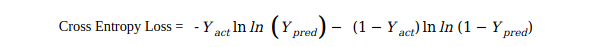目标检测中焦点损失的原理
共
4224字,需浏览
9分钟
·
2020-09-20 10:51
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
对象检测是计算机视觉社区中研究最广泛的主题之一,它已经进入了各个行业,涉及从图像安全,监视,自动车辆系统到机器检查等领域。- 两级检测器,例如基于区域检测的CNN(R-CNN)及其后续产品。
基于锚框的常规一级检测器可能会更快,更简单,但由于在训练过程中遇到极端的等级失衡,其精度已经落后于两级探测器。FAIR在2018年发表了一篇论文,其中他们引入了焦点损失的概念,使用他们称之为RetinaNet的一级探测器来处理此类不平衡问题。在我们深入探讨焦点损失(Focal Loss)的本质之前,让我们首先了解这个类不平衡问题是什么以及它可能引起的问题。目录
为什么需要焦点损失
两种经典的一级检测方法,如增强型检测器,DPM和最新的方法(如SSD)都可以评估每个图像大约10^4 至 10^5个候选位置,但只有少数位置包含对象(即前景),而其余的只是背景对象,这就导致了类不平衡的问题。- 训练效率低下,因为大多数位置都容易被判断为负类(这意味着检测器可以轻松地将其归类为背景),这对检测器的学习没有帮助。
- 容易产生的负类(概率较高的检测)占输入的很大一部分。虽然单独计算的梯度和损失较小,但它们可能使损耗和计算出的梯度不堪重负,并可能导致模型退化。
什么是焦点损失
简而言之,焦点损失(Focal Loss,FL)是交叉熵损失(Cross-Entropy Loss,CE)的改进版本,它通过为难分类的或容易错误分类的示例(即带有噪声纹理的背景或部分对象的或我们感兴趣的对象)分配更多的权重并对简单示例(即背景对象)降低权重来处理类不平衡问题。因此,焦点损失减少了简单示例的损失贡献,并加强了对纠正错误分类示例的重视。交叉熵损失
交叉熵损失背后的思想是惩罚错误的预测,而不是奖励正确的预测。为了标记方便,我们记 Yact = Y 且 Ypred = p 。p∈[0,1],是模型对Y = 1的类别的估计概率。pt = {-ln(p) ,当Y=1 -ln(1-p) ,当 Y=}交叉熵问题
如你所见,下图中的蓝线表示当p非常接近0(当Y = 0时)或1时,容易分类的pt > 0.5的示例可能会产生不小幅度的损失。例子
假设,前景(我们称其为类1)正确分类为p = 0.95 ——并且背景(我们称其为类0)正确分类为p = 0.05 ——CE(BG)=-ln(1- 0.05)= 0.05现在问题是,对于类不平衡的数据集,当这些小的损失在整个图像上相加时,可能会使整体损失(总损失)不堪重负,将导致模型退化。平衡交叉熵损失
解决类别不平衡问题的一种常见方法是为类别引入权重因子∝[0,1]为了标记方便,我们可以在损失函数中定义 ∝t 如下:平衡交叉熵的问题
我们的实验将表明,在密集检测器训练过程中遇到的大类不平衡压倒了交叉熵损失。容易分类的负类占损耗的大部分,并主导梯度。虽然平衡了正例/负例的重要性,但它并没有区分简单/困难的示例。例子
假设,前景(我们称其为类1)正确分类为p = 0.95 ——CE(FG)= -0.25 * ln(0.95)= 0.0128正确分类为p = 0.05的背景(我们称之为类0)——CE(BG)=-(1-0.25)* ln(1- 0.05)= 0.038虽然可以很好地正确区分正类和负类,但仍然不能区分简单/困难的样本。焦点损失说明
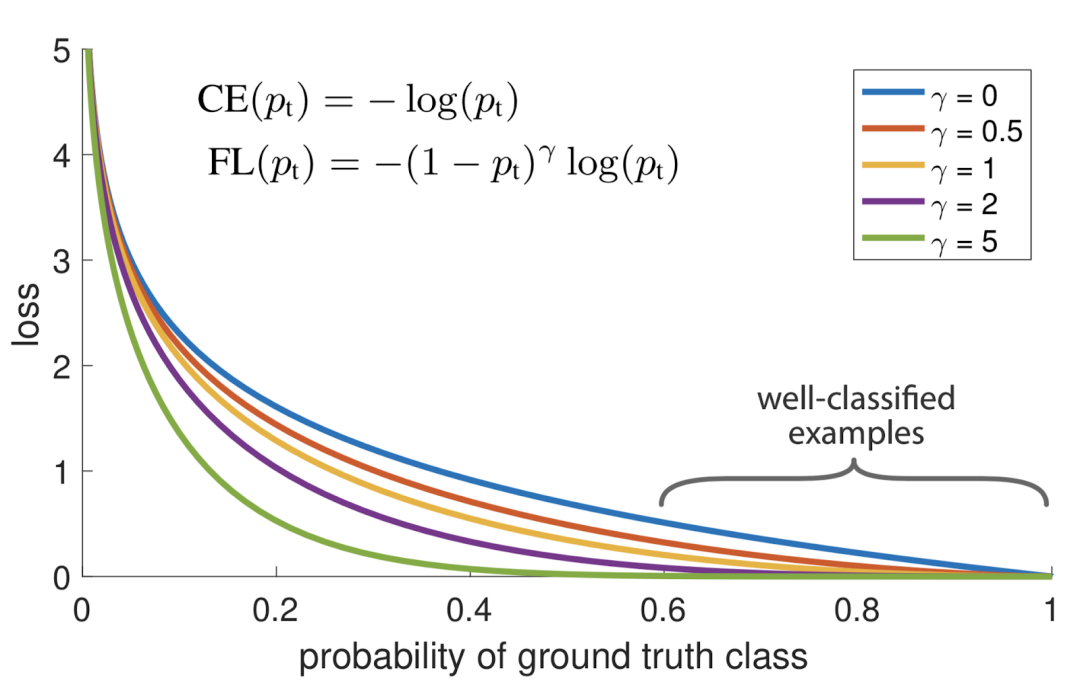
焦点损失只是交叉熵损失函数的扩展,它将降低简单示例的权重,并将训练重点放在困难的负样本上。为此,研究人员提出:(1- pt)γ 为交叉熵损失,且可调聚焦参数γ≥0。RetinaNet物体检测方法使用焦点损失的α平衡变体,其中α = 0.25,γ= 2效果最佳。FL (pt) = -αt(1- pt)γ log log(pt).对于γ∈[0,5]的几个值,可以看到焦点损失,请参见图1。- 当示例分类错误并且pt小时,调制因数接近1,并且损失不受影响。
- 当 pt →1 时,该因子变为0,并且对分类良好的示例的损失进行了权衡。
随着增加,调制因数的作用同样增加。(经过大量实验和试验,研究人员发现γ = 2效果最佳)注意:当γ= 0时,FL等效于CE,参考图中蓝色曲线。直观上,调制因数减少了简单示例的损耗贡献,并扩展了示例接收低损耗的范围。例子
1.前景正确分类,预测概率p=0.99,背景正确分类,预测概率p=0.01。pt = {0.99,当Yact = 1 时; 1-0.01,当Y act = 0时},调制因数(FG)=(1-0.99)2 = 0.0001
,调制因数(BG)=(1-(1-0.01))2 = 0.0001,如你所见,调制因数接近于0,因此损耗将被权重降低。2.前景被错误分类,预测概率p = 0.01,背景对象被错误分类,预测概率p = 0.99。pt = {0.01,当Yact = 1 时; 1-0.99,当Y act = 0时},调制因数(FG)=(1-0.01)2 = 0.9801
,调制因数(BG)=(1-(1-0.99))2 = 0.9801,如你所见,调制因数接近于1,因此损耗不受影响。现在,让我们使用一些示例来比较交叉熵和焦点损失,并查看焦点损失在训练过程中的影响。交叉熵损失 vs 焦点损失
容易正确分类的记录
假设前景正确分类的预测概率为p = 0.95,背景正确分类的背景为预测概率p = 0.05。pt = {0.95, 当 Yact=1时;1-0.05 ,当 Yact = 0时}, CE(FG)= -ln (0.95) = 0.0512932943875505,让我们考虑在∝ = 0.25和γ= 2时的焦点损失。FL(FG)= -0.25 * (1-0.95)2 * ln (0.95) = 3.2058308992219E-5FL(BG)= -0.75 * (1-(1-0.05))2 * ln (1-0.05) = 9.61E-5分类错误的记录
假设预测概率p=0.05的前景被分类为预测概率p=0.05的背景对象。pt = {0.95,当Y act = 1;1-0.05时,当Y act = 0时},CE(FG)= -ln(0.05)= 2.995732273553991CE(BG)= -ln(1-0.95)= 2.995732273553992FL(FG)= -0.25 * (1-0.05)2 * ln(0.05)= 0.675912094220619,FL(BG)= -0.75 * (1-(1-0.95))2 * ln(1-0.95)= 2.027736282661858非常容易分类的记录
假设对预测概率p=0.01的背景对象,用预测概率p=0.99对前景进行分类。pt = {0.99, 当 Yact=1时;1-0.01 ,当 Yact = 0时},CE(FG)= -ln (0.99)= 0.0100503358535014,CE(BG)= -ln(1-0.01)= 0.0100503358535014FL(FG)= -0.25 * (1-0.01)2 * ln(0.99)= 2.51 * 10 -7,FL(BG)= -0.75 * (1-(1-0.01))2 * ln(1-0.01) = 7.5377518901261E-7最后的想法
方案1:0.05129 / 3.2058 * 10 -7 =小1600倍方案3:0.01 / 0.00000025 =小40,000倍。这三个案例清楚地说明了焦点损失是如何减小分类良好记录的权重的,另一方面又为错误分类或较难分类的记录赋予较大的权重。经过大量的试验和实验,研究人员发现 ∝ = 0.25和 γ = 2 效果最佳。尾注
在本文,我们经历了从交叉熵损失到焦点损失的整个进化过程,详细解释了目标检测中的焦点损失。参考
- https://arxiv.org/ftp/arxiv/papers/2006/2006.01413.pdf
- https://medium.com/@14prakash/the-intuition-behind-retinanet-eb636755607d
- https://developers.arcgis.com/python / guide / how-retinanet-works /
参考链接:https://www.analyticsvidhya.com/blog/2020/08/a-beginners-guide-to-focal-loss-in-object-detection/
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报