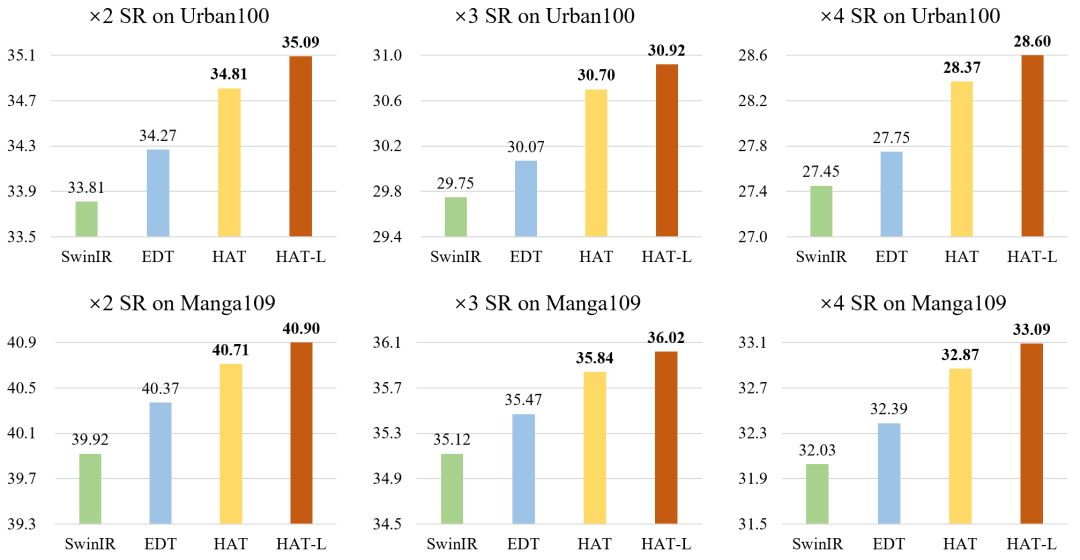本文约2500字,建议阅读5分钟
本文介绍作者提出的一种基于混合注意机制的Transformer(Hybrid Attention Transformer, HAT)。
基于Transformer的大模型以及预训练技术近年来吸引了众多计算机视觉研究者的注意。其中的底层视觉任务,IPT [1], SwinIR [2], EDT [3]这三种方法也已经展现出了令人印象深刻的性能。
近日,来自澳门大学、中国科学院深圳先进技术研究院等机构的XPixel团队研究人员通过分析和实验指出,目前的方法无论是在模型设计,还是预训练策略上,都仍存在较大的提升空间。
团队主页:http://xpixel.group/为此,作者提出了一种基于混合注意机制的Transformer (Hybrid Attention Transformer, HAT)。该方法结合了通道注意力,自注意力以及一种新提出的重叠交叉注意力等多种注意力机制。此外,还提出了使用更大的数据集在相同任务上进行预训练的策略。
论文链接:https://arxiv.org/abs/2205.04437
项目链接:https://github.com/chxy95/HAT
实验结果显示,本文提出的方法在图像超分辨率任务上大幅超越了当前最先进方法的性能(超过1dB),如图1所示。图1. HAT与当前SOTA方法SwinIR和EDT的性能对比
HAL-L表示在HAT的基础上深度增加一倍的更大容量的模型。
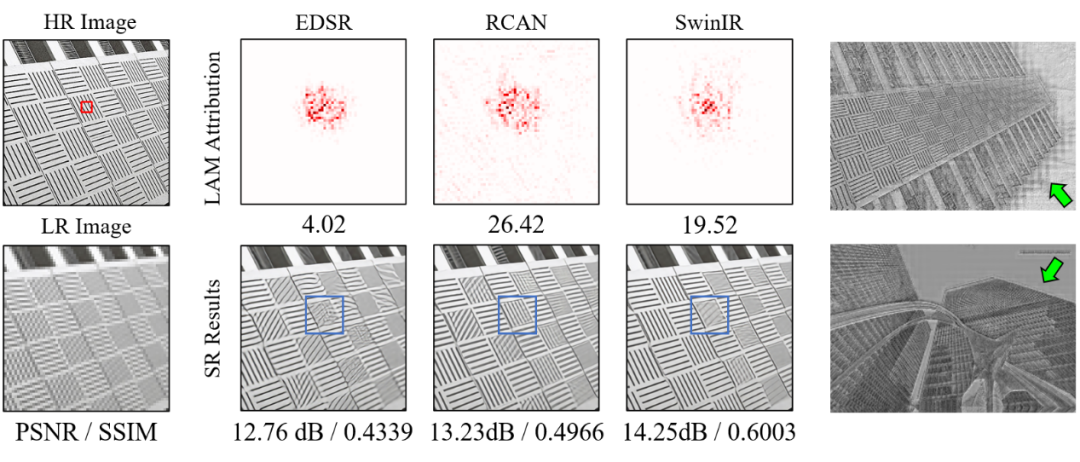
本文首先对不同方法的LAM [4]结果进行了对比。LAM是一种为SR任务设计的归因方法,它能够显示模型在进行超分辨率重建的过程中哪些像素起到了作用。如下图2(a)所示,LAM图中红色标记点表示:模型在重建左上图红框标记块时,对重建结果会产生影响的像素(LAM结果下的值为DI值[4],它可以定量地反映被利用像素的范围。DI值越大,表示重建时利用的像素范围越大)。
一般来说,被利用像素的范围越大,重建的效果往往越好[4],该结论在对比基于CNN的方法EDSR与RCAN时可以得到明显体现。然而,当对比RCAN与基于Transformer的SwinIR方法时,却出现了结论相反的现象。
SwinIR取得了更高的PSNR/SSIM,但相比RCAN并没有使用更大范围的像素信息,并且由于其有限的信息使用范围,在蓝色框区域恢复出了错误的纹理。这与以往普遍认为Transformer结构是通过更好地利用long-range信息来取得性能优势的直觉是相悖的。
图2. (a) 不同网络结构的LAM结果对比;(b)SwinIR网络产生的块效应除此之外,本文发现在SwinIR网络前几层产生的中间特征会出现明显的块状效应。这是由于模型在计算自注意力时的窗口划分导致的,因此本文认为现有结构进行跨窗口信息交互的方式也应该被改进。
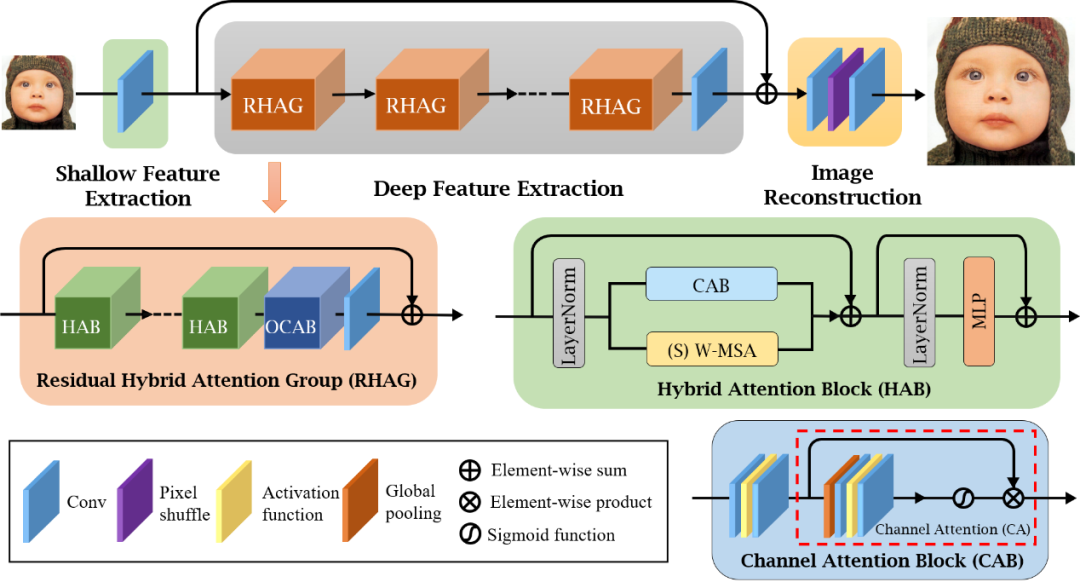
HAT的整体架构采用了与SwinIR相似的Residual in Residual结构,如下图3所示。主要的不同之处在于混合注意力模块(Hybrid Attention Block, HAB)与重叠的交叉注意力模块(Overlapping Cross-Attention Block, OCAB)的设计。
其中对于HAB,本文采用了并联的方式来结合通道注意力和自注意力。通道注意力能够利用全局信息;自注意力具有强大的表征能力。HAB模块的目的在于能够同时结合这两者的优势。
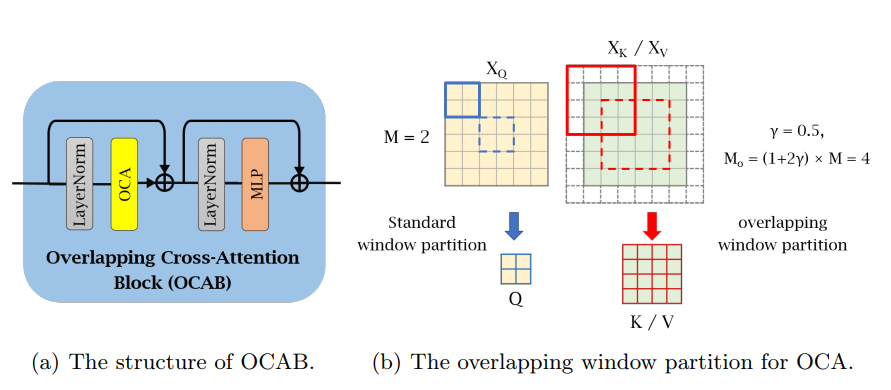
对于OCAB的设计,本文使用了一种重叠的窗口划分机制,如下图4所示。
相对于原始基于窗口的self-attention中Q、K和V来自于同一个窗口特征,OCA中的K/V来自更大的窗口特征,这允许attention能够被跨窗口地计算,以增强相邻窗口间信息的交互。
本文提出了一种直接使用相同的任务,但是使用更大的数据集(比如ImageNet)进行预训练的策略。
相比于之前用于超分任务的预训练方案,该策略更简单,但却能带来更多的性能增益。实验结果后面给出。
直接增加计算self-attention的窗口尺寸可以使模型能够利用更多的像素,并得到显著的性能提升。
表1和图5给出了对于不同窗口尺寸的定量和定性比较,可以看到16窗口尺寸有明显提升,HAT使用窗口尺寸16作为默认设置。
本文提供了消融实验来验证CAB和OCAB的影响,定量和定性分析结果如下表2和图6所示。
可以看到文中所提的两个模块在定量指标上均带来了不小的提升,在LAM和视觉效果上相对于Baseline也具有明显改善。
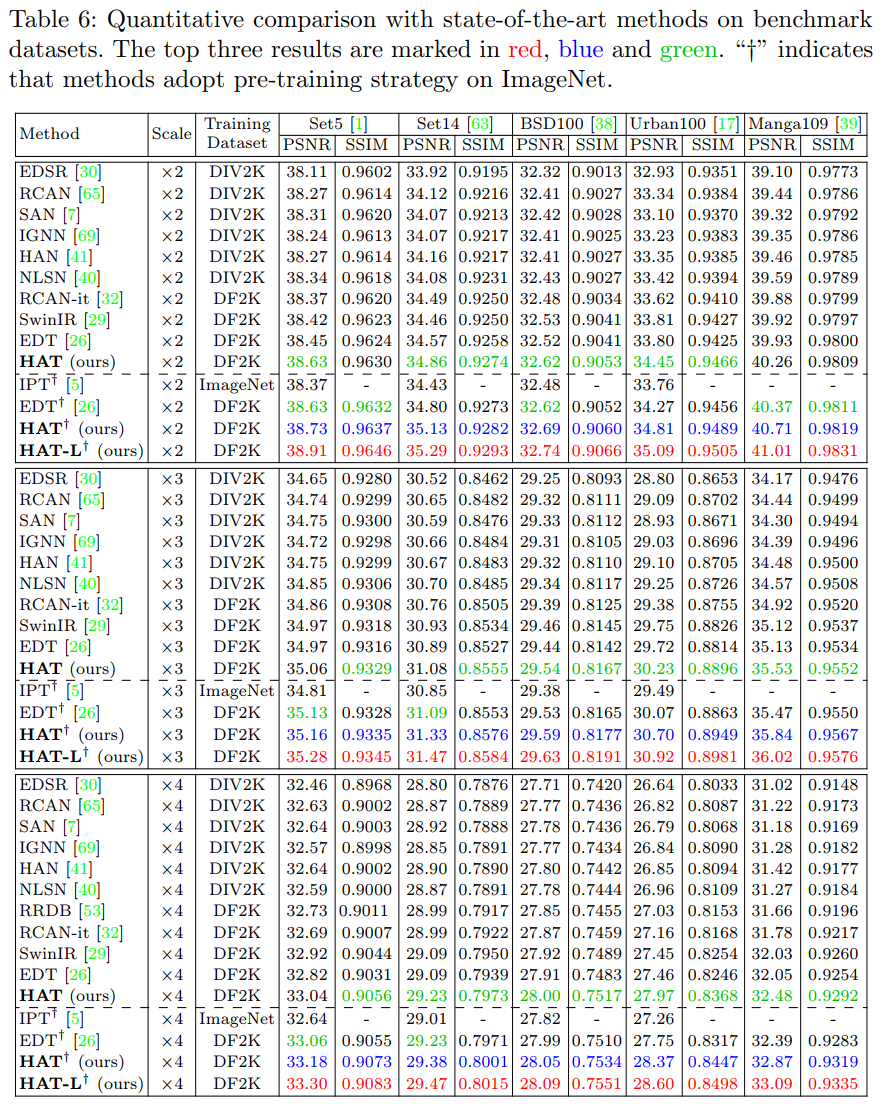
在基准数据集上进行定量对比实验的结果如下表6所示。
从定量指标上看,没有使用ImageNet预训练策略的HAT的性能已经明显超越SwinIR,甚至在很多情况下超越了经过ImageNet预训练的EDT。
使用了ImageNet预训练的HAT则更是大幅超越了SwinIR与EDT的性能,在2倍超分的Urban100数据集上,超越SwinIR 1dB。
更大容量的模型HAT-L带来了更大的性能提升,最高在2倍超分的Urban100数据集上超越SwinIR达1.28dB,超越EDT达0.85dB。
视觉效果对比如下图7所示。可以看出HAT能够恢复更多更清晰的细节,由于对于重复纹理较多的情况,HAT具有显著优势。在文字的恢复上,HAT相比其他方法也能够恢复出更清晰的文字边缘。本文还提供了HAT与SwinIR的LAM对比,如下图8所示。可以看出HAT能够明显使用更多的像素进行超分辨率重建,并因此取得了更好的重建效果。
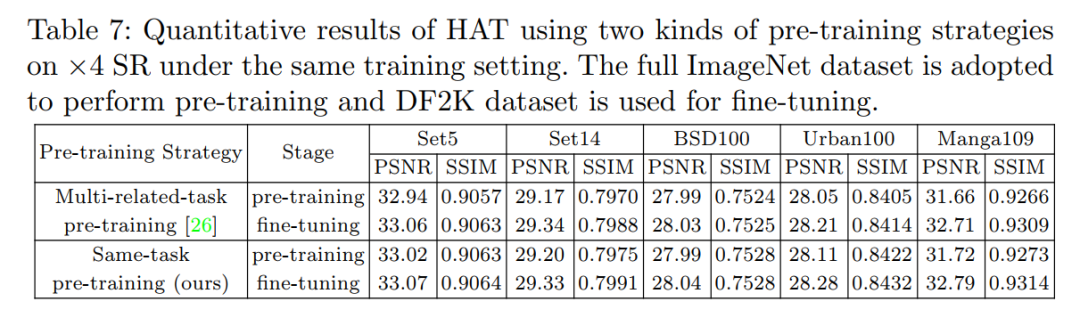
本文对于不同的预训练策略进行了对比,如下表7所示。相对于EDT [3]提出使用相关任务进行预训练的策略,本文提出的使用相同任务进行预训练的策略无论是在预训练阶段还是微调后的结果,性能都要更优。
在结构上,本文设计的HAT结合了通道注意力与自注意力,在以往Transformer结构的基础上进一步提升了模型利用输入信息的范围。同时设计了一个重叠交叉注意力模块,对Swin结构利用跨窗口信息的能力进行了有效增强。
在预训练策略上,本文提出的在相同任务上做预训练的方法,使得模型的性能进一步增强。
HAT大幅超越了当前超分方法的性能,这表明该任务或许远没有达到上限,可能依然还有很大的探索空间。
[1] Chen, H., Wang, Y., Guo, T., Xu, C., Deng, Y., Liu, Z., Ma, S., Xu, C., Xu, C., Gao, W.: Pre-trained image processing transformer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12299–12310 (2021)[2] Liang, J., Cao, J., Sun, G., Zhang, K., Van Gool, L., Timofte, R.: Swinir: Image restoration using swin transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, pp. 1833-1844 (2021)[3] Li, W., Lu, X., Lu, J., Zhang, X., Jia, J.: On efficient transformer and image pre-training for low-level vision. arXiv preprint, arXiv:2112.10175 (2021)[4] Gu, J., Dong, C.: Interpreting super-resolution networks with local attribution maps. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9199–9208 (2021)