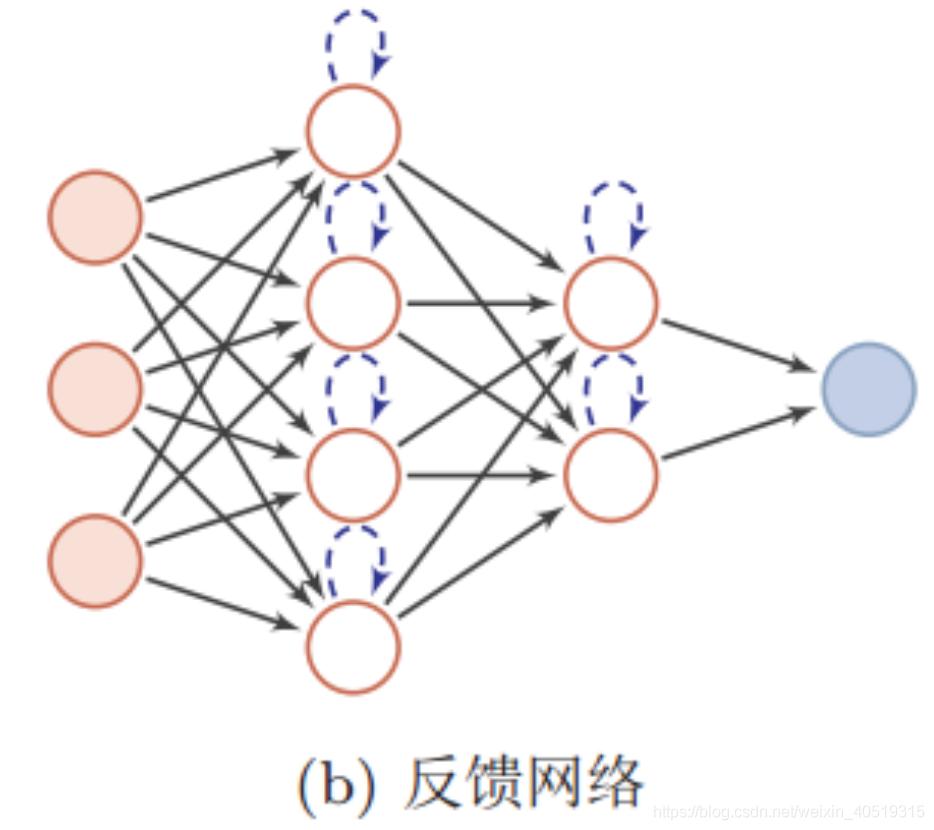
二、经典神经网络模型介绍
全连接神经网络(FCN)
全连接神经网络是深度学习最常见的网络结构,有三种基本类型的层: 输入层、隐藏层和输出层。当前层的每个神经元都会接入前一层每个神经元的输入信号。在每个连接过程中,来自前一层的信号被乘以一个权重,增加一个偏置,然后通过一个非线性激活函数,通过简单非线性函数的多次复合,实现输入空间到输出空间的复杂映射。
卷积神经网络(CNN)
图像具有非常高的维数,因此训练一个标准的前馈网络来识别图像将需要成千上万的输入神经元,除了显而易见的高计算量,还可能导致许多与神经网络中的维数灾难相关的问题。卷积神经网络提供了一个解决方案,利用卷积和池化层,来降低图像的维度。由于卷积层是可训练的,但参数明显少于标准的隐藏层,它能够突出图像的重要部分,并向前传播每个重要部分。传统的CNNs中,最后几层是隐藏层,用来处理“压缩的图像信息”。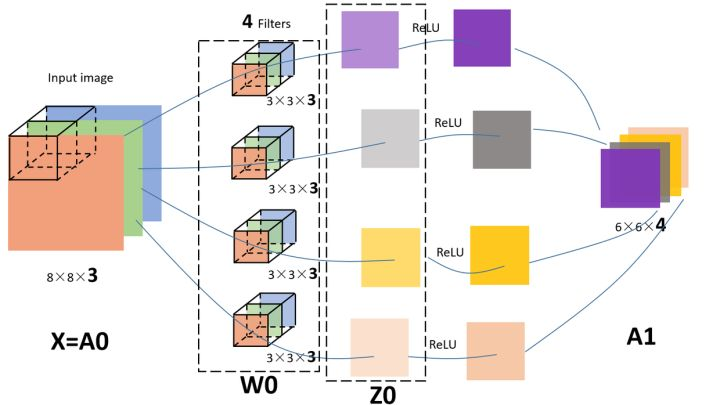
残差网络(ResNet)
深层前馈神经网络有一个问题,随着网络层数的增加,网络会发生了退化(degradation)现象:随着网络层数的增多,训练集loss逐渐下降,然后趋于饱和,当再增加网络深度的话,训练集loss反而会增大。为了解决这个问题,残差网络使用跳跃连接实现信号跨层传播。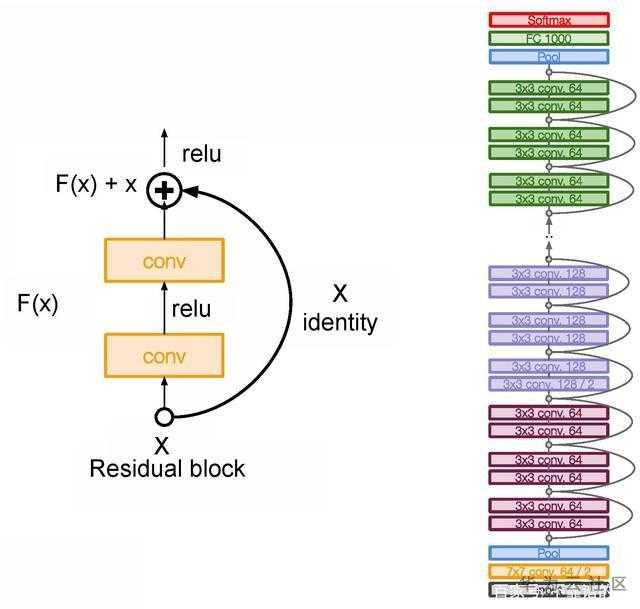
生成对抗网络(GAN)
生成对抗网络是一种专门设计用于生成图像的网络,由两个网络组成: 一个鉴别器和一个生成器。鉴别器的任务是区分图像是从数据集中提取的还是由生成器生成的,生成器的任务是生成足够逼真的图像,以至于鉴别器无法区分图像是否真实。随着时间的推移,在谨慎的监督下,这两个对手相互竞争,彼此都想成功地改进对方。最终的结果是一个训练有素的生成器,可以生成逼真的图像。鉴别器是一个卷积神经网络,其目标是最大限度地提高识别真假图像的准确率,而生成器是一个反卷积神经网络,其目标是最小化鉴别器的性能。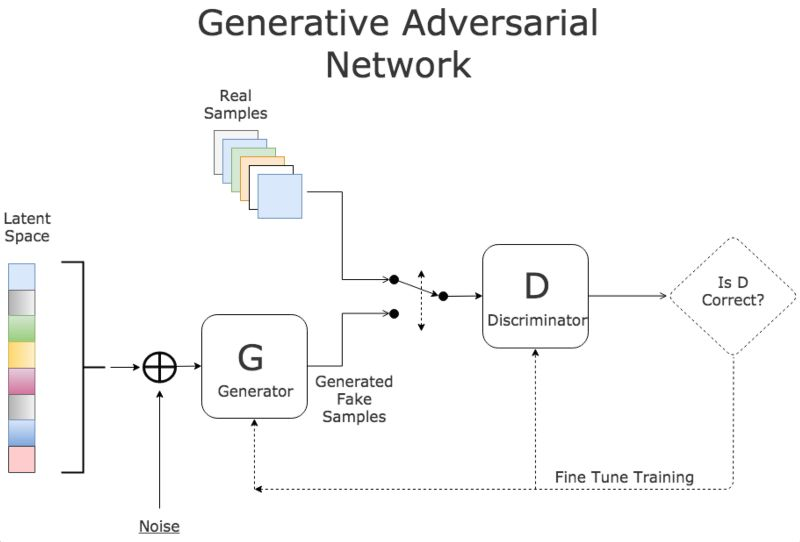
变分自动编码器(VAE)
自动编码器学习一个输入(可以是图像或文本序列)的压缩表示,例如,压缩输入,然后解压缩回来匹配原始输入,而变分自动编码器学习表示的数据的概率分布的参数。不仅仅是学习一个代表数据的函数,它还获得了更详细和细致的数据视图,从分布中抽样并生成新的输入数据样本。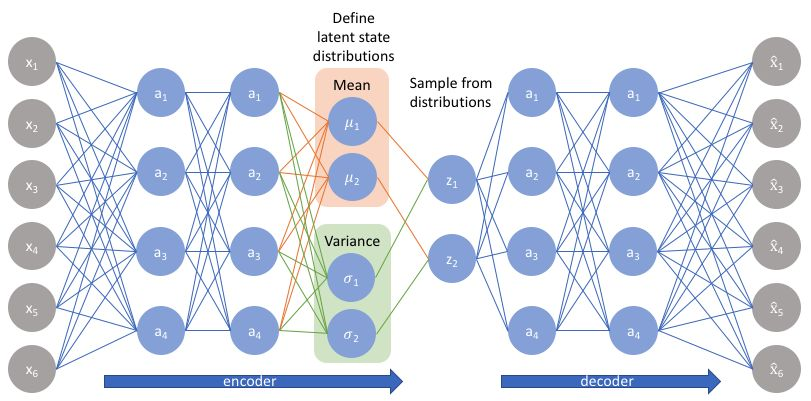
Transformer
Transformer是Google Brain提出的经典网络结构,由经典的Encoder-Decoder模型组成。在上图中,整个Encoder层由6个左边Nx部分的结构组成。整个Decoder由6个右边Nx部分的框架组成,Decoder输出的结果经过一个线性层变换后,经过softmax层计算,输出最终的预测结果。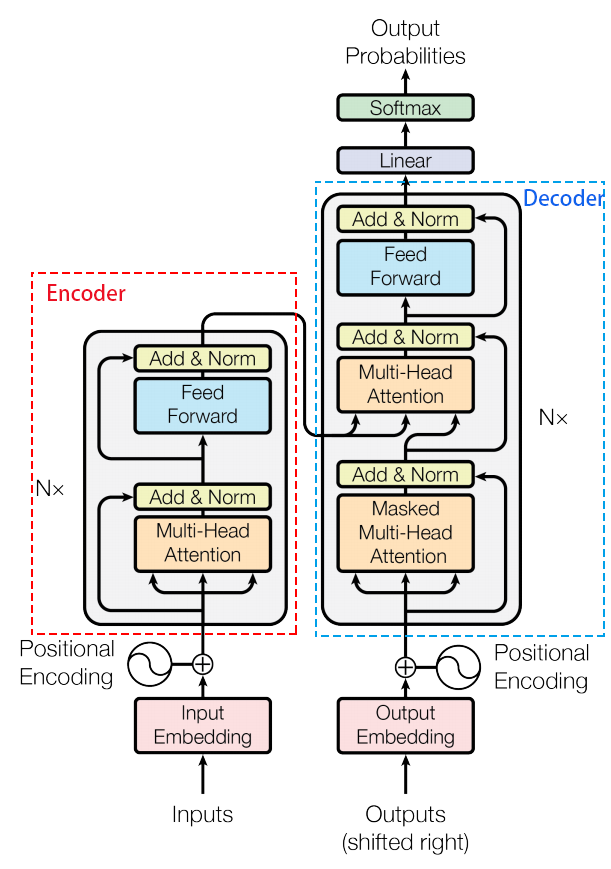
循环神经网络 (RNN)
循环神经网络是一种特殊类型的网络,它包含环和自重复,因此被称为“循环”。由于允许信息存储在网络中,RNNs 使用以前训练中的推理来对即将到来的事件做出更好、更明智的决定。为了做到这一点,它使用以前的预测作为“上下文信号”。由于其性质,RNNs 通常用于处理顺序任务,如逐字生成文本或预测时间序列数据(例如股票价格)。它们还可以处理任意大小的输入。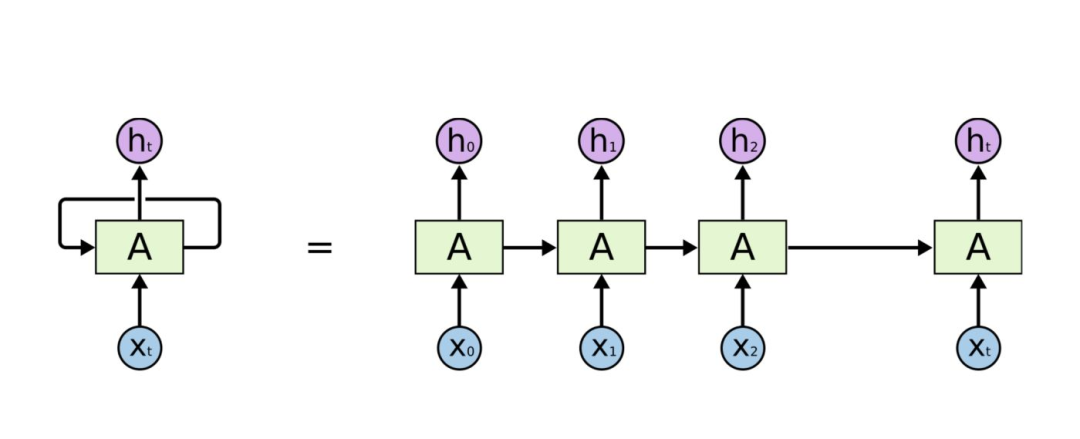
长短期记忆网络(LSTM)
LSTM结构是专门为解决RNN在学习长的的上下文信息出现的梯度消失、爆炸问题而设计的,结构中加入了内存块。这些模块可以看作是计算机中的内存芯片——每个模块包含几个循环连接的内存单元和三个门(输入、输出和遗忘,相当于写入、读取和重置)。信息的输入只能通过每个门与神经元进行互动,因此这些门学会智能地打开和关闭,以防止梯度爆炸或消失。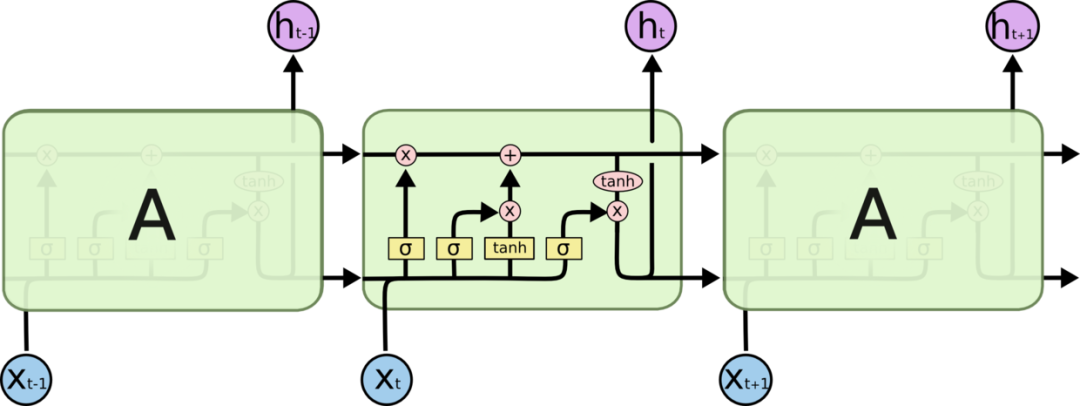
Hopfield网络
Hopfield神经网络是一种单层互相全连接的反馈型神经网络。每个神经元既是输入也是输出,网络中的每一个神经元都将自己的输出通过连接权传送给所有其它神经元,同时又都接收所有其它神经元传递过来的信息。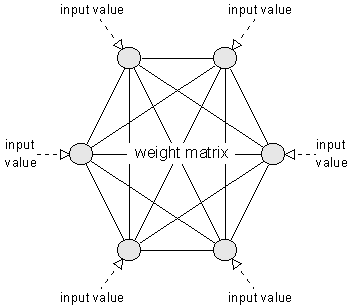
三、网络结构设计的思考
实践中,我们除了结合任务直接选用一些经典神经模型做验证,有时也需要对网络结构做设计优化。网络结构的设计需要考虑的2个实质问题是:
神经单元应该如何连接? 需要有多少神经元?
3.1 神经单元应该如何连接?
也就是神经网络基本的架构如何设计,有两种设计思路:
将人类先验嵌入到模型结构设计 例如,基于图像任务的平移不变性的卷积假设设计的CNN,或者基于语言的递归性质的递归假设设计的RNN。对于先验知识,可以凭借经验做网络结构设计无疑是相对高效的,但太多复杂经验的注入,一来不够“优雅”,二来如果经验有误,设计的结构可能就失效了。
通过机器动态学习和计算出的结构 如神经网络架构搜索(NAS),常见的搜索方法包括:随机搜索、贝叶斯优化、进化算法、强化学习、基于梯度的算法。
3.2、需要有多少神经元?
神经网络由输入层、隐藏层与输出层构成:
输入层:为数据特征输入层,输入数据特征维数就对应着网络的神经元数。 隐藏层:即网络的中间层,其作用接受前一层网络输出作为当前的输入值,并计算输出当前结果到下一层。隐藏网络神经元个数直接影响模型的拟合能力。-输出层:为最终结果输出的网络层。输出层的神经元个数代表了分类类别的个数(注:在做二分类时,如果输出层的激活函数采用sigmoid,输出层的神经元个数为1个;如果采用softmax分类器,输出层神经元个数为2个是与分类类别个数对应的;)
对于网络的输入层、输出层的神经元通常是确定的,主要需要考虑的是隐藏层的深度及宽度,在忽略网络退化问题的前提下,通常隐藏层的神经元(计算单元)的越多,模型有更多的容量(capcity)去达到更好的拟合效果。
搜索合适的网络深度及宽度,常用有人工调参、随机搜索、贝叶斯优化等方法。这里有个引申问题:
增加神经网络宽度vs深度的效果有什么差异呢?
1、拟合效果上,增加深度远比宽度高效 同等效果上,要增加的宽度远大于增加的深度。在Delalleau和Bengio等人的论文《Shallow vs. Deep sum-product networks》中提出,对于一些特意构造的多项式函数,浅层网络需要指数增长的神经元个数,其拟合效果才能匹配上多项式增长的深层网络。
2、参数规模上,增加深度远比宽度需要的参数少
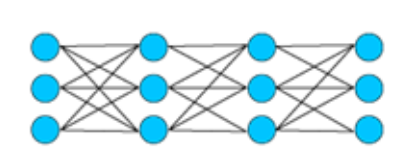
以上图神经网络为例,将单层宽度增加3个神经元,会新增6个与之相连前后层的权重参数。而直接新增一个3个神经元的网络层,只会新增3个的权重参数。
3、 功能上,深度层功能类似于“生成特征”,而宽度层类似于“记忆特征” 增加网络深度可以获得更抽象、高层次的特征,增加网络宽度可以获得更丰富的特征。
当然,深度和宽度并不是完全对立的关系,增加深度和宽度都是在增加可学习参数的个数,从而增加神经网络的拟合能力,在网络设计需要追求深度与广度的平衡。
文章首发公众号“算法进阶”,更多原创文章敬请关注