
【NLP】相当全面:各种深度学习模型在文本分类任务上的应用

论文标题:Deep Learning Based Text Classification:A Comprehensive Review
论文链接:https://arxiv.org/pdf/2004.03705.pdf
论文介绍了各种深度学习模型在文本分类任务上的应用,按照模型的结构进行分类介绍,基本上涵盖了当前大部分的深度结构,也可以当作神经网络结构入门参考。论文中讨论了150多篇论文,由于能力与时间有限,本文只简单介绍了小部分,详细内容请参考原论文与原论文参考文献。
集大成系列会分享各个领域(方面)的综述论文(建议大家看原论文),分享内容主要来自于原论文,会有些整理与删减,以及个人理解与应用等等,其中涉及到的算法复现都会开源在:https://github.com/wellinxu/nlp_store
介绍 文本分类中的深度学习模型 前馈神经网络FNN 循环神经网络RNN 卷积神经网络CNN 胶囊神经网络 注意力机制 记忆增强网络 Transformers 图神经网络GNN 孪生神经网络S2Net 混合模型 非监督学习 文本分类数据集 实验性能分析 文本分类常用指标 定量分析结果 挑战与机遇 参考
介绍
文本分类是NLP中的经典问题,主要的文本分类方式分为三种:
基于规则的方法
基于规则的方法,就是使用一组预先定义好的规则将文本分到不同的类别,这需要很深的领域知识。基于机器学习(数据驱动)的方法
基于机器学习的方法是根据已有的数据自动学习分类,这可以学习到文本与类别内在的关系。混合方法
混合方法则是结合规则与机器学习两种方式来预测。
机器学习模型今年多一直很受关注,经典的机器学习主要有两步,一是手动提取特征,主要包括词袋模型及相关变体,二是将特征喂给模型进行学习预测,主要包括NB、SVM、GBDT、RF、LR等等。2012年之后,基于深度学习的模型被大规模地应用在各种文本分类任务上,同时也提高了各个任务的准确性,主要包括:
情感分析
情感分析是分析文本数据(如产品评论、电影评论、推文)中人们的观点,提取他们的极性和观点。情绪分类可以是二元问题(正负两类),也可以是多类问题(细粒度的标签或多层次的强度)。新闻分类 主题分析
主题分类的目标是为每个文档分配一个或多个主题,以便于分析。问答(QA)
QA有两种类型:抽取式和生成式。抽取式QA可以看作是特殊的文本分类。给定一个问题和一组候选答案(例如,SQuAD中给定文档中的文本范围),将每个候选答案分类为正确或不正确。论文中涉及的是抽取式QA。自然语言推理(NLI)
NLI也被称为识别文本蕴涵(RTE),判断是否可以从一个文本中推断出另一个文本的意义。
深度学习模型通过端到端的方式,学习特征的表达然后进行分类。论文中,分析了超过150个深度学习模型,根据其神经网络结构进行分类,并讨论了各个模型的技术贡献、相似性、优点等等。之后论文提供了40多个文本分类任务数据集,并在16个基准集上测试了不同的深度学习模型,最后讨论了当前的难点与未来的方向。
文本分类中的深度学习模型
本小节中回顾了150多个文本分类领域的深度学习模型,根据这些模型的主要结构进行分类介绍。这里假设大家对基础深度学习模型较熟悉,如果想知道模型的更多细节,请参考【1】。
前馈神经网络FNN
FNN虽然结构简单,但在很多文本分类任务上都有较高的准确性。这类模型将文本看作词袋,然后为每一个词学习一个向量表示(类似word2vec,Glove),然后取所有向量的和或者平均,传递给前向传播层(也叫多层感知机MLP),最后在输入分类器(LR、NB、SVM等等)进行分类。比如DAN模型,其结构如下图所示。与之类似的,如Facebook提出的FastText【2】模型,FastText较大的改进是使用了n-gram作为补充特征。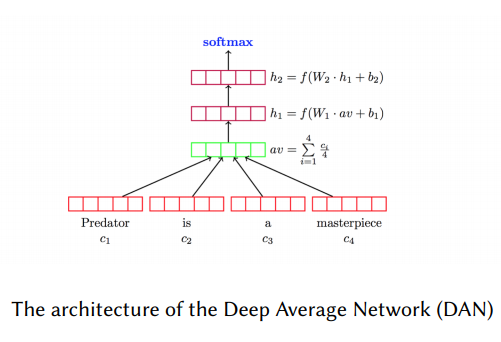
doc2vec使用非监督方法,学习一段文本(句子、段落或篇章)的向量表示。如下图所示,doc2vec的结构跟CBOW模型相似,唯一的区别是doc2vec增加了一个段落token。doc2vec用前三个词并结构文档向量预测第四个词,文档向量可以作为文档主题记忆。在训练之后,文档向量可以用作分类,在doc2vec发表的时候,在几个文本分类以及情感分析任务上取得了SOTA的效果。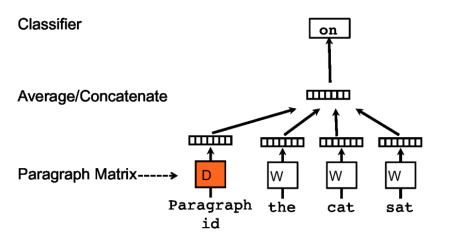
循环神经网络RNN
RNN类的模型将文本看作词序列(如下图左边所示),通过获取词之间的依赖以及文本结构信息进行分类。RNN类最常见的结构是LSTM,其缓解了RNN梯度消失的问题。Tree-LSTM是LSTM的树型结构扩展(如下图右边所示),可以学到更丰富的语义表示,在情感分析与句子相似性判断任务上证明了其有效性。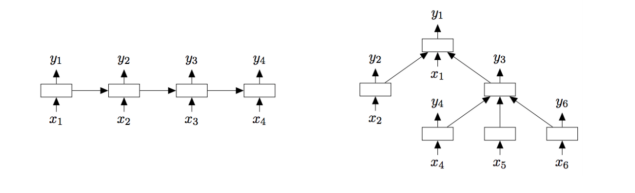
为了给长距离词关系建模,研究人员使用记忆网络替代了LSTM中的单个记忆单元,这在语言模型、情感分析、NLI任务上取得了很好的结果。MT-LSTM通过获取不同时间尺度上的信息来给长文本建模,MT-LSTM将标准LSTM模型中隐藏状态分成多个组,每组会在不同的时间阶段激活并更新。TopicRNN结合了RNN与主题模型的有点,用RNN获取局部(句法)信息,用主题模型获取全局(语义)信息,该模型在情感分析任务上取得了不错的结果。
卷积神经网络CNN
RNN可以跨时间识别模式,而CNN可以跨空间识别模型。DCNN是最开始使用CNN做文本分类的模型之一,DCNN动态进行k维最大池化(k根据语句长度与卷积层次进行动态选择),其结构如下图所示,输入是词向量,然后交替使用宽卷积层和动态池化层,该结构可以捕获词语与短语间的长短期关系。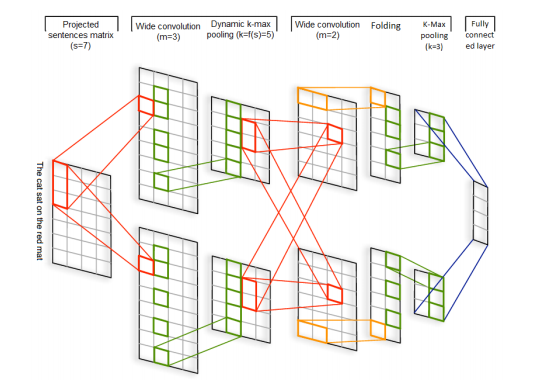
相比DCNN,TextCNN【3】的结构更加简单,如下图所示,TextCNN只使用一层卷积,然后将整个文本序列的每一个卷积核的结果池化成一个值,拼接所有池化结果进行最终预测。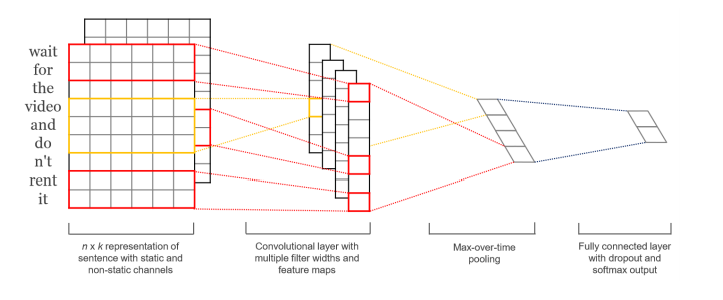
字符级别的CNN也被处理文本分类,如下图所示模型结构,以固定长度的字符作为输入,通过6层带池化的卷积层和3层全连接层进行预测。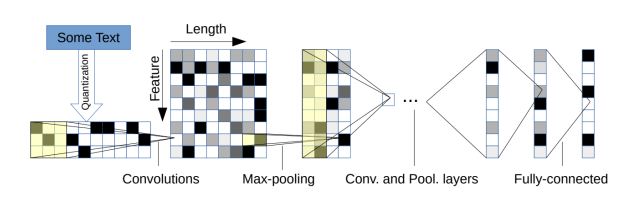
受VGG与ResNets的影响,研究人员提出了VDCNN模型,其也是直接处理字符输入,且只是用了小卷积跟池化操作,研究表明随着深度增加VDCNN的效果也在提高。后续有人对VDCNN做了改进,将模型大小压缩了10到20倍,精度只损失了0.4%-0.3%。研究人员发现,当文本以字符序列作为输入的时候,深层模型比浅层模型表现更好,但如果用词作为输入,一个浅且宽的模型(比如DenseNet)比深层模型效果更好。后续的论文发现,使用非静态的词向量(word2vec、Glove)与最大池化操作可以获得更优的结果。
胶囊神经网络
CNN中的池化层会丢失一些信息,为了解决这个问题,Hinton提出了胶囊网络(CapsNets)。一个胶囊是一组神经元,神经元中的向量表示实体的不同属性,向量的长度表示实体存在的概率,方向表示实体的属性。与池化操作不同,胶囊使用路由的方式,从底层的各个胶囊上路由到上层的父胶囊上,路由可以通过按协议动态路由或者EM等不同算法来实现。
基于胶囊网络,研究人员提出了对应的文本分类模型,其包含一个n-gram卷积层,一个胶囊层,一个卷积胶囊层,一个全连接胶囊层。如下图所示,他们研究了两种胶囊网络,Capsule-A跟CapsNet比较类似,Capsule-B使用了带有不同窗口大小过滤器的三个并行网络,试图学习更全面的文本表示,实验中B的效果更好。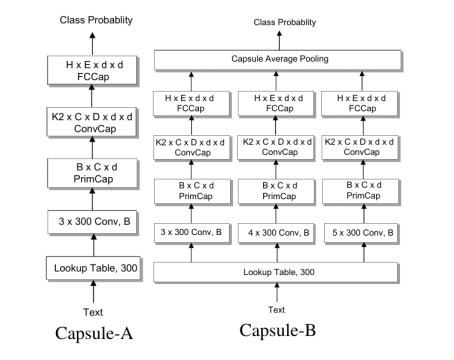
后续研究人员发现,相比较于图像,物体在文本中可以更加随意地组合在一起,比如一些语句的顺序改变,但文本的语义还可以保持一致,而不像人脸图像,眼睛跟鼻子的位子变换,则就不能认为是脸了。所以他们提出了一种静态路由模式,在文本分类任务上,取得了优于动态路由的效果。
注意力机制
注意力在NLP领域被广泛使用,简单来说,语言模型中的注意力就是一组重要性权重的向量。研究人员提出了层次注意力网络来进行文本分类,其主要有两个特点:反映了文档的层次结构,在词级别与句子级别分别使用了注意力机制,这个模型在6个文本分类任务上都取得了较大进步。
在配对排序跟匹配任务上,研究人员提出了注意力池化(AP)方法。AP可以让池化层知道当前输入对,来自两个输入的信息一定层度上可以直接影响对方的表示结果。如下图所示,AP是一种独立于底层表示学习的框架,也可以应用在CNN、RNN等模型上。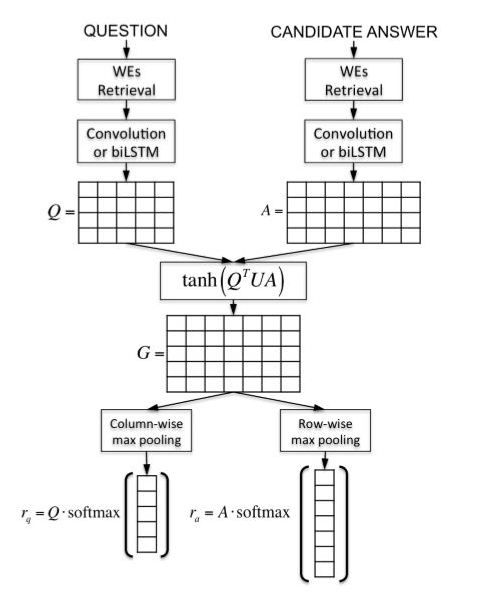
还有研究人员,将文本分类问题看作是标签-文本的匹配问题,如下图所示,通过注意力框架与cosine相似度度量文本序列与标签之间的向量相似度。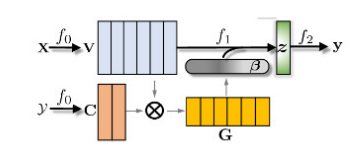
记忆增强网络
在编码过程中注意力模型里保存的隐藏向量可以认为是模型的内部记忆,记忆增强网络结合了神经网络与外部记忆(模型可以读出与写入)。针对文本分类与QA任务,研究人员提出了一种记忆增强网络NSE(Neural Semantic Encoder),如下图所示,NSE具有一个大小可变的编码记忆存储器,随着时间进行改变,并通过读入、生成、写入操作来保存对输入序列的理解。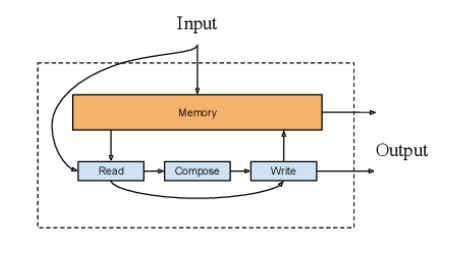
同样针对QA任务,有人将一系列的状态(记忆实体)提供给模型,作为对问题的支持事实,模型会学习如何根据问题与历史检索记忆来检索实体,后续研究中,将该模型拓展为端到端的形式,通过注意力机制来实现实体检索。
Transformers
RNN类模型在处理序列问题时需要很大的计算资源,而Transformers则避免了这一点,通过使用self-attention来并行计算序列中每一个词跟其他所有其的关系。自2018年开始,出现了很多基于Transformers的预训练语言模型(PLM),PLM一般具有很深的神经网络结构,并且会在非常大的语料上进行预训练(通过语言模型等任务来学习文本表示)。使用PLM进行微调,在很多下游NLP任务上都取得了SOTA的效果。
PLM大体可以分为两类:自回归与自编码模型。OpenGPT就是自回归模型之一,从左到右(或从右到左)在文本序列上一个词一个词预测的单向模型。如下图所示,OpenGPT包含12层Transformer,每一个Transformers由遮蔽的多头attention与全连接层组成,其中每一层都会加上残差并做层标准化操作。文本分类任务可以作为其下游任务,使用相关的线性分类器并在具体任务数据上微调就可以。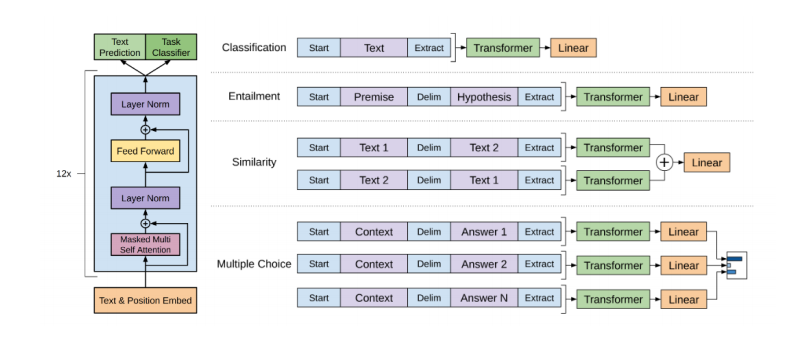
最为流行的自编码预训练模型就是BERT了,BERT使用的是遮蔽语言模型来做训练,就是随机遮蔽句子中的token,然后用双向的Transformers根据上下文给遮蔽的token进行编码,从而预测被遮蔽的token。后续有很多BERT的拓展工作,RoBERTa在更大的训练集上进行训练,使用了动态遮蔽的方式,并丢弃了下一句预测任务,具有更鲁棒的效果。ALBERT降低了模型的大小并提高了训练速度。DistillBERT在预训练过程使用知识蒸馏的方式,模型大小减少40%,保留了99%的精度,且推断速度提高了60%。SpanBERT则能更好的表示与预测文本span。BERT类的模型在QA、文本分类、NLI等各种NLP任务上,都取得了很好的结果。
也有结合自回归模型与自编码模型各自有点的,比如XLNet,在预训练过程中那个,使用排序操作来同时获取上下文信息。XLNet引入了双流self-attention模式来处理排序语言模型,如下图所示,它包含两个attention,内容attention(下图a)就是标准的attention结构,查询attention(下图b)则不能看到当前的token语义信息,只有当前token的位置信息。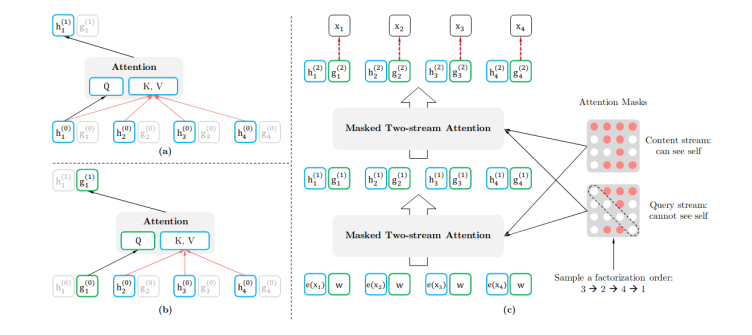 除此之外,UniLM(Unified language Model)使用了三种语言模型任务来进行预训练:单向、双向和seq2seq预测。如下图所示,UniLM模型通过共享Transformers网络来实现,其中以特定的self-attention遮蔽来控制预测条件的上下文。
除此之外,UniLM(Unified language Model)使用了三种语言模型任务来进行预训练:单向、双向和seq2seq预测。如下图所示,UniLM模型通过共享Transformers网络来实现,其中以特定的self-attention遮蔽来控制预测条件的上下文。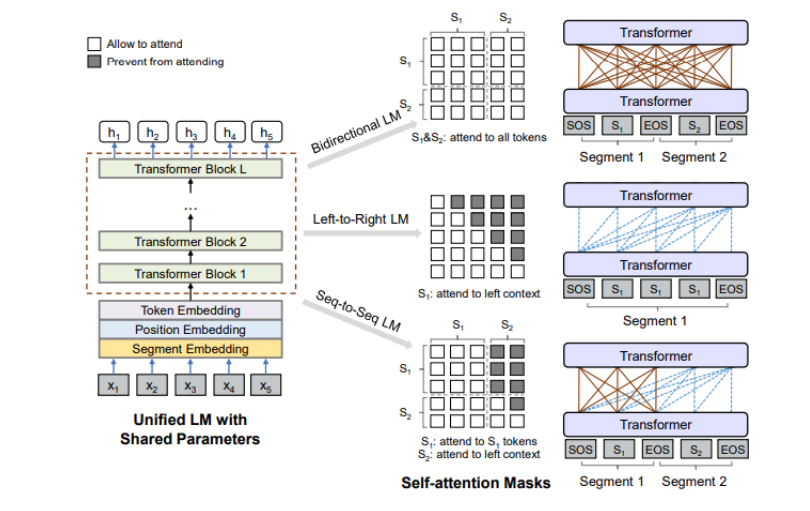
图神经网络GNN
虽然文本是以序列的形式展现,但其中也包含了图结构,如句法和语义树。NLP中最早的图模型之一是TextRank,将文本看作一个图,各种类型的文本单位,如单词、搭配、整个句子等,可看作节点,而节点之间的各种关系,如词法或语义关系、上下文重叠等,可看作边。
在GNN的各种类别中,GCN(Graph Convolutional Network)以及其变体是最流行的结构,因为其有效且高效,在很多应用上都取得了SOTA的效果。如下图所示,研究人员提出了基于graph-CNN模型,首先将文本转换成词图,然后用图卷积操作来处理词图,他们的实验表明,词图的表示能够获取文本中的非连续和长距离语义,并且CNN可以学习到不同层次的语义信息。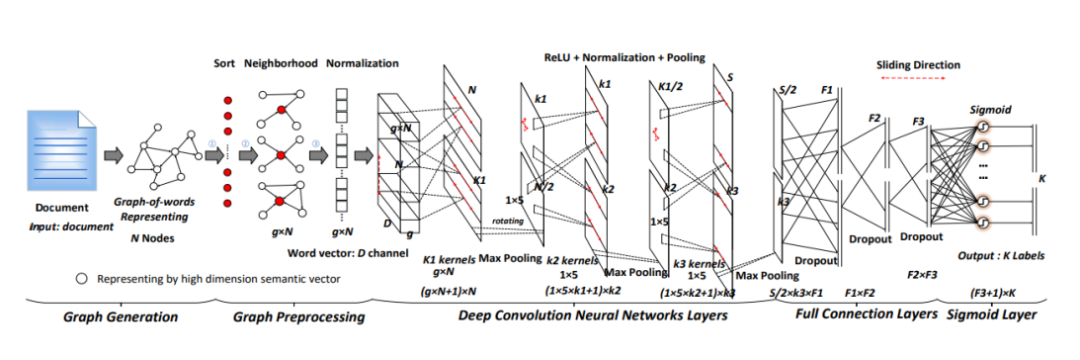
类似的,有研究人员提出了GCNN【4】方式来进行文本分类,GCNN将整个语料构建成一个单一的图,通过词贡献关系与文档-词关系。如下图所示,词与文档都是节点,随机初始化节点表示,然后用已知标签的文档进行有监督训练,从而学到词跟文档的向量。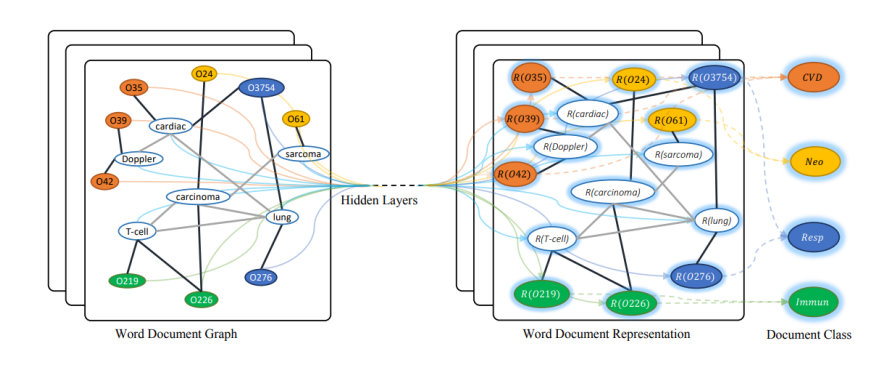
在大量文本上使用GNN代价比较大,一般会通过降低模型复杂度或者改变模型训练策略来减少成本。比如SGC(Simple Graph Convolution)【5】就是前面一种方法,移除了连续层之间的非线性转换操作。后面一种方式则会对文档层次进行构建图,而不对整个语料构图。
孪生神经网络S2Net
S2Net或者其变体DSSM(Deep Structured Semantic Model)【6】主要是针对文本匹配问题的。如下图所示,DSSM(或者S2Net)包含了一对DNN结构(f1、f2),将x、y分别映射到一个低纬语义空间,然后根据cosine距离(或其他方法)计算其相似度。S2Net中假设f1与f2具有一样的结果甚至一样的参数,但在DSSM中这两个可以根据实际情况具有不同的结构。因为文本以序列的形式展现,所以通常会用RNN类的结构来实现f1、f2,后来也有人使用CNN等其他结构,在BERT出现之后,也有不少基于BERT的模型,比如SBERT、TwinBERT等等。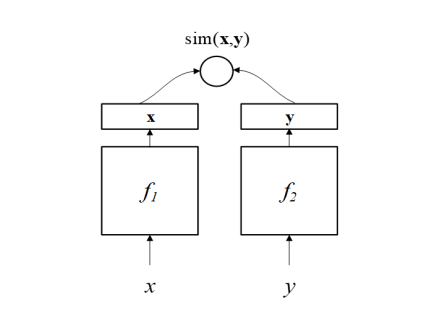
混合模型
很多混合模型都会结合LSTM与CNN结构来获取局部特征与全局特征,比如C-LSTM(Convolutional LSTM)与DSCNN(Dependency Sensitive CNN)。如下图a所示,C-LSTM先用CNN提取文本短语(n-gram)表示,然后输入LSTM获取句子的表示。而DSCNN如下图b所示,先用LSTM获取学习句向量,然后输入CNN生成文本表示。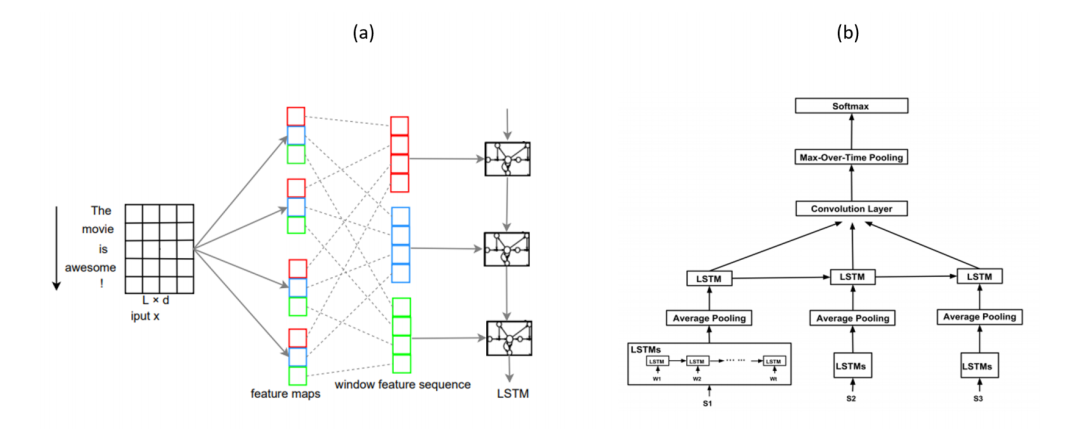
针对阅读理解中的多步推理,有人提出了SAN模型(Stochastic Answer Network),如下图所示,SAN包含了很多结构,如记忆网络、注意力机制、LSTM、CNN。其中Bi-LSTM组件来获取问题与短文的内容表示,再用基于问题感知的注意力机制学习短文表示。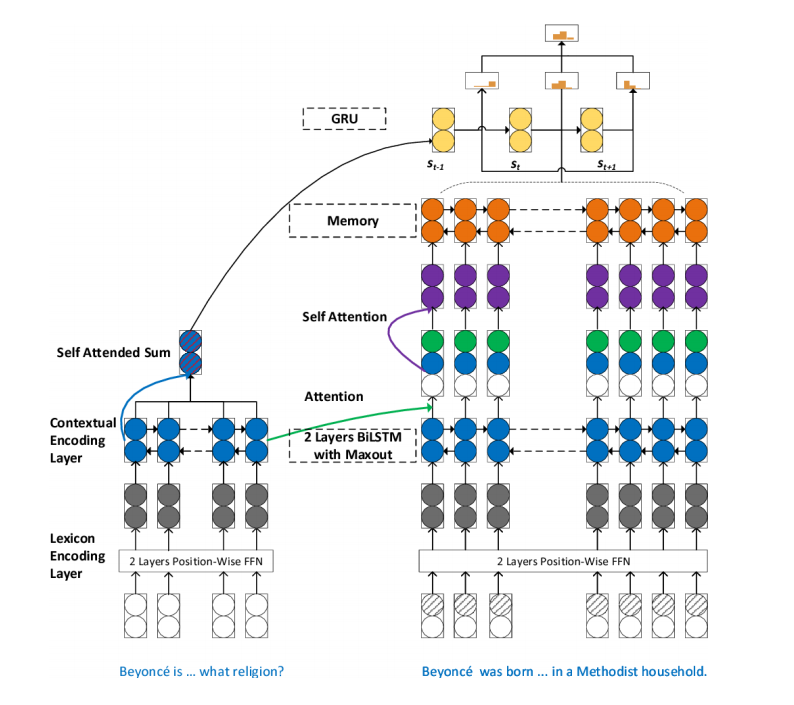
还有一些研究聚焦于“高速公路”网络,随着模型深度的增加,基于梯度训练的网络就变得更加困难,“高速公路”网络就是设计来解决这种问题,其允许信息在多个层上无阻地流动,有点类似于ResNet。如下图结构所示,是一种基于字符的语言模型,先用CNN获取词表示,然后输入到“高速公路”网络,然后接LSTM模型,最后用softmax来预测每个词的概率。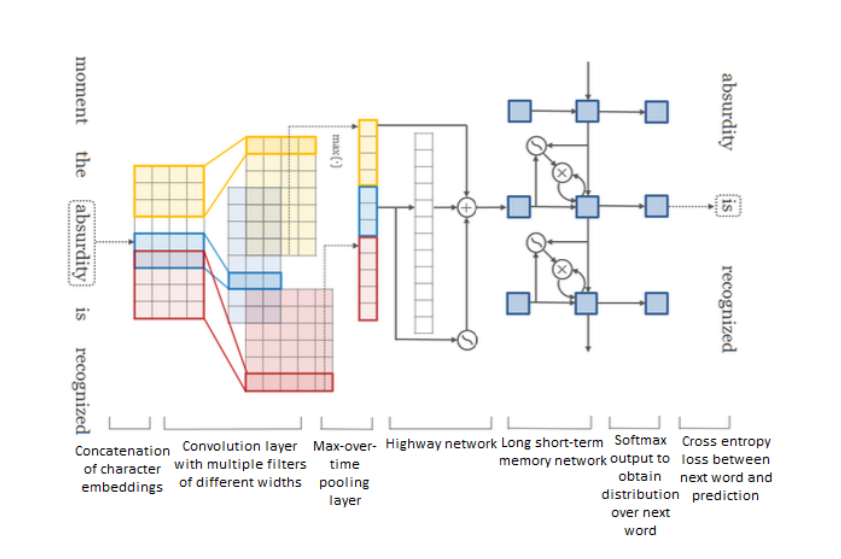
非监督学习
自编码的无监督学习
跟词向量类似,通过优化一些辅助目标,如自编码器的重构loss,可以用非监督的形式学习句子的表示。对抗训练
对抗训练是提高分类器泛化能力的一种方法,通过扰动输入数据生成对抗样本,来提高模型的鲁棒性。强化学习
强化学习是训练代理根据策略执行某些动作的方法,通常用最大化奖励来进行训练。
文本分类数据集
情感分析数据集
Yelp
Yelp有两种数据集,Yelp-5(细粒度情感标签)、Yelp-2(正负情感)。Yelp-5的每个类别都有650000个训练样本,50000个测试样本,Yelp-2一共包含560000个训练样本和38000个测试样本。IMDB
IMDB是影视评论数据集,包含同样数目的正例与负列,训练集与测试集各有25000个。Movie Review(MR)
MR也是正负两极的影评数据,正负样本数量一致,共10662条。SST
SST是MR数据集的拓展,有两类SST-1(细粒度标签,5类)、SST-2(两类标签)。SST-1中包含8455个训练样本1101个验证样本和2210个测试样本。SST-2中包行6920个训练样本872个样本样本和1821个测试样本。MPQA
MPQA是两个标签的意见语料库,有3311个正样本,7293个负样本。Amazon Amazon是商品评价数据集,也有两种:Amazon-2(2标签)、Amazon-5(5标签)。Amazon-2分别有3600000个训练数据和400000个测试数据,Amazon-5有3000000个训练数据650000个测试数据。 其他
SemEval-2014、Twitter、SentiHood。新闻分类数据集
AG News
AG News4标签的短文本学术新闻数据,有120000个训练样本和7600个测试样本。20 Newsgroups
20 Newsgroups有20个类别,最流行的一版有18821个样本,每个类别样本量一致。Sougo News
中文分类数据集Reuters news
Reuters-21578有90个类别,7769个训练数据和3019个测试数据。其他
Bing news, NYTimes, BBC, Google news。主题分类数据集
DBpedia
DBpedia数据集是一个大规模的、多语言的知识库,是从Wikipedia中最常用的信息框创建的。DBpedia每月发布一次,在每次发布中添加或删除一些类和属性。DBpedia最流行的版本包含560,000个训练样本和70,000个测试样本,每个样本都有一个14个类的标签。Ohsumed
Ohsumed集合是MEDLINE数据库的一个子集。Ohsumed包含7400个文档。每个文档都是医学摘要,从23种心血管疾病类别中选出一个或多个类别作为标签。EUR-Lex
该数据集最流行的版本基于欧盟法律的不同方面,有19,314个文档和3,956个类别。WOS
科学网络(WOS)数据集是科学网络上可获得的已发表论文的数据和元数据的集合。PubMed
PubMed是美国国家医学图书馆为医学和生物科学论文开发的搜索引擎。其他
PubMed 200k RCT,Irony。问答数据集
SQuAD
斯坦福问答数据集是一个从维基百科文章衍生的问答对的集合。SQuAD1.1包含536篇文章与107785个问答对。SQuAD2.0包含了1.1中的10000个问答对以及50000个没有答案的问题。MS MARCO
该数据集由微软发布,其中有部分答案是生成式的,所以该数据集也可以用来开发生成式问答系统。TREC-QA
这个数据集有两个版本,称为TREC-6(6个类型问题)和TREC-50(50个类型的问题)。这两个版本,训练和测试数据集分别包含5452和500个问题。WikiQA
该模型还包含没有答案的问题。Quora
Quora数据集是为检测重复问题,其中包含400000个问题对。其他
SWAG、WikiQA、SelQA。自然语言推理数据集
SNLI
斯坦福自然语言推断(SNLI)数据集被广泛用于NLI。该数据集由550,152,10,000和10,000句对组成,分别用于训练,开发和测试。每一对都标注有三个标签:中性,含蓄,矛盾。Multi-NLI
该语料库是SNLI的延伸,由433k个句子对组成的集合。SICK
SICK共有10000对句子对,同样包含中性,含蓄,矛盾三种标签。MSRP
MSRP是常见的文本相似度数据集,包含4076条训练样本与1725条测试样本。其他
STS、RTE、SciTail。
下图显示了各个数据集以及数据量的大小。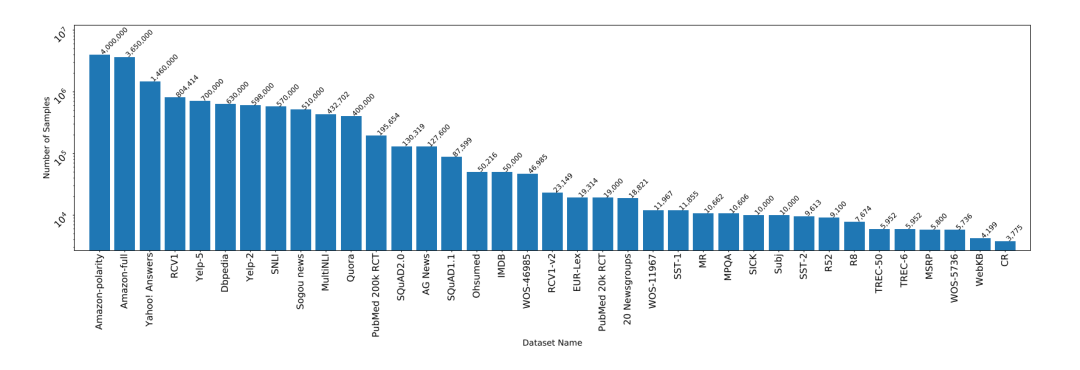
实验性能分析
文本分类常用指标
准确度和错误率 精度/召回/ F1得分 精确匹配(EM)
EM是问答系统的常用指标,其衡量了预测值跟任意一个正确答案匹配的比例。平均倒数排序(MRR)
MRR用来衡量排序问题或者QA问题,计算公式如下,其中Q表示所有预测答案,表示第i个预测答案在真实答案中的排序。
其他
NAP,ACU等。
定量分析结果
情感分析结果 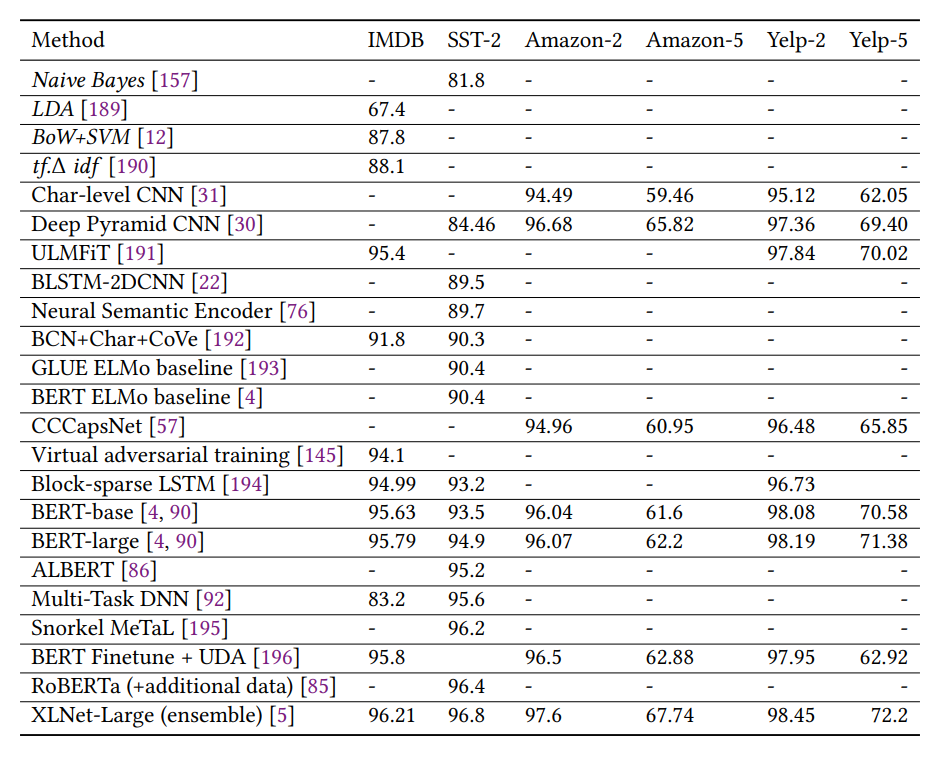
新闻分类和主题分类结果 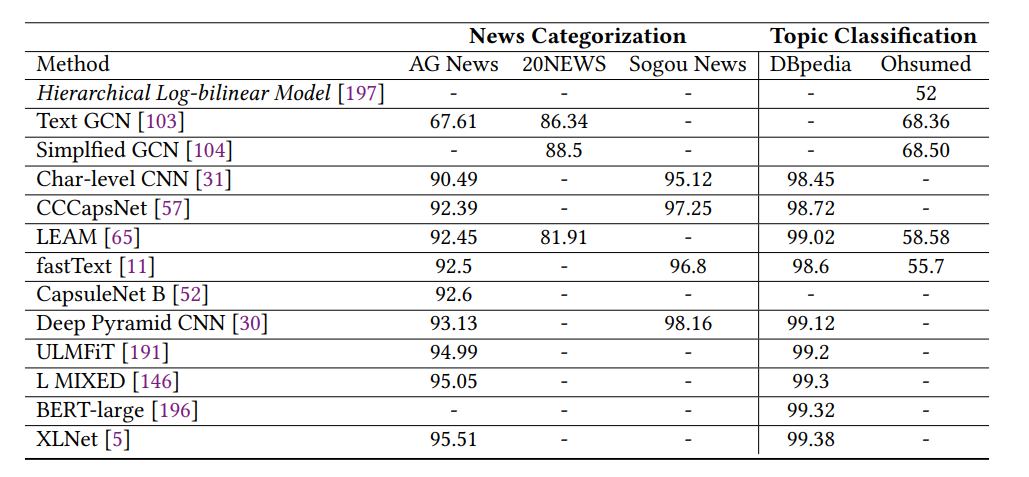
问答结果 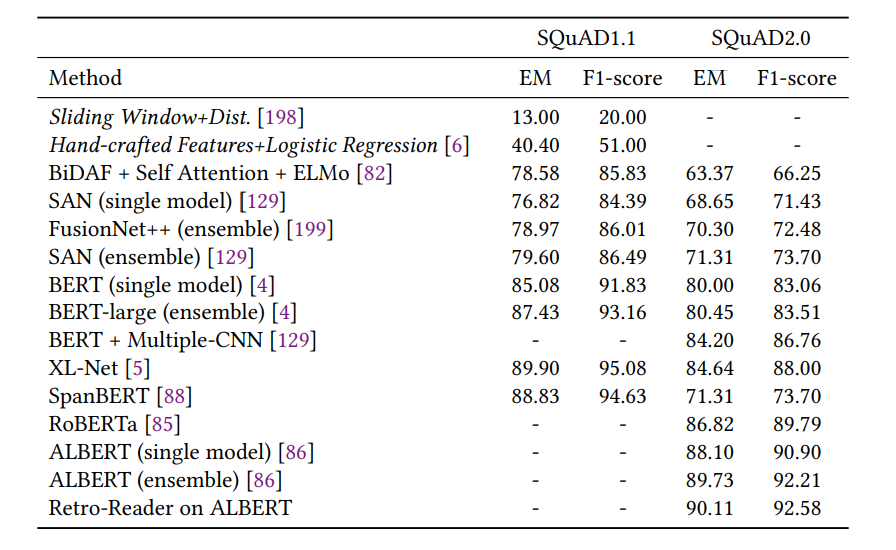
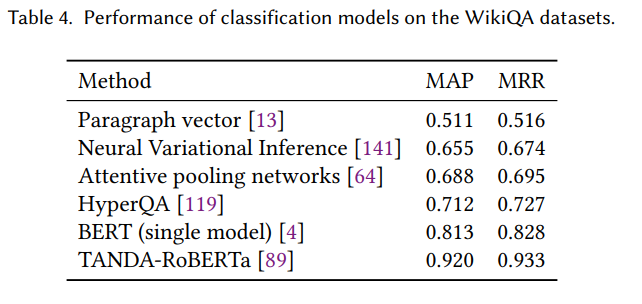
自然语言推理结果 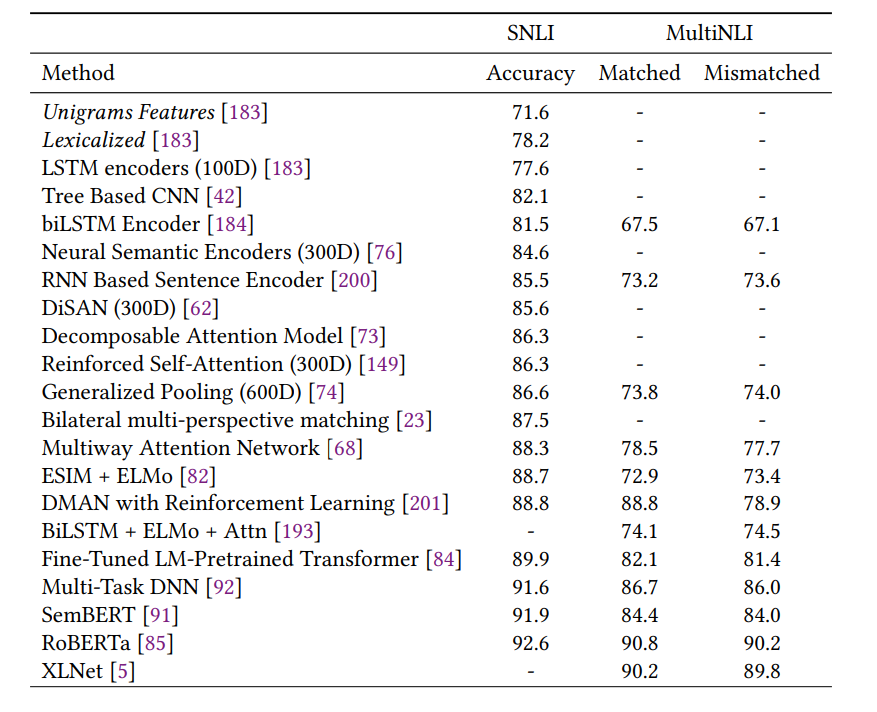
挑战与机遇
更有挑战性的新数据集 常识知识模型化 深度学习模型的可解释性 模型容量高效化 少样本或零样本学习
参考
【1】Deep learning
【2】FASTTEXT.ZIP:COMPRESSING TEXT CLASSIFICATION MODELS
【3】Convolutional Neural Networks for Sentence Classification
【4】Graph Convolutional Networks for Text Classification
【5】Simplifying Graph Convolutional Networks
【6】Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群704220115。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):