
干货|Spark优化之高性能Range Join

导 读
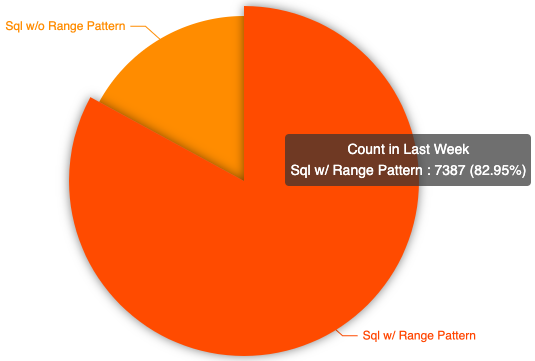
1 背 景
Background



2 Range Join的定义
Definition of Range Join
3 方案设计
Project Design
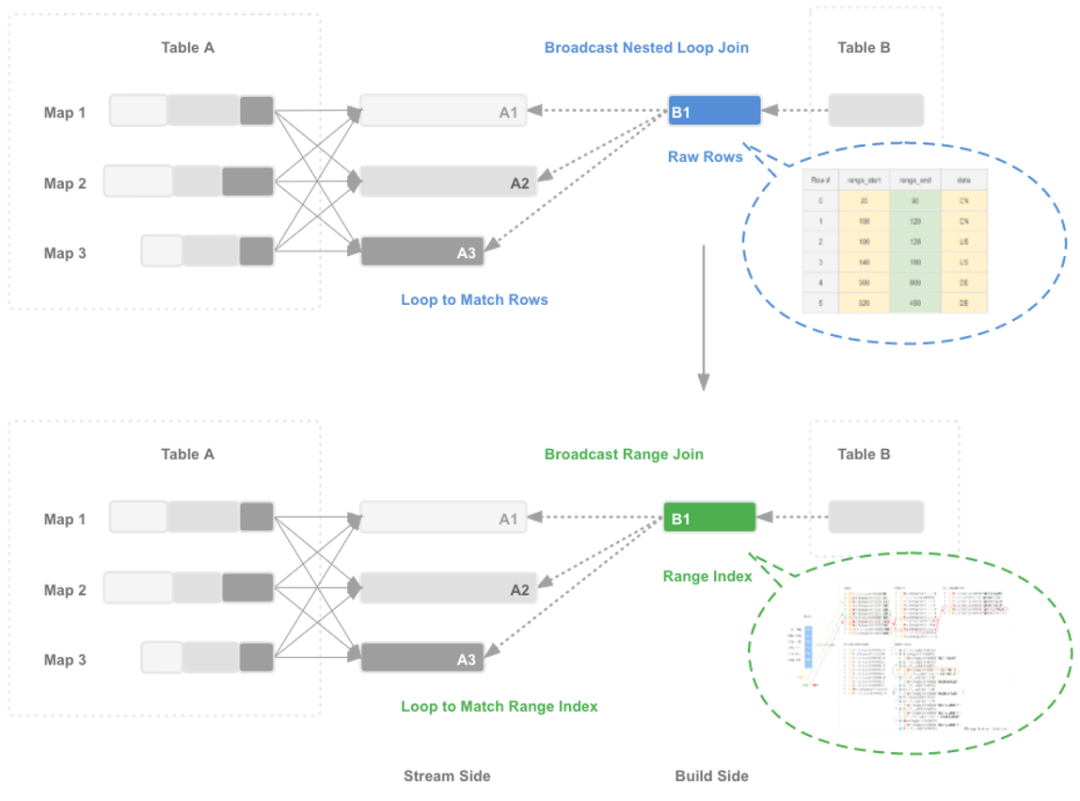
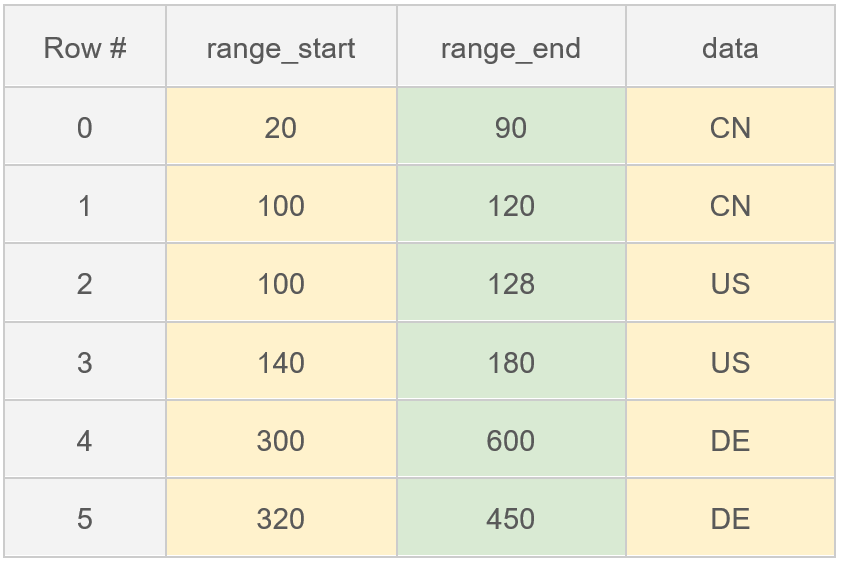
3.1.1 Range Index的创建
3.1.2 Range数据的查找
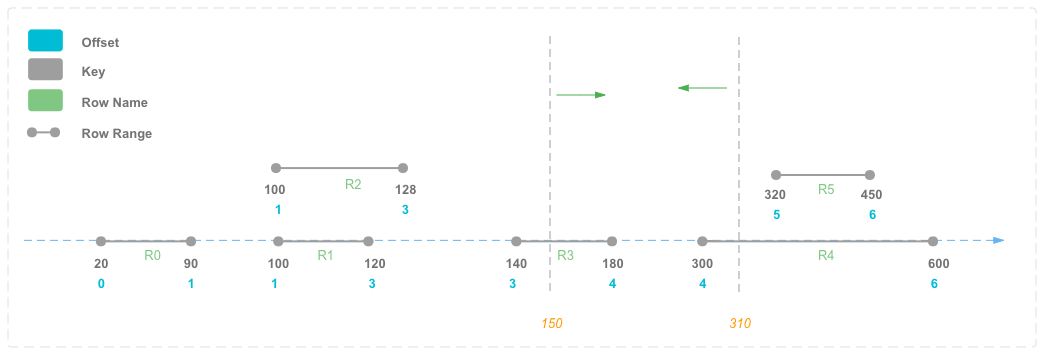
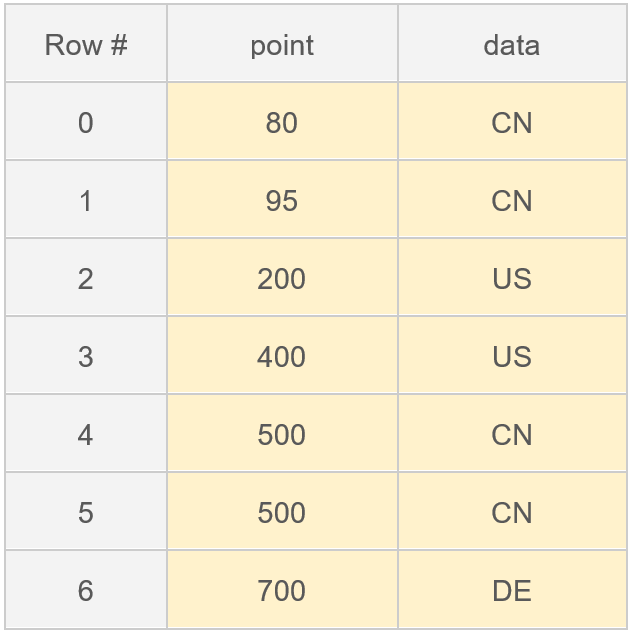
3.2.1 Range Index的创建

3.2.2 Range数据的查找
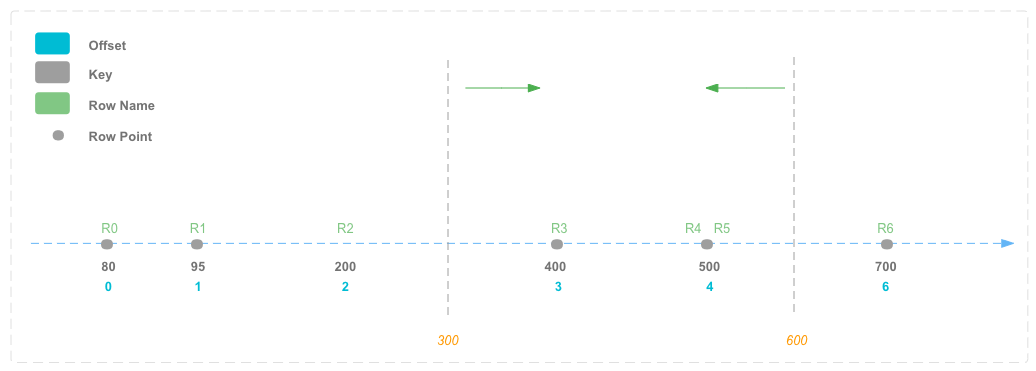
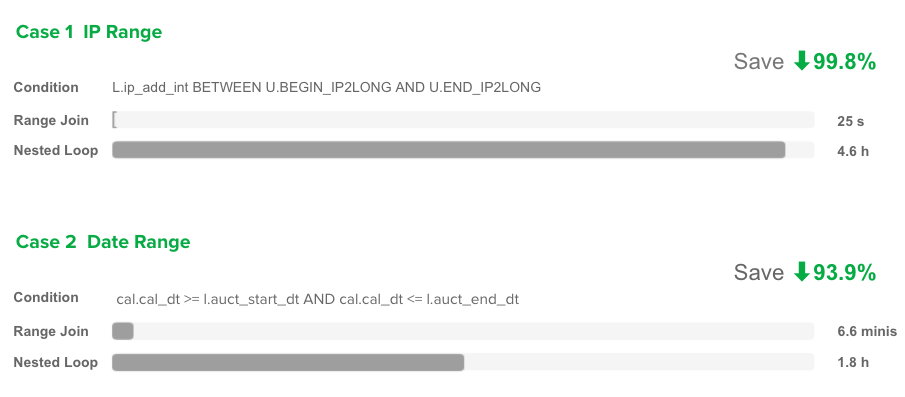
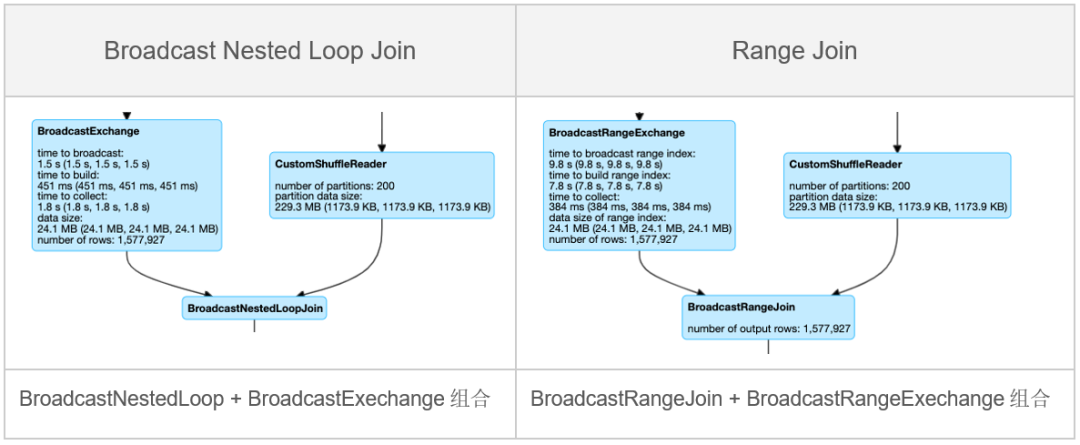
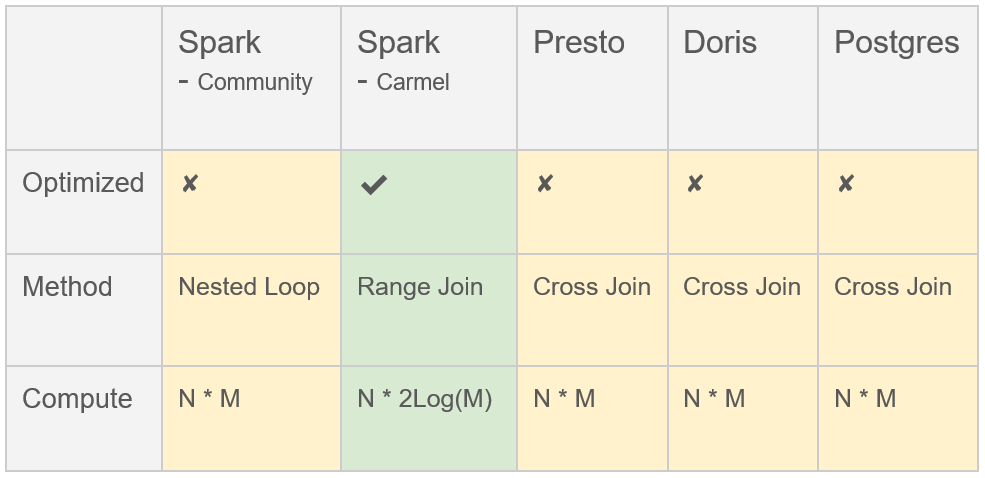
4 性能对比
Performance Comparison
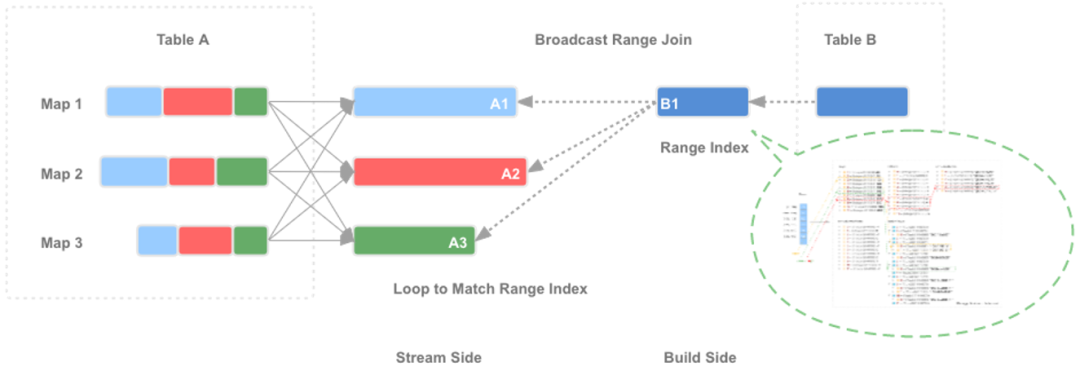
5 实 现
Realize
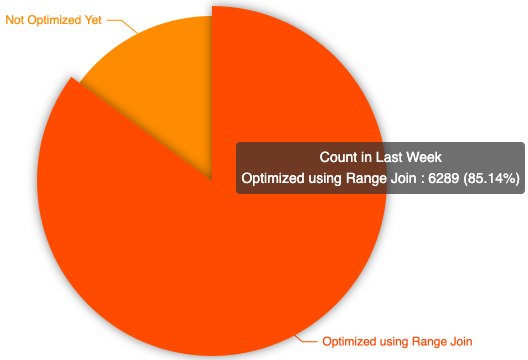





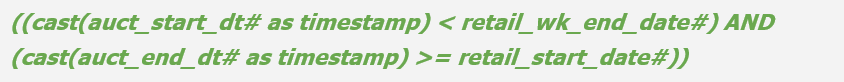
6 总 结
Conclusion
参考链接
[1]https://docs.databricks.com/delta/join-performance/range-join.html
[2]https://issues.apache.org/jira/browse/SPARK-8682
[3]https://www.pilosa.com/blog/range-encoded-bitmaps/
[4]https://www.vertica.com/docs/9.2.x/HTML/Content/Authoring/AnalyzingData/Queries/Joins/RangeJoins.htm
[5]https://link.springer.com/article/10.1007/s00778-021-00692-3
Spark SQL知识点与实战
Hive计算最大连续登陆天数
Hadoop 数据迁移用法详解
数仓建模—宽表的设计
数仓建模分层理论
Flink 是如何统一批流引擎的
评论