
数据中异常值的鉴定和处理(1)
数据预处理中最不想碰到但又绕不过的一个问题是异常样品的鉴定和处理。异常样本,也称为离群样本,其定义是与其它样本有显着差异的样本。通常是由实验操作失败、样本受损等不易发现的外部因素引起,比如样本被污染了、细胞死亡了、细胞破损了、动物个体遗传背景不符、抗体特异性差、核酸提取不纯、RNA降解、测序质量差、测序深度很低等。异常样本的存在会干扰数据分析结果的稳定性,常见统计指标非常容易受到异常值的影响,例如均值、方差和相关性等。相比于保留更多的样本,我们更希望保留质量更高的样本 (这也要求我们测序重复要较多,不然只有2重复,去掉一个就没法分析了)。
异常样本有什么特征?异常样在数据上体现在与其它所有样本都差别比较大,比如样品GC含量异常、比对率远低于低于中位比对率、基因表达量整体都特别高或几乎都为0、菌的构成很异常、与同组样品差别大、检测到的基因数异常多或异常少、单细胞里面还会考虑线粒体基因的表达比例等。
现在又到了另一个问题,这些是很好的指标,但阈值怎么设置?
如果和导师说这个样本异常,然后被灵魂质问,你以为你以为的就是你以为的吗。那我们如何来有效地发现和定义异常样本呢?
聚类结果判断异常样本
一般可以通过层级聚类树或PCA的方式查看是否存在异常样品,但具体判断哪个样品是异常样本缺乏明确的标准。如下面左图展示的是数据中混入了异常样本(图中蓝框)后数据聚类成一大一小两个分支,51-52一枝,其它样品一枝。我们现在判定51-52为异常样本,把它们去除,图就变成了右侧的样子,变成两个大分支,左侧分支的样品42要被判断为异常样本吗?没有答案。

异常值的判定 Z-score方法
我们先从最简单的情况看起,假如有一组数,-10,10,20,3,1,3,3,4,4,4,4,5,6,7,100, 哪个数字看起来最异常呢?异常值的定义是与其余数据有显著差异的数据,看上去应该是100,怎么计算一下呢?
如果数据主体符合正态分布,一般使用Z-score的方法。Z-score (也称standard score) 代表一个给定的测量值偏离平均值多少倍的标准差,其正值代表大于平均值,负值代表小于平均值。计算方式如下:

在异常值检测时,一般认为偏离3倍标准差以上为异常值:
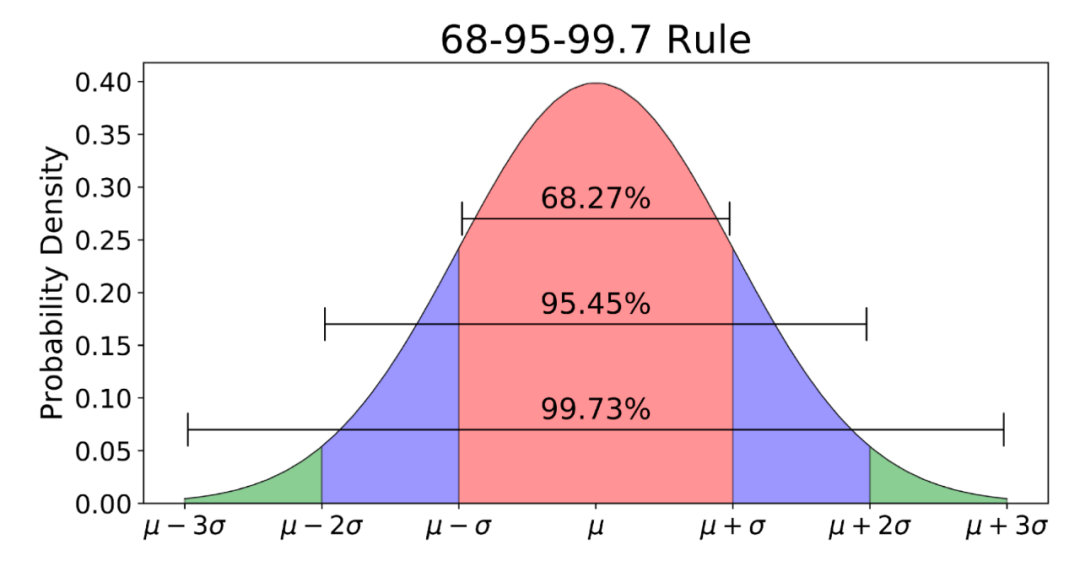
在R中简单实现如下:
set.seed(1)
ysx <- c(round(c(rnorm(30)),1),10)
ysx[1] -0.6 0.2 -0.8 1.6 0.3 -0.8 0.5 0.7 0.6 -0.3 [11] 1.5 0.4 -0.6 -2.2 1.1 0.0 0.0 0.9 0.8 0.6 [21] 0.9 0.8 0.1 -2.0 0.6 -0.1 -0.2 -1.5 -0.5 0.4 [31] 10.0
ysx_scale <- round(as.vector(scale(ysx)),1)
ysx_scale[1] -0.5 -0.1 -0.6 0.6 -0.1 -0.6 0.1 0.2 0.1 -0.4 [11] 0.6 0.0 -0.5 -1.3 0.4 -0.2 -0.2 0.3 0.2 0.1 [21] 0.3 0.2 -0.2 -1.2 0.1 -0.3 -0.3 -1.0 -0.5 0.0 [31] 4.8
另外也可用中位数和中位绝对偏差代替,结果更稳定一些
set.seed(1)
ysx <- c(round(c(rnorm(30)),1),10)
ysx
ysx_mad = mad(ysx)
ysx_median = median(ysx)
ysx_scale = round((ysx-ysx_median) / ysx_mad,1)
ysx_scale_outlier <- abs(ysx_scale) >=3
ysx_scale_outlier[1] -0.6 0.2 -0.8 1.6 0.3 -0.8 0.5 0.7 0.6 -0.3 [11] 1.5 0.4 -0.6 -2.2 1.1 0.0 0.0 0.9 0.8 0.6 [21] 0.9 0.8 0.1 -2.0 0.6 -0.1 -0.2 -1.5 -0.5 0.4 [31] 10.0
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE [9] FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE [17] FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE [25] FALSE FALSE FALSE FALSE FALSE FALSE TRUE
那么这个怎么应用到鉴定异常样本之间呢?度量不同样本之间的相似度可以使用Pearson correlation或Spearman corelation值等。如果一个样本与其他样本相似度都很低,低于3倍的标准差,则可视为异常样品。这个怎么算呢?下文再说!
Z-score也常用于热图美化中:R语言学习 - 热图美化 (数值标准化和调整坐标轴顺序)
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|



























后台回复“生信宝典福利第一波”或点击阅读原文获取教程合集

(请备注姓名-学校/企业-职务等)