
实时数仓的过去现在和未来
企业为什么需要实时数据仓库
数据处理流程
ODS:Operation Data Store,也称为贴源层。数据仓库源头系统的数据表通常会原封不动的存储一份,这称为ODS层,是后续数据仓库加工数据的来源。 DW数据分层,由下到上一般分为DWD,DWB,DWS。 DWD:Data Warehouse Details 细节数据层,是业务层与数据仓库的隔离层。主要对ODS数据层做一些数据清洗(去除空值、脏数据、超过极限范)和规范化的操作。 DWB:Data Warehouse Base 数据基础层,存储的是客观数据,一般用作中间层,可以认为是大量指标的数据层。 DWS:Data Warehouse Service 数据服务层,基于DWB上的基础数据,主要是对用户行为进行轻度聚合,整合汇总成分析某一个主题域的服务数据层,一般是宽表。用于提供后续的业务查询,OLAP分析,数据分发等。 数据服务层/应用层(APP/DWA):该层主要是提供数据产品和数据分析使用的数据,我们通过说的报表数据,或者说那种大宽表,一般就放在这里。
实时数仓的常见方案
LAMBDA & KAPPA 实时架构
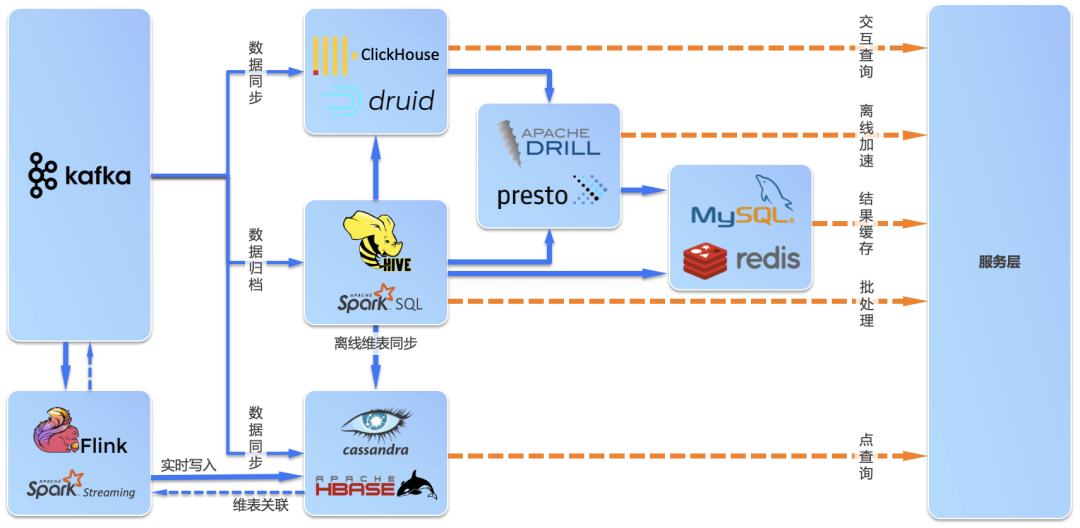

湖仓一体能否解决实时问题?
实时性成为了提升企业竞争力的核心手段。目前的湖、仓、或者湖仓分体都是基于 T+1 设计的,面对 T+0 的实时按需分析,用户的需求无法满足。 所有用户(BI 用户、数据科学家等)可以共享同一份数据,避免数据孤岛。 超高并发能力,支持数十万用户使用复杂分析查询并发访问同一份数据。 传统 Hadoop 在事务支持等方面的不足被大家诟病,在高速发展之后未能延续热度,持续引领数据管理,因此事务支持在湖仓一体架构中应得到改善和提升。 云原生数据库已经逐渐成熟,基于存算分离技术,可以给用户带来多种价值:降低技术门槛、减少维护成本、提升用户体验、节省资源费用,已成为了湖仓一体落地的重要法门。 为释放数据价值提升企业智能化水平,数据科学家等用户角色必须通过多种类型数据进行全域数据挖掘,包括但不限于历史的、实时的、在线的、离线的、内部的、外部的、结构化的、非结构化数据。
云原生数据仓库 + Omega实时架构 实现实时湖仓
云原生数据库实现完全的存算分离
基于Omega实时框架的湖仓方案
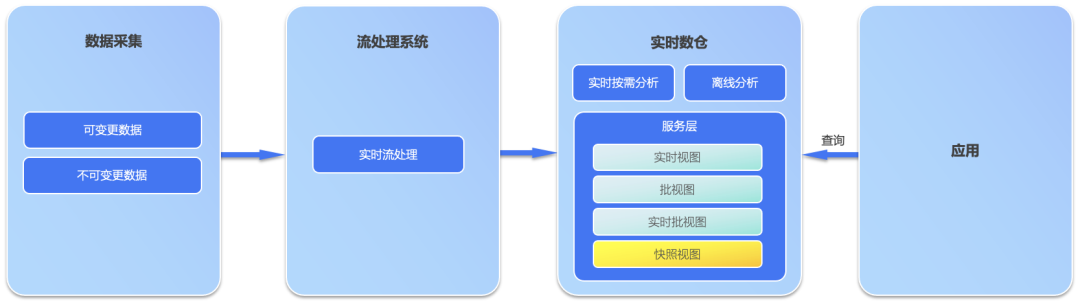 Omega 架构逻辑图
Omega 架构逻辑图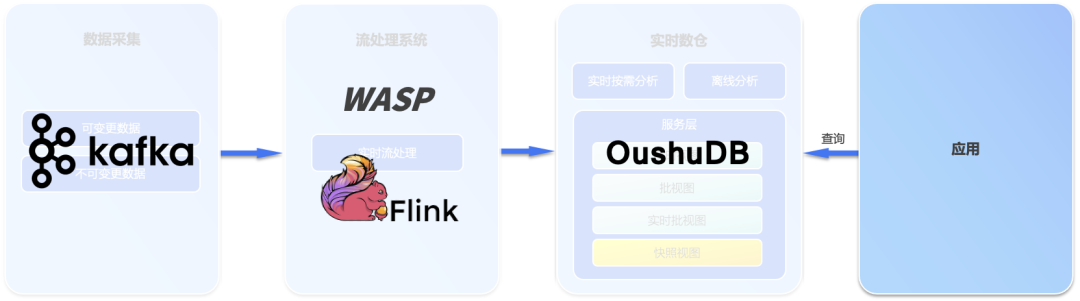
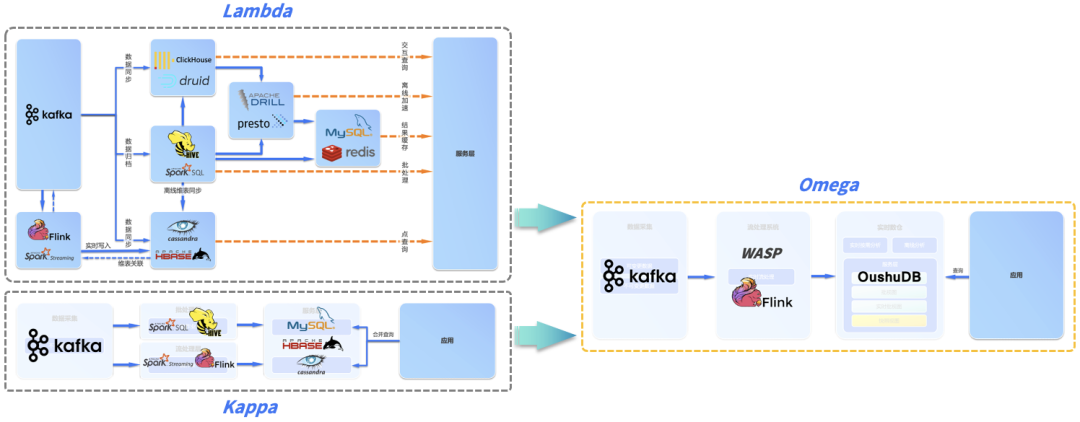
结语:
架构层面要保持灵活开放,支持多种技术兼容性并存。目前,企业已经部署了多个系统,有自己的一套架构体系,技术融合落地时需要最大化利用企业原有IT资产,保护客户投资。 有效利用资源,降本增效。原来传统的技术栈,所有资源参与计算,造成IT资源浪费。比如,云原生资源池化,可以实现资源隔离与动态管理,便于最大化利用资源。 满足更高的用户体验。从用户角度来看,在技术条件具备的前提下,比如高性能、高并发、实时性更强,便具备了更强的信息加工能力,能够在很短的时间内满足用户各种各样的数据服务需求,提升用户体验。
评论