
FastFormers:实现Transformers在CPU上223倍的推理加速
点击上方,选择星标或置顶,不定期资源大放送 !
!
阅读大概需要5分钟
Follow小博主,每天更新前沿干货


作者:Parth Chokhra
编译:ronghuaiyang
使用多头注意力的Transform在cpu上实现222倍的加速。

自BERT紧随Transformer诞生以来,几乎在所有与语言相关的任务中都占据着主导地位,无论是问答、情感分析、文本分类还是文本生成。与RNN和LSTM不一样的是,RNN和LSTM的梯度消失问题阻碍了长数据序列的学习,而transformer在所有这些任务上都有更好的准确性。也不像Transformers,RNN和LSTM是不可扩展的,因为它们必须考虑到前一个神经元的输出。
现在Transformers的主要问题是它们在训练和推理方面都是高度密集的计算。而训练部分可以通过使用预训练的语言模型(由大型公司如谷歌,Facebook和OpenAI😏开放源代码)并在我们的数据集上微调它们来解决。现在,后一个问题由FastFormers解决了,有一套方法可以实现基于Transformers的模型在各种NLU任务上的高效推理。
“将这些建议的方法应用到SuperGLUE基准测试中,与开箱即用的CPU模型相比,作者能够实现9.8倍到233.9倍的加速。在GPU上,我们也实现了12.4倍的加速。" — FastFormers
论文FastFormers: Highly Efficient Transformer Models for Natural Language Understanding主要关注于为Transformer模型提供高效推理,使其能够在大规模生产场景中部署。作者特别关注推断时间效率,因为它主要控制着生产部署的成本。在这篇博客中,我们将回顾本文所要解决的所有问题和挑战。
那么他们是如何解决Transformers高效率推理时间的问题的呢?
它们主要利用知识蒸馏、结构化剪枝和模型量化三种方法。
第一步,知识蒸馏,减少模型深度和隐藏状态的大小,而不影响精度。
第二,结构化修剪,通过减少自注意力头的数量,减少模型的大小,同时试图保持准确性。
最后,模型量化,通过优化利用硬件加速能力使模型可以更快的执行。CPU上采用8bit量化方法,GPU上将所有模型参数转换为16位浮点数据类型,最大限度地利用高效Tensor Cores。
深入介绍
知识蒸馏:知识蒸馏指的是模型压缩的思想,使用一个更大的已经训练有素的网络教一个较小的网络,一步一步地,确切地做什么得到较小的模型。虽然大模型比小模型具有更高的知识容量,但这一容量可能没有得到充分利用。即使模型只利用了很少的知识能力,它在计算上也可能是昂贵的。知识蒸馏将知识从一个大模型转移到一个小模型而不失去有效性。由于较小的模型评估成本较低,它们可以部署在功能较弱的硬件上,比如智能手机。
知识蒸馏方法:特别使用了两种方法,即特定于任务的和与任务无关的蒸馏。
在任务细化过程中,作者按照TinyBERT提出的步骤,将教师模型细化为更小的学生模型。在与任务无关的蒸馏方法中,作者直接对一般蒸馏模型进行微调,以针对特定的任务进行调优。
知识蒸馏结果:在实验中,作者观察到,蒸馏模型在蒸馏到另一种模型类型时,不能很好地工作。因此,作者限制了我们的设置,以避免将Roberta模型蒸馏为BERT模型,反之亦然。通过验证数据集上的教师模型,我们汇总了对任务进行知识蒸馏的结果。(学生指蒸馏模型)

神经网络剪枝:神经网络剪枝是一种压缩方法,包括从训练模型中删除权值。在农业中,修剪是指砍掉植物不必要的枝干。在机器学习中,剪枝是去除不必要的神经元或权重。神经网络剪枝技术可以使训练网络的参数减少90%以上,在不影响精度的前提下减少存储需求,提高推理的计算性能。这有助于减小经过训练的神经网络的大小或能量消耗,并有助于使推理更有效。剪枝使网络更高效、更轻。
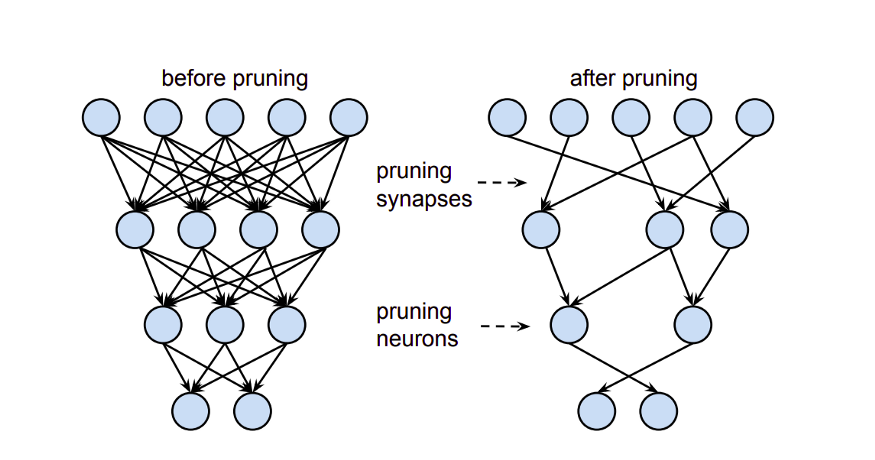
结构化剪枝方法:我们的结构化剪枝方法的第一步是识别多头注意力中最不重要的头和前馈层中最不重要的隐藏状态。
计算重要性得分的一阶方法,利用一阶梯度信息代替了基于幅度的剪枝。 在进行重要性评分计算之前,作者在每个注意力头中添加了一个mask变量,用于注意力头的梯度计算。然后在整个验证数据集上前后遍历模型,积累梯度的绝对值。然后,这些累积的值被用作重要分数,我们用它来排序注意力头和中间隐藏状态的重要性。 根据目标模型的大小,从网络中选择给定数量的顶部heads和顶部隐藏状态。一旦排序和选择步骤完成,作者重新组合和连接剩余的head和隐藏状态,从而得到一个较小的模型。当对head和隐藏状态进行剪枝时,作者在不同的层中使用相同的剪枝率。这使得进一步的优化能够与修剪后的模型无缝地工作。 在实验中,作者发现,经过修剪后的模型经过新一轮的知识蒸馏后,可以获得更好的精度。因此,将知识蒸馏再次应用到模型中。
模型量化:量化是指在比浮点精度更低的位宽下执行计算和存储张量的技术。量化模型对用整数而不是浮点值的张量执行部分或全部操作。这允许一个更紧凑的模型表示,并在许多硬件平台上使用高性能向量化操作。
在CPU上的8bit量化矩阵乘法:由于减少了CPU指令数量,8bit量化矩阵乘法与32位浮点运算相比带来了显著的速度提升。
16bitGPU模型转换:V100 GPU支持Transformer架构的完整16bit操作。另外,16bit浮点运算除了具有较小的值范围外,不需要对输入和输出进行特殊处理。由于Transformer模型是受内存带宽限制的工作负载,这种16bit模型转换带来了相当显著的速度增益。观察到大约3.53倍的加速,取决于模型设置。
除了结构优化和数值优化,作者还利用各种方法进一步优化计算,特别是多进程优化和计算图优化。
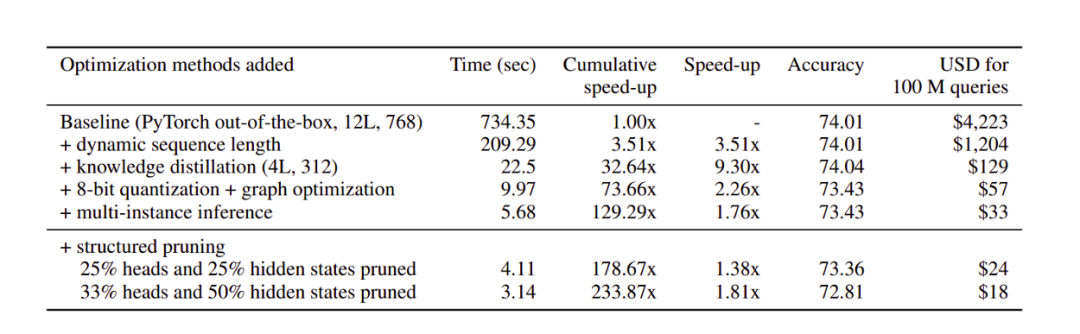
组合起来的结果
下面的表格说明了结果是多么有效:
总结
本文介绍了FastFormers,它能对基于Transformer的模型在各种NLU任务上实现高效的推理时间性能。论文FastFormers的作者表明,利用知识蒸馏、结构化剪枝和数值优化可以大幅提高推理效率。我们表明,这种改进可以达到200倍的加速,并在22倍的能耗下节省超过200倍的推理成本。

英文原文:https://medium.com/ai-in-plain-english/fastformers-233x-faster-transformers-inference-on-cpu-4c0b7a720e1
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。
记得备注呦
整理不易,还望给个在看!