
Python改变生活 | OCR识别的花样使用
这是Python改变生活系列的第四篇,在上文中讲了一个需求的解决办法,即用python识别条形码来获取快递单号。
该问题我一共想了两个方案,所以今天接着聊第二种解法。
前情提要
简单的说,我们就是想把截图文件中的快递单号识别出来。
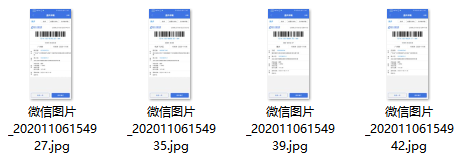
上一种方法将快递单号提取了出来,这次我们希望能用OCR的方法将收件人与单号对应提取。
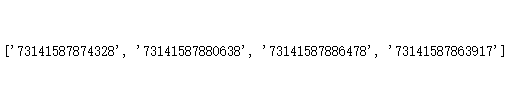
OCR识别
利用Python进行精准文字的识别,我优先推荐百度接口,具体配置步骤可以查看之前的文章。
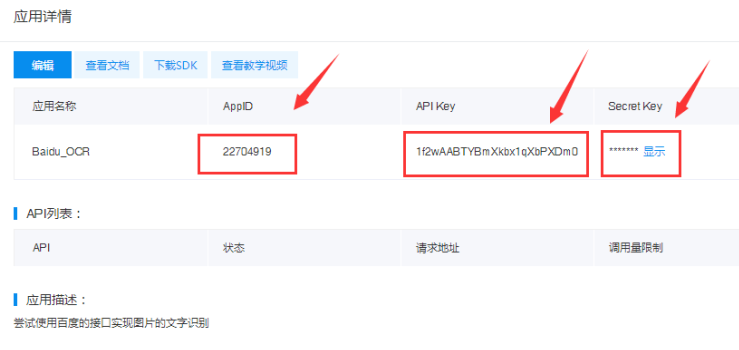
配置成功后,可以得到AppID、API Key、Secret Key等关键信息。
百度OCR后返回的结果是一个列表。
一开始我尝试对整张截图进行识别,再选取结果列表中的元素。结果发现不同截图返回的列表元素数量不一样,也就是说我没办法固定获得想要的值。
最后我又想到了一个折中的办法:即先将截图里的收件人和快递单号部分截取成两个图片,再用百度接口分别识别这两张图片就好了。
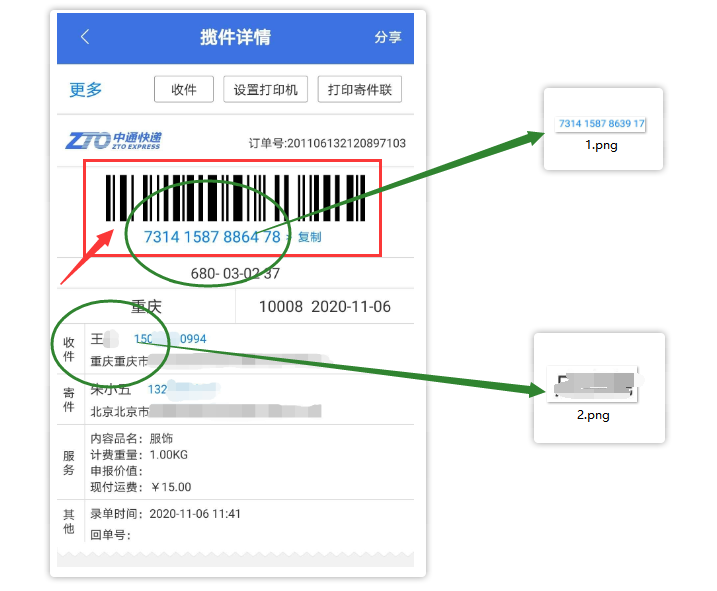
所以我们只需要先构建一个OCR识别单个文字块的函数即可。
#你的 APPID AK SK
APP_ID = '22704919'
API_KEY = '1f2wAABTYBmXkbx1qXbPXDm0'
SECRET_KEY = '**************'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
#百度接口识别
def get_words_result(filePath):
image = open(filePath, 'rb')
image1 = image.read()
text_list = client.general(image1)
text_list = text_list['words_result'][0]['words']
image.close()
return text_list
后续等我们再裁剪了关键图片,直接调用get_words_result()函数就可以识别对应内容。
裁剪图片
裁剪图片这里我使用的是PIL模块,它是python中的第三方图像处理库,可以做很多和图像处理相关的操作。
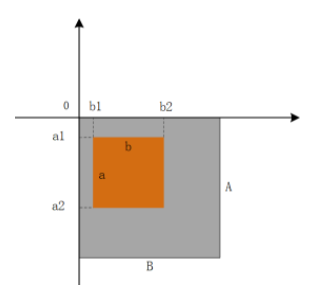
实现裁剪图片,需要在使用时引用Image,使用Image中的open(file)方法可返回打开的图片,再配合crop()函数即可进行裁剪。
crop([x1,y1,x2,y2])
crop里对应的数值为该位置图像在整体图片中左上和右下两个点的像素坐标
具体裁剪+识别语句如下所示:
def get_data(filePath):
img = Image.open(filePath)
ocr_results = []
basic_path = r"D:\python_code\条形码\临时"
crop_1 = img.crop((242,739,678,813)) #crop裁剪
crop_1.save(basic_path+"1.png")
crop_2 = img.crop((88,1052,229,1108)) #crop裁剪
crop_2.save(basic_path+"2.png")
for i in range(1, 3):
imgpath = basic_path + str(i) + '.png'
msg_info = get_words_result(imgpath) #调用函数识别文字
ocr_results.append(msg_info)
os.remove(imgpath) #删除临时裁剪的图片
time.sleep(3)
return ocr_results
我在原文件夹中又新建了一个临时文件夹"D:\python_code\条形码\临时",用来存放临时裁剪的图片12。然后调用ocr函数依次识别两张图片,并将结果存到列表ocr_results中。
最后,使用os模块的remove()函数删除本次临时裁剪生成的两张图片。
批量识别
经过前面的努力,批量识别简直唾手可得。
还是先os遍历图片!这次不再涉及中文路径问题,所以不需要改名操作。
#遍历图片
jpgs = []
path = os.getcwd()
for i in os.listdir(path): #获取文件列表
jpgs.append(i)
#用于储存识别结果
data_m = pd.DataFrame(columns=['expres','sname'])
#批量识别
for i in jpgs:
a = get_data(i)
data_m.loc[len(data_m)] = a
data_m
执行!
当当当!
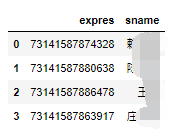
如上图所示,我们不仅将快递单号识别了出来,与之对应的收件人信息也被一应取出👍
对我来说,大大提升了工作效率。

小结
整个案例,我们共使用了两种方法来解决问题,各自都有其优缺点。
第一种,识别条形码100%准确,但其只获得了快递单号。
第二种,识别文字有几率出现问题,优点是可以同时获取对应的收件人信息。
不过小五采用了裁剪关键图片的方法,大大提升了OCR的精准度。最后我自己也是选择了第二种方法,来方便给大家寄书后及时反馈快递单号。

老铁们,如果想看更多Python改变生活的真实问题案例,来给本文右下角点个赞吧👍