
只需1次演示,1小时在线训练,机器人真就做到看一遍就会了
视学算法
共 2498字,需浏览 5分钟
·
2022-07-17 09:06
作者:陈萍、杜伟
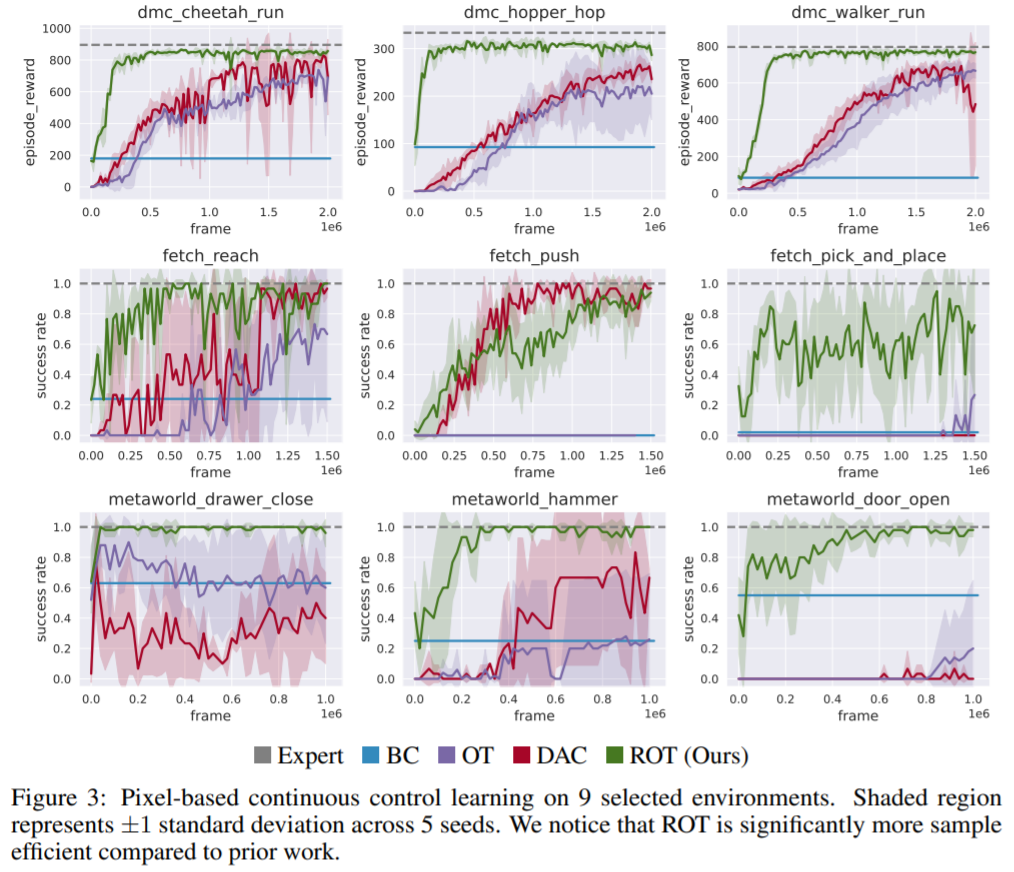
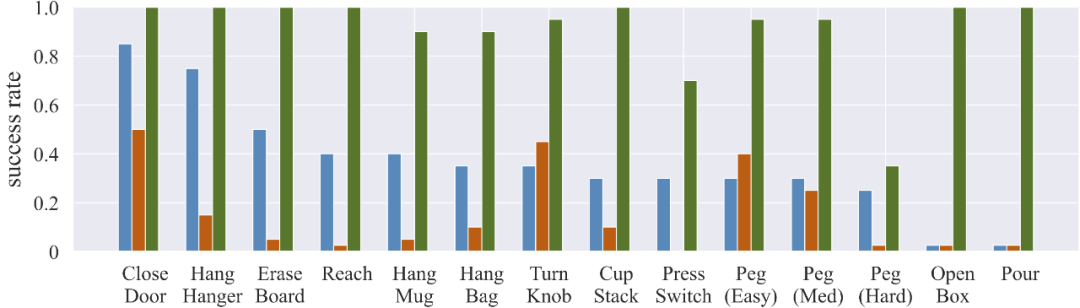
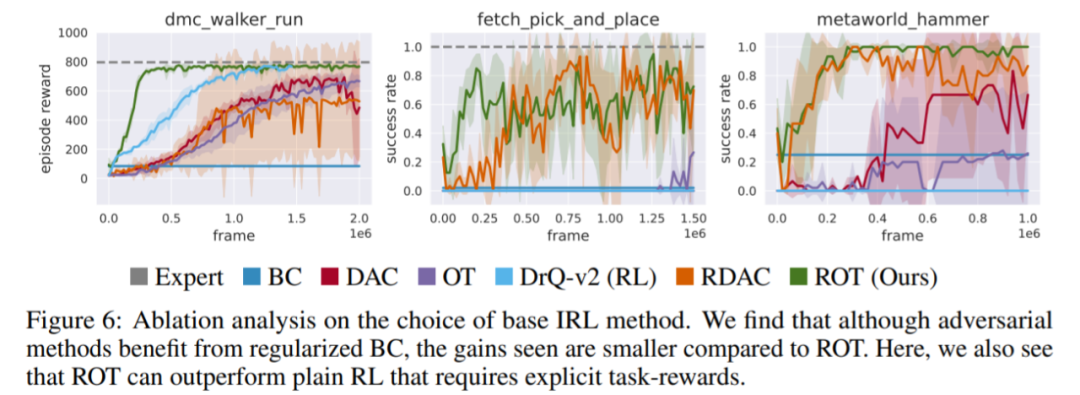
本文提出的用于模仿学习的 ROT 算法,无需任何预训练,在 14 项任务中的平均成功率为 90.1%。

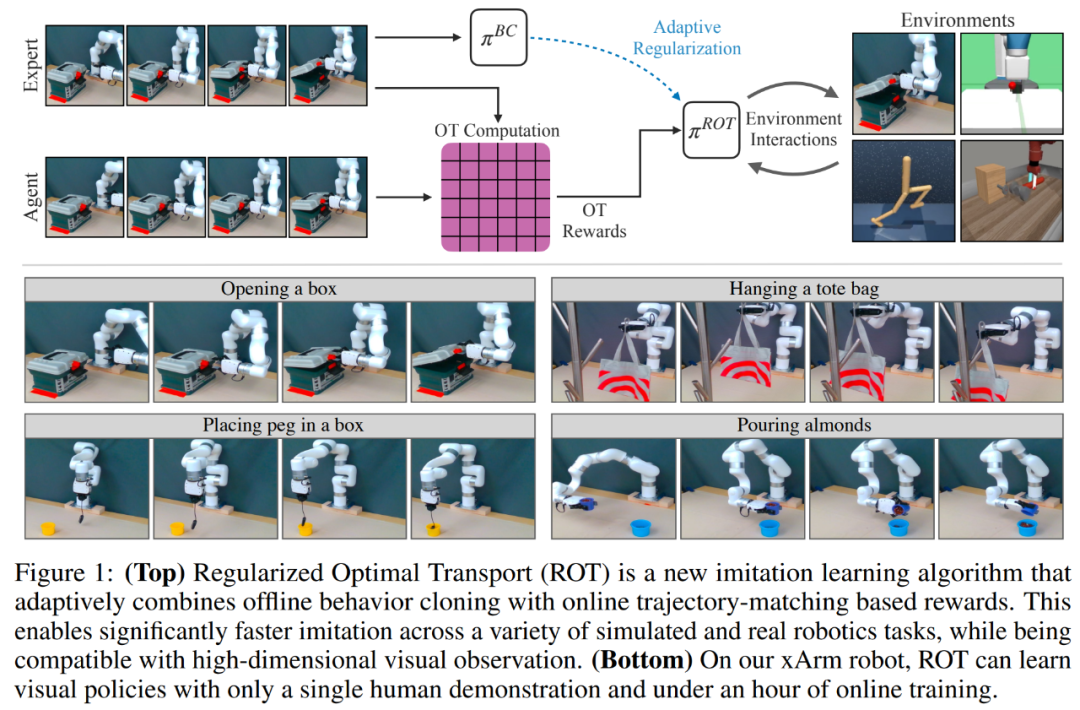



第一阶段,在专家演示数据上使用 BC 目标训练随机初始化策略,然后 BC 预训练策略用作第二阶段的初始化; 第二阶段,BC 预训练策略可以访问使用 IRL 目标进行训练的环境。为了加速 IRL 训练,BC 损失被添加到具有自适应权重目标中。



© THE END
转载请联系原公众号获得授权

点个在看 paper不断!
评论